PTA basic 1095 解码PAT准考证 (25 分) c++语言实现(g++)
PAT 准考证号由 4 部分组成:
- 第 1 位是级别,即
T代表顶级;A代表甲级;B代表乙级; - 第 2~4 位是考场编号,范围从 101 到 999;
- 第 5~10 位是考试日期,格式为年、月、日顺次各占 2 位;
- 最后 11~13 位是考生编号,范围从 000 到 999。
现给定一系列考生的准考证号和他们的成绩,请你按照要求输出各种统计信息。
输入格式:
输入首先在一行中给出两个正整数 N(≤104)和 M(≤100),分别为考生人数和统计要求的个数。
接下来 N 行,每行给出一个考生的准考证号和其分数(在区间 [0,100] 内的整数),其间以空格分隔。
考生信息之后,再给出 M 行,每行给出一个统计要求,格式为:类型 指令,其中
类型为 1 表示要求按分数非升序输出某个指定级别的考生的成绩,对应的指令则给出代表指定级别的字母;类型为 2 表示要求将某指定考场的考生人数和总分统计输出,对应的指令则给出指定考场的编号;类型为 3 表示要求将某指定日期的考生人数分考场统计输出,对应的指令则给出指定日期,格式与准考证上日期相同。
输出格式:
对每项统计要求,首先在一行中输出 Case #: 要求,其中 # 是该项要求的编号,从 1 开始;要求 即复制输入给出的要求。随后输出相应的统计结果:
类型为 1 的指令,输出格式与输入的考生信息格式相同,即准考证号 成绩。对于分数并列的考生,按其准考证号的字典序递增输出(题目保证无重复准考证号);类型为 2 的指令,按人数 总分的格式输出;类型为 3 的指令,输出按人数非递增顺序,格式为考场编号 总人数。若人数并列则按考场编号递增顺序输出。
如果查询结果为空,则输出 NA。
输入样例:
8 4
B123180908127 99
B102180908003 86
A112180318002 98
T107150310127 62
A107180908108 100
T123180908010 78
B112160918035 88
A107180908021 98
1 A
2 107
3 180908
2 999输出样例:
Case 1: 1 A
A107180908108 100
A107180908021 98
A112180318002 98
Case 2: 2 107
3 260
Case 3: 3 180908
107 2
123 2
102 1
Case 4: 2 999
NA
AC代码 相较于第一次提交 主要修改了三个地方
1.测试点1 2 错误的原因, 在提交查询 类型 1 指令 的时候, 应该判定T A B三个种类里是否有数据 ,而不是查询"T" "A" "B"三个关键字是否存在,(肯定存在啊 自己建的key值 )
把tabListIt=tabList.find(key值); 改成 tabList[key值].size()!=0; 即 要查询的key值中有数据存在 否则输出NA
2.测试点3 4 超时问题, 关键核心点 输出信息中一共有两个数组循环输出 第一个是查询了 指令1 按序输出 查询" T" "A" "B"的表内考生信息
消耗时间主要是两个方面,一方面是按照要求排序, 另一方面是输出信息
(1)确认是否要排序
对于如何处理排序更加节省时间,排序过程无非都是sort, 重点在于 排序 这个事情可以发生在 确定有信息要输出的时候才进行, 也就是输入信息为指令1 或指令3 且 查询的内容存在
当不需要输出排序信息时, 不排序可以节省时间
(2) 已知printf比cout更有时间优势, 当输出语句只有一句的时候,性能相当 且cout输出更方便,
但是数组循环的时候cout就没有了优势,需要使用printf来节省时间, 所以只需要将循环输出语句中的cout改成printf就可以节省大量时间 ,这个经过这两步处理, 超时问题应该解决
注: 当然 按照这个思路,完全可以先将所有信息录入,当判定指令类型后,再进行数据筛选和排序,时间上应该会更优
柳婼blog https://blog.csdn.net/liuchuo/article/details/84972869
3.超时问题解决后,测试点3 4依然显示答案错误,
具体原因我并不清楚,但是我修改了switch中的语法, 把case i: 后的语句包裹在了语法块中,块后只有break;语句, 尽量避免了错误语法,修改后测试点3 4 通过,但是我不知道具体原因
4.一个小的事情, 可以把局域变量放在局域块中声明, 这样当不需要这些变量的时候, 也就不需要声明, 可以节省一点时间
5.unsorted_map和map的区别
unsorted_map字面意思就是不排序的map, 内部实现是由hash值存储的hash表, key键-value值对应, 快速检索
map是由红黑树实现的一种容器, 内部是有序的, 因此时间消耗也更多
如果只是使用map存储一个(key键-value值)映射的数据, 使用unsorted_map 这种hashtable实现的容器, 理应更有时间优势
注: unsorted_map 使用时需要引入<unsorted_map>包
6.在使用unsorted_map或者map存储数据, 但又需要按照需求排序时
需要使用迭代器(iterator )
用map<>::it; it->first; it->second;的方式
依次取出key键-value值对, it->first就是key键, it->second 就是value值
取出数据依次推入vector容器, 然后再进行排序, 输出
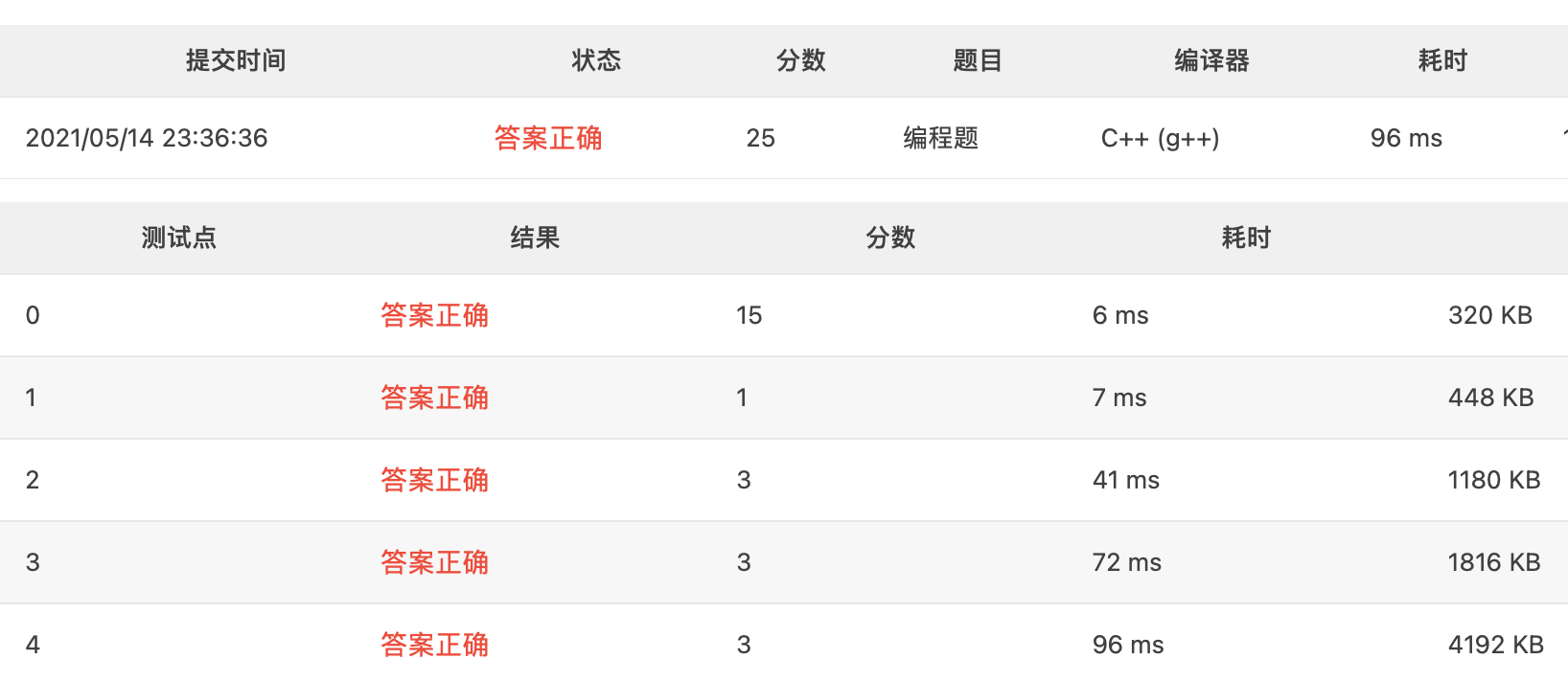
放一个通过的截图, 耗时符合要求
在修改2.(1)之前会超时,修改2.(1)后超时问题解决, 耗时大概140ms
修改2.(2)后,耗时由140ms到90ms左右
修改3后,测试点都通过了
附一个测试点1的测试用例
1 6
T101000101000 0
3 000101
2 101
1 T
1 A
1 B
3 180908
AC代码
//收集 分类 筛选 //首先根据要输出的信息 收录的内容应该有 //1.各类型(T A B)的总排名 分数降序 字母序升序 //2.不分日期 不分类型 记录考场的总分数和人数 //3.不分类型 不论分数 记录考场 只记录日期 人数 //所以使用一个两个考场类型 以考场号为key值 包含总分数 总人数 //另一个以日期为key值 包含考场号和对应人数 #include <iostream> #include <string> #include <vector> #include <map> #include <algorithm> #include <math.h> #include <unordered_map> using namespace std; class nameAndNum{ public: string name; int num; nameAndNum()=default; nameAndNum(string s_,int n_):name{s_},num{n_}{} }; bool compare (nameAndNum &l, nameAndNum &r){ if(l.num==r.num){ return l.name<r.name; }else{ return l.num>r.num; } } int main(){ int n,m,tempscour; string tempclass,tempdate,tempPlace; string str; cin >> n >> m; map< string,vector<nameAndNum>> tabList{ {"T",vector<nameAndNum>{}}, {"A",vector<nameAndNum>{}}, {"B",vector<nameAndNum>{}} }; map< string, vector<int>> places;//考场号对应考场信息映射 考场信息为总分数和总人数的数组 第一值为总分数 第二个值为总人数 unordered_map<string, unordered_map<string, int>> urm_dates;//日期和考场号考场人数的映射,使用不排序map map< string, vector<int>>::iterator mapPIt;//地点map迭代器,用于检查地点key值是否存在 for(int i=0;i<n;i++){//处理考生信息 cin >> str >>tempscour; //截取字符串 分别代表 类别 地点 时间 tempclass=str.substr(0,1); tempPlace=str.substr(1,3); tempdate=str.substr(4,6); //按t a b 分类推入学生信息 tabList[tempclass].push_back(nameAndNum{str,tempscour});// //如果没有地点信息 则生成一个地点的信息数组 和key绑定 第一个值为总分 第二个值为人数 mapPIt=places.find(tempPlace); if(mapPIt==places.end()){ places[tempPlace]=vector<int>{0,0}; } //累加某个地点的总分 和人数 places[tempPlace][0]+=tempscour; places[tempPlace][1]++; //某个时间某个地点的人数统计 urm_dates[tempdate][tempPlace]++; } for(int i=0;i<m;i++){//处理数据请求 int ins{1}; string ask; cin >> ins >> ask; switch (ins) { case 1:{ printf("Case %d: %d ",i+1,ins); for(auto i:ask){ printf("%c",i); } printf("\n"); if(tabList[ask].size()!=0){ map< string, vector<nameAndNum>>::iterator tabListIt;//TAB表迭代器 for(tabListIt=tabList.begin();tabListIt!=tabList.end();tabListIt++){ sort(tabList[tabListIt->first].begin(),tabList[tabListIt->first].end(),compare); } for(int j=0;j<tabList[ask].size();j++){ for(auto i : tabList[ask][j].name){ printf("%c",i); } printf(" %d\n",tabList[ask][j].num); } }else{ printf("NA\n"); } } break; case 2:{ printf("Case %d: %d ",i+1,ins); for(auto i:ask){ printf("%c",i); } printf("\n"); mapPIt=places.find(ask); if(mapPIt!=places.end()){ cout <<places[ask][1] <<" "<<places[ask][0]<<endl; }else{ printf("NA\n"); }} break; case 3:{ printf("Case %d: %d ",i+1,ins); for(auto i:ask){ printf("%c",i); } printf("\n"); unordered_map<string, unordered_map<string, int>>::iterator urm_datesIt;//不排序mapkey值为"日期"的地点map的迭代器 urm_datesIt=urm_dates.find(ask); if(urm_datesIt!=urm_dates.end()){ vector<nameAndNum> placesList; map<string ,int> placemap; unordered_map<string, int>::iterator urmIt;//不排序map的迭代器 //遍历元素取出放入容器中准备排序 然后输出 for(urmIt=urm_dates[ask].begin();urmIt!=urm_dates[ask].end();urmIt++){ placesList.push_back(nameAndNum{urmIt->first,urmIt->second}); } sort(placesList.begin(),placesList.end(),compare); for(int i=0;i<placesList.size();i++){ for(auto i : placesList[i].name){ printf("%c",i); } printf(" %d\n",placesList[i].num); } }else{ printf("NA\n"); } } break; default: break; } } return 0; }
//第一次提交 只有测试点0 通过了
//收集 分类 筛选 //首先根据要输出的信息 收录的内容应该有 //1.各类型(T A B)的总排名 分数降序 字母序升序 //2.不分日期 不分类型 记录考场的总分数和人数 //3.不分类型 不论分数 记录考场 只记录日期 人数 //所以使用一个两个考场类型 以考场号为key值 包含总分数 总人数 //另一个以日期为key值 包含考场号和对应人数 #include <iostream> #include <string> #include <vector> #include <map> #include <algorithm> #include <math.h> #include <unordered_map> using namespace std; class nameAndNum{ public: string name; int num; nameAndNum()=default; nameAndNum(string s_,int n_):name{s_},num{n_}{} }; bool compare (nameAndNum &l, nameAndNum &r){ if(l.num==r.num){ return l.name<r.name; }else{ return l.num>r.num; } } int main(){ int n,m,tempscour; string tempclass,tempdate,tempPlace; string str; cin >> n >> m; vector<nameAndNum> placesList; map<string ,int> placemap; map< string,vector<nameAndNum>> tabList{ {"T",vector<nameAndNum>{}}, {"A",vector<nameAndNum>{}}, {"B",vector<nameAndNum>{}} }; //dates 不同日期的考场信息 map< string, vector<int>> places;//考场号 对应 考场信息 映射 考场信息为总分数和总人数的数组 第一值为总分数 第二个值为总人数 unordered_map<string, unordered_map<string, int>> urm_dates; map< string, vector<nameAndNum>>::iterator tabListIt;//TAB表迭代器 unordered_map<string, int>::iterator urmIt;//不排序map的迭代器 map< string, vector<int>>::iterator mapPIt;//地点map迭代器 unordered_map<string, unordered_map<string, int>>::iterator urm_datesIt;//不排序mapkey值为"日期"的地点map的迭代器 // 日期 对应 考场信息数组的映射 考场信息数组中有每个考场在当前的考试人数 for(int i=0;i<n;i++){//处理考生信息 cin >> str >>tempscour; //截取字符串 分别代表 类别 地点 时间 tempclass=str.substr(0,1); tempPlace=str.substr(1,3); tempdate=str.substr(4,6); //按t a b 分类推入学生信息 tabList[tempclass].push_back(nameAndNum{str,tempscour});// //如果没有地点信息 则生成一个地点的信息数组 和key绑定 第一个值为总分 第二个值为人数 mapPIt=places.find(tempPlace); if(mapPIt==places.end()){ places[tempPlace]=vector<int>{0,0}; } //累加某个地点的总分 和人数 places[tempPlace][0]+=tempscour; places[tempPlace][1]++; //某个时间某个地点的人数统计 urm_dates[tempdate][tempPlace]++; } //1 3的数组内排序 for(tabListIt=tabList.begin();tabListIt!=tabList.end();tabListIt++){ sort(tabList[tabListIt->first].begin(),tabList[tabListIt->first].end(),compare); } for(int i=0;i<m;i++){//处理数据请求 int ins{1}; string ask; cin >> ins >> ask; switch (ins) { case 1: cout << "Case "<<i+1<<": "<<ins<<" "<<ask<<endl; tabListIt=tabList.find(ask); if(tabListIt!=tabList.end()){ for(int j=0;j<tabList[ask].size();j++){ cout << tabList[ask][j].name <<" " <<tabList[ask][j].num<<endl; } }else{ cout << "NA"<<endl; } break; case 2: cout << "Case "<<i+1<<": "<<ins<<" "<<ask<<endl; mapPIt=places.find(ask); if(mapPIt!=places.end()){ cout <<places[ask][1] <<" "<<places[ask][0]<<endl; }else{ cout << "NA" << endl; } break; case 3: cout << "Case "<<i+1<<": "<<ins<<" "<<ask<<endl; urm_datesIt=urm_dates.find(ask); if(urm_datesIt!=urm_dates.end()){ //遍历元素取出放入容器中准备排序 然后输出 for(urmIt=urm_dates[ask].begin();urmIt!=urm_dates[ask].end();urmIt++){ placesList.push_back(nameAndNum{urmIt->first,urmIt->second}); } sort(placesList.begin(),placesList.end(),compare); for(int i=0;i<placesList.size();i++){ cout << placesList[i].name << " "<< placesList[i].num<<endl; } }else{ cout << "NA"<<endl; } break; default: break; } } return 0; }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号