
《构建之法》——结对编程
| 作业要求地址 | <作业内容的链接> |
|---|---|
| GitHub项目地址 | WordCount |
| 结对伙伴的博客 | HisBlog |
## 1.PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 20 | 20 |
| · Estimate | · 估计这个任务需要多少时间 | 970 | 1050 |
| Development | 开发 | 920 | 1000 |
| · Analysis | · 需求分析 (包括学习新技术) | 50 | 50 |
| · Design Spec | · 生成设计文档 | 20 | 20 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 30 | 30 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 20 | 20 |
| · Design | · 具体设计 | 20 | 20 |
| · Coding | · 具体编码 | 720 | 800 |
| · Code Review | · 代码复审 | 30 | 30 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 30 | 30 |
| Reporting | 报告 | 50 | 50 |
| · Test Report | · 测试报告 | 20 | 20 |
| · Size Measurement | · 计算工作量 | 10 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 20 | 20 |
| 合计 | 990 | 1070 |
## 2.代码设计思路及接口设计
项目基本的功能有四个:统计文件的字符数、统计文件的单词总数、统计文件的有效行数、统计文件中各单词的出现次数。
第一步,要解决读取文件的问题,查阅资料后我们使用StreamReader来完成txt文件的读取。在这个过程中我们同时发现ReadLine()能完成逐行的读取,因此使用一个while循环就能直接把有效行数统计出来。
第二步,统计文件的字符数,经查阅我们发现使用 Regex.Matches(text, @"\w").Count;能计算出英文和数字的字符数,由于一个文件(如英文文章)里可能还有别的标点符号,因此类似的使用这个函数也将其他的标点符号匹配上进行Count计算,最后相加求出字符总数。
第三步,统计文件的单词总数,由于题目给的约束条件比较多,使用正则表达式能很好的解决这个问题,我们写出了符合题目要求的表达式来表示单词,从而通过叠加来求出单词总数。
第四步,统计文件中各单词的出现次数,这个问题我们分了两步来解决,首先要将文本内容进行分割,凡是遇到标点符号和空格、回车的地方,就进行中断,从而切割出一个一个单词,经查阅,使用Split和Trim能完成分割操作。分割之后根据正则表达式将符合条件的单词加入List集合中,使用ContainsKey统计所有单词及其词频。
接下来就是将频率最高的单词优先输出,对于这样的排序问题,也是查了很久的资料发现Dictionary能完成对次数降序的操作,而且还能按字典顺序进行排序,因此结合着数组的使用,完成了排序的功能。
项目的新增功能:词组的统计、自定义输出。
词组的统计基于单词总数统计的功能进行修改,经过分析,对于长度为m的词组,含有n个单词的文本总共可以写出n-m+1个词组。使用两个for循环,即可打印所有的词组。自定义输出涉及到了Main函数的参数args,这个问题也很好解决。
基于以上分析,我们一共设计了3个类,1个基础功能类和1个新增功能类,9个功能函数,具体如下图: 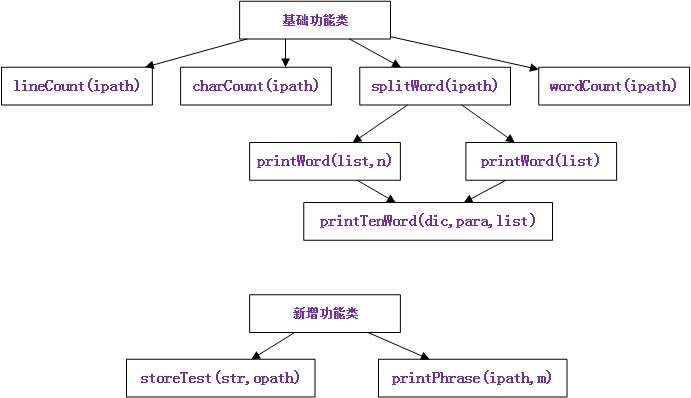
**基础功能函数的流程图:** 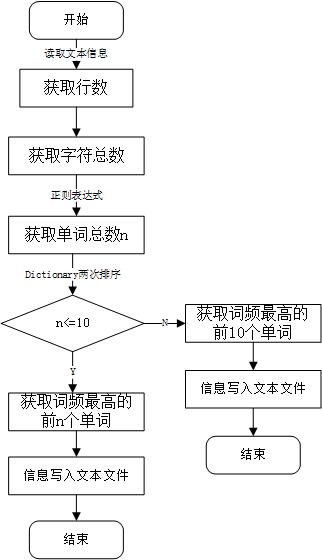
新增功能函数的流程图:
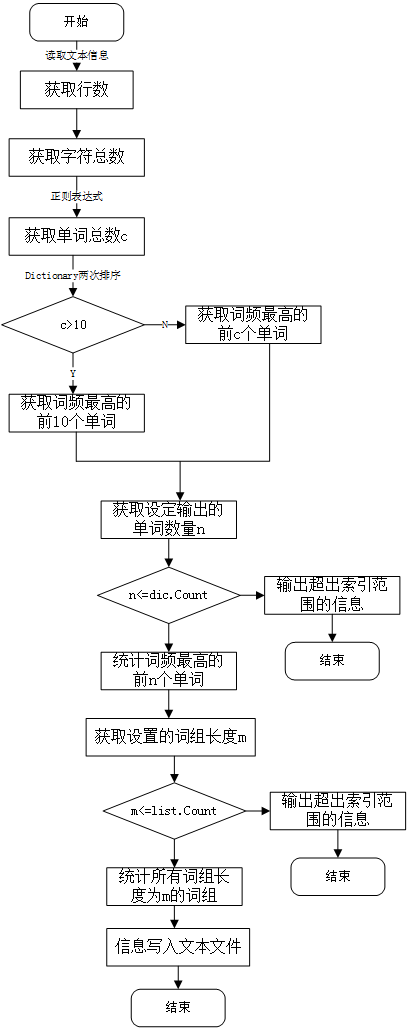
**Design By Contract(契约式设计)**
契约式设计就是按照某种规定对一些数据等做出约定,如果超出约定,程序将不再运行,例如要求输入的参数必须满足某种条件。本项目对n和m做出约定,虽然代码没有写的很完整,(当超出索引后直接结束程序而不是让用户再次输入),但是还是符合了基本原则。
Information Hiding(信息隐藏)
信息隐藏指在设计和确定模块时,使得一个模块内包含的特定信息(过程或数据),对于不需要这些信息的其他模块来说,是不可访问的。我的理解是在方法或类中声明private修饰符的变量,本项目中对opath(即输出路径)采用了信息隐藏,使用在两个类中get和set方法来引用该值。
Interface Design(界面设计)
界面设计我们并没有做GUI,但是实现了在cmd命令行中进行特定操作的功能。
Loose Coupling(松耦合)
开发语言上,想让对象与对象间松耦合,通过增加抽象类(Abstract Class)或者接口来做到。我们采用了多个类,特别是将基础功能和新增功能进行分成两个类,使代码的耦合度有一定的降低。
3.代码复审
- 我们是相互检查对方编写的代码,将代码写的不规范的地方,以及可能出现异常报错的地方进行修改。比如说他习惯将变量名全部写成大写:

代码可读性较差,后来均全部修改过来。
- 在cmd运行时一开始一直报错,说路径有问题,经过多次检查发现命令行默认的文件读取和写入路径都在C盘User的目录下(如图):
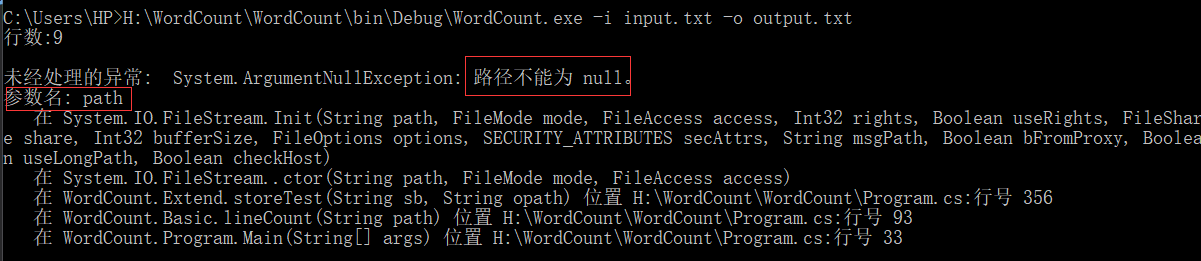

这一步花了大量的时间去修改,着实不容易呀。
附上基础功能的部分代码
//统计行数
public int lineCount(string path)
{
int line = 0;
string text;
StreamReader sR = new StreamReader(path, Encoding.UTF8);
while ((text = sR.ReadLine()) != null)
{
line++;
}
sR.Close();
Console.WriteLine("================基础功能================");
mycount2.storeTest("================基础功能================",opath);
Console.WriteLine("行数:" + line);
mycount2.storeTest("行数:" + line,opath);
return line;
}
//统计字符总数
public int charCount(string path)
{
int chars = 0;
string text;
StreamReader sR = new StreamReader(path, Encoding.UTF8);
while ((text = sR.ReadLine()) != null)
{
chars += Regex.Matches(text, @"\w").Count;//匹配字母,数字,_
chars += Regex.Matches(text, @"\s").Count;//匹配空格,水平制表符
chars += Regex.Matches(text, @"\n").Count;//匹配换行符
chars += Regex.Matches(text, @"\?").Count;//匹配?
chars += Regex.Matches(text, @"\,").Count;//匹配逗号
chars += Regex.Matches(text, @"\.").Count;//匹配.
chars += Regex.Matches(text, @"\!").Count;//匹配!
chars += Regex.Matches(text, @"\-").Count;//匹配-
chars += Regex.Matches(text, @"\(").Count;//匹配(
chars += Regex.Matches(text, @"\)").Count;//匹配)
}
sR.Close();
Console.WriteLine("字符总数:" + chars);
mycount2.storeTest("字符总数:" + chars, opath);
return chars;
}
//统计单词总数
public int wordCount(string path)
{
int words = 0;
string wordtype = @"[a-zA-Z]{4,}[a-zA-Z0-9]*";
string text;
StreamReader sR = new StreamReader(path, Encoding.UTF8);
while ((text = sR.ReadLine()) != null)
{
words += Regex.Matches(text, wordtype).Count;
}
sR.Close();
Console.WriteLine("单词总数:" + words);
mycount2.storeTest("单词总数:" + words, opath);
return words;
}
## 4.性能分析 我们测试了**《茶花女》英文版的前4章**文本内容,字符总数大概在**48000左右**,性能分析结果如下:  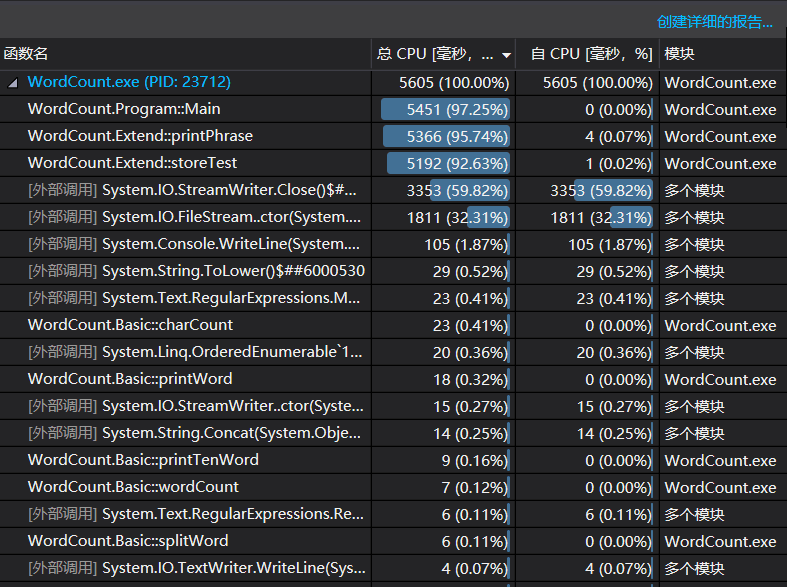
StreamWriter.Close()部分的CPU占用率高达59%,后来虽然想完善,但是StreamWriter部分确实是我们的难点,所以后来这一部分还是沿用了原来的代码。
5.单元测试
我们对3个文本文件进行了测试,测试路径如图:
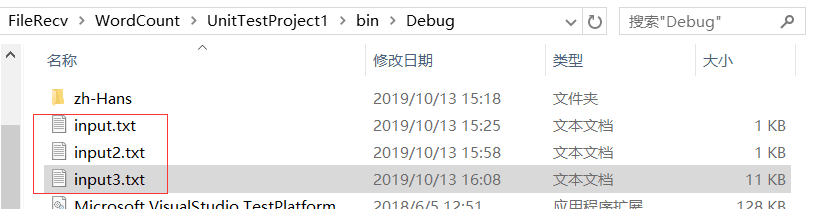
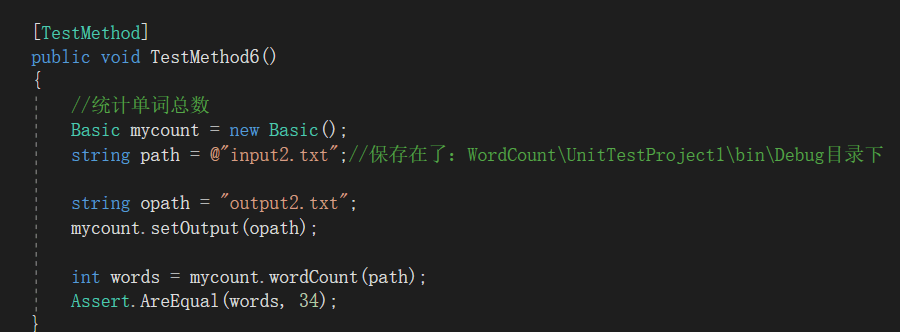
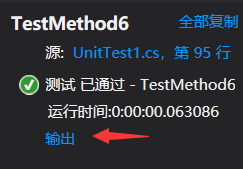
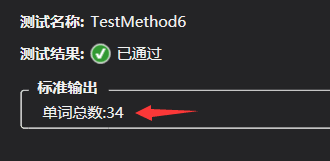
附上部分功能的单元测试截图,对单词总数进行测试,input2.txt写的比较复杂,考虑了各种各样的情况,最终得出了正确的结果:

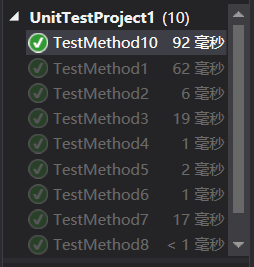
6.异常处理
-
我们首先考虑的是传入的参数m和n可能会报越界异常,因此在异常情况下直接输出错误信息,函数直接返回:


-
其次,在输入参数时可能会出现漏输的情况,这时也要对代码进行处理,处理结果如图:
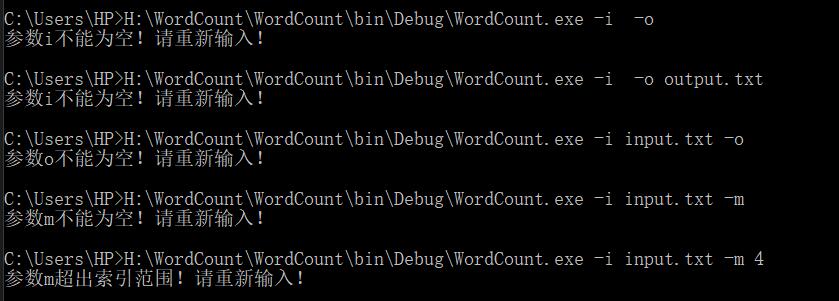
### 异常处理后的完整结果展示 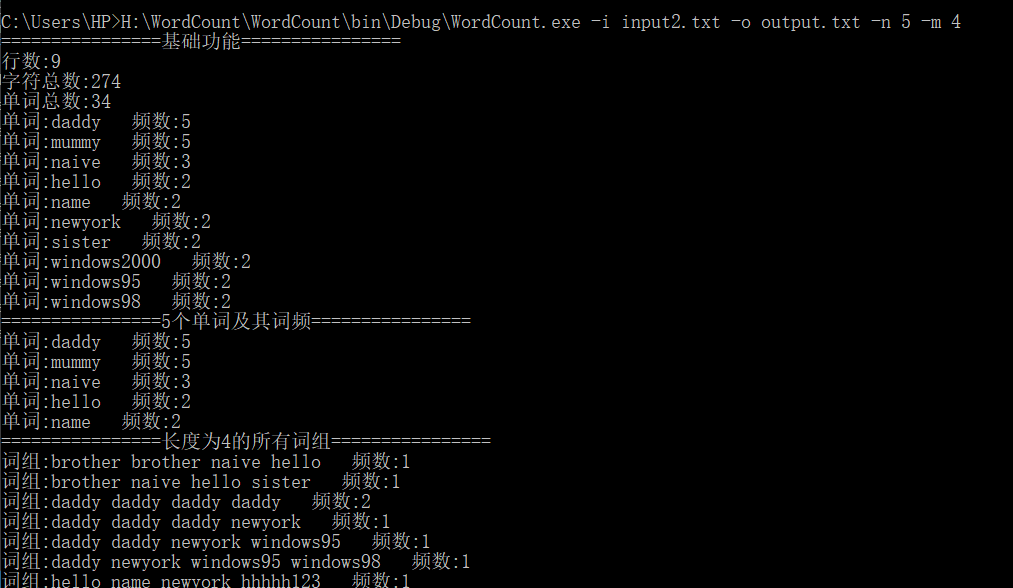
7.结对编程
一开始是我让他看这个项目他才开始看的,解决的思路其实很明了,很快就能理顺了,只是对C#不熟很多函数不知道怎么用,或者是忘了怎么用。中途因为某个部分解决思路不一样起冲突了,不过因为时间紧迫也没有再犟下去,后面慢慢查资料也就一点一点地完善了功能。

8.心得
个人感觉结对编程真的非常靠双方的配合度和默契度,虽然结对编程的表面含义是一方编程,一方审查,但是假如两个人没有同样的投入程度,完成的效率会很低。由于前期没有做好充分的讨论,后面在完成部分功能时,我们俩因意见不合发生争执,所以从这点上来说,这次的两人合作并非1+1>2。但是结对的好处就是双方都可以提出一些有用的想法,这对于编程能力不太强的人来说还是很有帮助的。总之,两个责任感很强的人被分配到一起编程,效率肯定要比一个人编程高。

