
GD参考:
https://blog.csdn.net/CharlieLincy/article/details/70767791
SGD参考:
https://blog.csdn.net/CharlieLincy/article/details/71082147
关于SGD,博主的第二个问题。
GD 代码:

SGD代码:
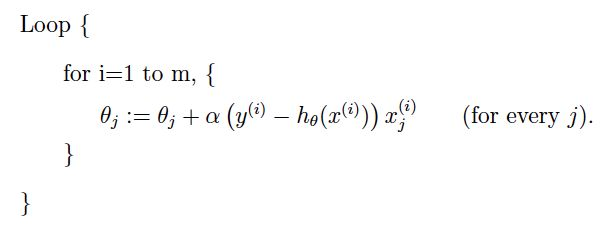
mini-batch代码:
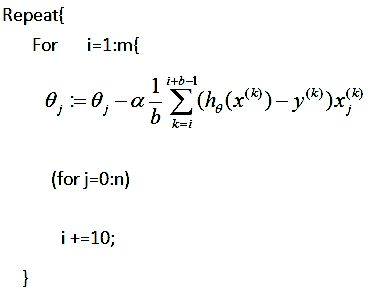
一直不明白SGD和GD相比优势到底在哪。看代码每次迭代两个算法都要遍历一次数据集。没啥区别。
然而。区别就在同样是一次迭代,遍历一次数据集,SGD更新了m次参数,GD只更新了一次。
关于这种随机样本更新的原理,以及SGD自动逃避鞍点的优点,有待进一步研究。
论文待看:Optimization methods for large-scale machine learning.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号