

Java自动化审计(下篇)

本文是 i 春秋论坛作家「Wker」表哥分享的技术文章,文章旨在为大家提供更多的学习方法与技能技巧,文章仅供学习参考。
前期回顾
CodeQl的缺点
虽然CodeQl的优点非常多,但也存在一个比较明显的缺点:不能直接通过打包好的程序进行代码审计。
当你得到的只是一个jar包,那么会比较棘手,因为现在市面上的反编译程序的反编译结构都不太满意,在我个人的使用体验中感觉idea算是最完美的了,但是还可能存在一些反编译问题,比如语法错误,最终可能导致编译过程中CodeQl解析的不准确。
Wker_java_audit
为了弥补CodeQl不能够直接检索打包好的程序,所以笔者开发了Wker_java_audit,名字还没有想好,暂时先这样叫。
思路
1、解析jar包,因为能打包好的就是war或者是jar;
2、解析class文件结构;
3、反编译class文件,得到方法的语法树,当然其他类似注解,属性之类的都是需要获取的;
4、优化语法树执行流,其实就是将一些比较笨重的操作进行优化,类似于编译器的优化;
5、生成java代码,方便进行审计;
6、编写相应脚本,根据语法树查询危险的数据流向;
7、脚本中增加过滤,根据过滤函数进行剪枝。
整体思路大体可以分为上述的7步,也就是将反编译工具和CodeQl结合起来,做到可以实现自动化审计闭源代码的效果。
在这里我还是拿之前的靶场进行演示。
首先需要准备:
- 靶场
- Wker_java_audit
使用方法
java -jar DecompileDialog.jar运行起来,运行起来之后将会让你选择项目jar包,我们选择靶场的jar包,程序就会打开。
spring的项目在BOOT-INF\classes中能找到对应的class文件。
我们可以先对比一下反编译的效果。
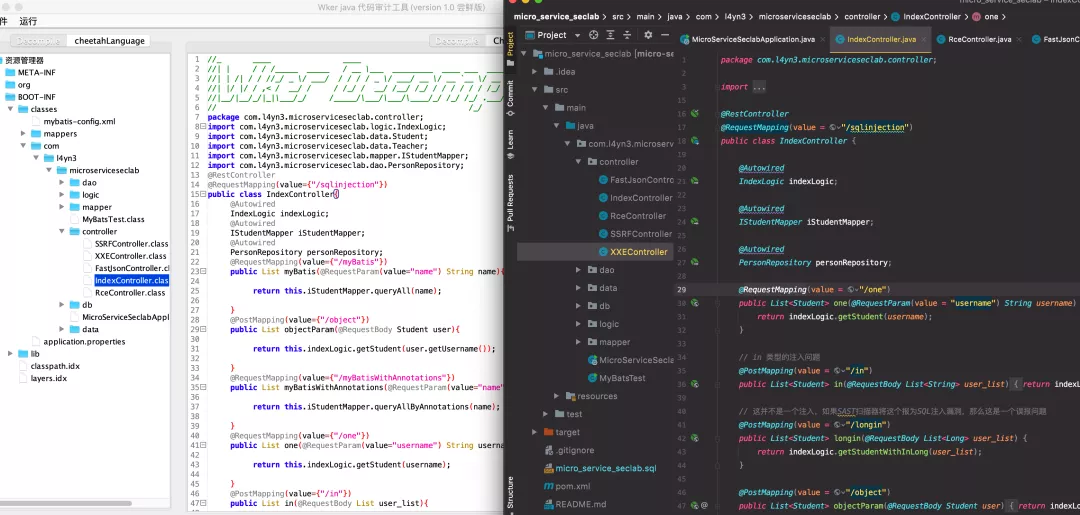
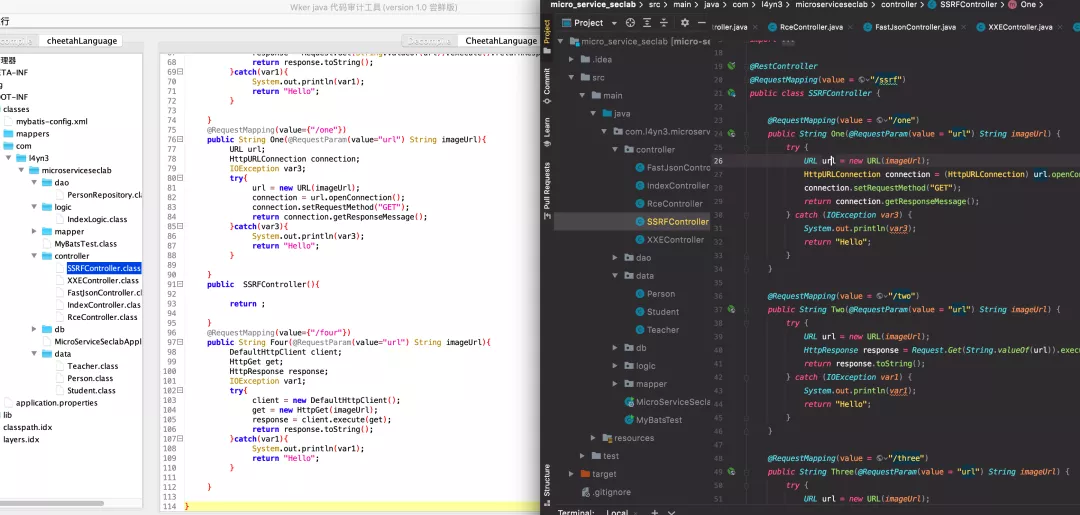
效果上的话还是比较相似的。
当然反编译这一块的内容笔者做的比较仔细,就不给大家完全展开看了,最重要的还是要分享思路解析。
CodeQl是通过类似于sql语句的方式进行检索的,而笔者还是沿用之前的cheetah,进行更有逻辑的结构分析。
给大家举一个例子,是针对于sql注入的,这里先看一下执行的结果,选择cheetahLangue标签,挑选script下的sqlI.cheetah然后执行。
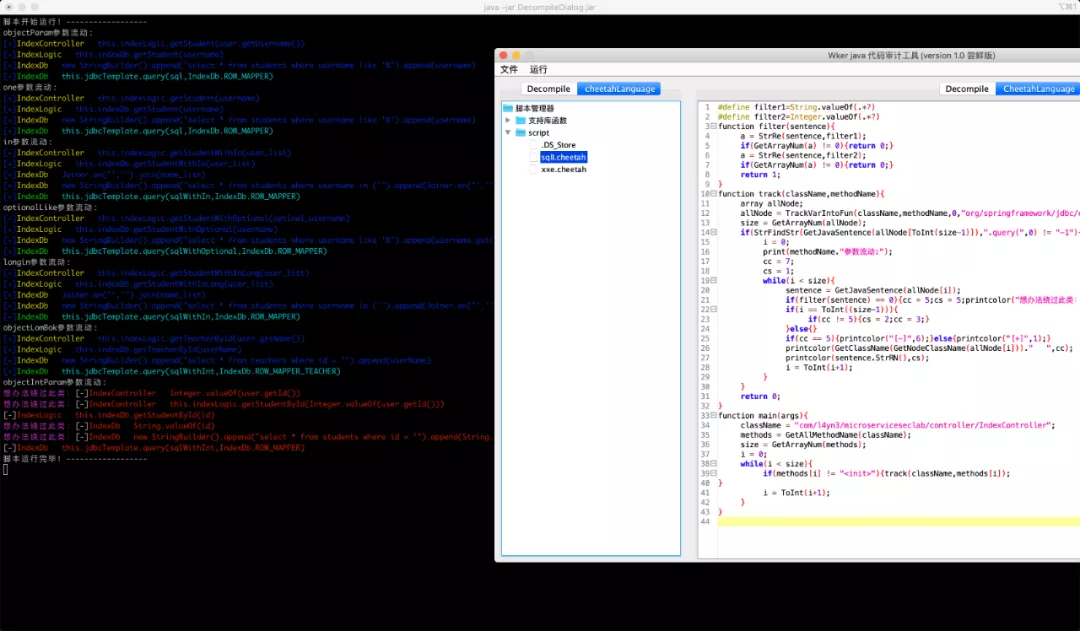
可以看到,最终打印出了所有的流程,并且也进行了颜色区分和信息处理。
sqlI.cheetah:
#define filter1=String.valueOf(.*?)
#define filter2=Integer.valueOf(.*?)
function filter(sentence){
a = StrRe(sentence,filter1);
if(GetArrayNum(a) != 0){return 0;}
a = StrRe(sentence,filter2);
if(GetArrayNum(a) != 0){return 0;}
return 1;
}
function track(className,methodName){
array allNode;
allNode = TrackVarIntoFun(className,methodName,0,"org/springframework/jdbc/core/JdbcTemplate","query",0);
size = GetArrayNum(allNode);
if(StrFindStr(GetJavaSentence(allNode[ToInt(size-1)]),".query(",0) != "-1"){
i = 0;
print(methodName."参数流动:");
cc = 7;
cs = 1;
while(i < size){
sentence = GetJavaSentence(allNode[i]);
if(filter(sentence) == 0){cc = 5;cs = 5;printcolor("想办法绕过此类:",4);}
if(i == ToInt((size-1))){
if(cc != 5){cs = 2;cc = 3;}
}else{}
if(cc == 5){printcolor("[-]",6);}else{printcolor("[+]",1);}
printcolor(GetClassName(GetNodeClassName(allNode[i]))." ",cc);
printcolor(sentence.StrRN(),cs);
i = ToInt(i+1);
}
}
return 0;
}
function main(args){
className = "com/l4yn3/microserviceseclab/controller/IndexController";
methods = GetAllMethodName(className);
size = GetArrayNum(methods);
i = 0;
while(i < size){
if(methods[i] != "<init>"){track(className,methods[i]);
}
i = ToInt(i+1);
}
}
脚本编写
首先在main函数中指定我们要检索的class名称,通过支持库中的GetAllMethodName得到所有的方法名称,当然<init>和<cinit>这两个是构造方法和静态代码块的内容,就不看了。如果不是这两个函数,就调用track函数进行分析,track中调用支持库提供的TrackVarIntoFun。
TrackVarIntoFun:
参数1:起始类 参数2:起始方法 参数3:起始方法参数下标 参数4:目标方法的类 参数5:目标方法:参数6:目标方法的参数下标 返回值:执行流node数组
通过调用这个函数得到执行流,返回的执行流中包含着class名称和对应的Node,这个Node并不是一个字符串而是一个AST,这个AST通过GetJavaSentence方法可以得到对应的java语句,通过GetNodeClassName可以得到类名称。
下面就是挨个输出,只是输出的时候进行了剪枝,当然这种剪枝并不是完全正确的。
这里的剪枝是通过正则匹配Integer.value进行剪枝,后期可以自行添加。
如果在路径中存在一处sanitizers,则被阻断,就用红色的进行输出。
如果整个路径都没有过滤函数,那最后的sink就用绿色打印出来,这样会比较直观。
整个脚本没有什么难点,底层的复杂逻辑已经实现了,但是肯定还是有一些不足的。
我们还可以测试一下里面的XXE漏洞。
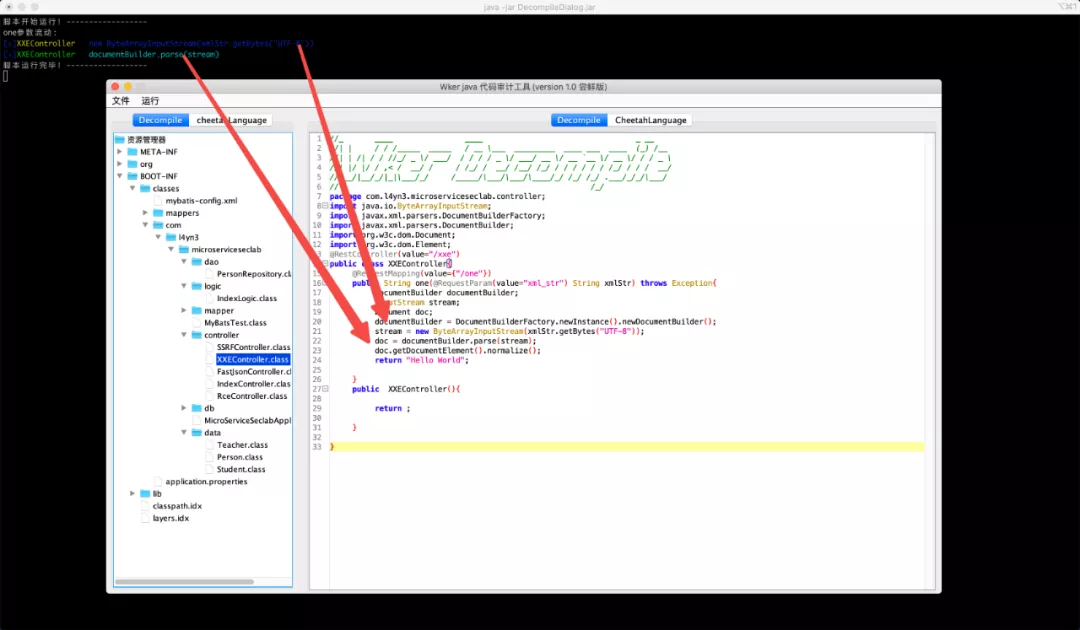
当然,脚本内容大相径庭,无非就是起始类和目标类有所更改。
TrackVarIntoFun(className,methodName,0,"javax/xml/parsers/DocumentBuilder","parse",0);
如果有兴趣,你也可以看spring的代码:
目前存在的一些缺陷,如果有反响的话,之后笔者会修复的。
1、or 拼接问题,目前看起来不美观;
2、new int[]{1,2,3} 类似语句解析成分块的问题;
3、目前只支持追踪参数流向,无法满足所有情况。
以上为今天分享的内容,小伙伴们看懂了吗?

