美团民宿数据爬取
1.美团民宿信息获取
# coding:utf8 import requests import random from lxml import etree import time # 提供ua信息的的包 # from uainfo import ua_list import pymysql class MeituanSpider(object): def __init__(self): self.url = 'https://minsu.dianping.com/chengdu/pn{}/?dateBegin=20221101&dateEnd=20221102' # 计数,请求一个页面的次数,初始值为1 self.mysql = pymysql.connect(host='localhost', database='tenders', port=3306, user='root', password='123456') self.cur = self.mysql.cursor() self.blog = 1 # 随机取一个UA # 发送请求 def get_html(self, url): # 在超时间内,对于失败页面尝试请求三次 if self.blog <= 3: try: data = {'dateBegin': '20221101', 'dateEnd': '20221102' } headers = {'Cookie': '', 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3928.4 Safari/537.36',} res = requests.get(url=url, headers=headers,data=data, timeout=3) html = res.text return html except Exception as e: print(e) self.blog += 1 self.get_html(url) # 解析提取数据 def parse_html(self, url): html = self.get_html(url) if html: time.sleep(1) p = etree.HTML(html) # 基准xpath表达式-30个房源节点对象列表 h_list = p.xpath('//div[@class="r-card-list v-stretch h-stretch"]/div[@class="r-card-list__item shrink-in-sm"]') # 所有列表节点对象 for h in h_list: title1 = h.xpath('.//div[@class="product-card__title"]/text()')[0] address1 = h.xpath('.//div[@class="mt-2"]/text()')[0] url1 = 'https://minsu.dianping.com' + h.xpath('.//a[@class="product-card-container"]/@href')[0] configuration1 = h.xpath('.//div[@class="product-card__type-detail"]/div[1]/text()')[0] price1= h.xpath('.//span[@class ="product-card__price__latest"]/text()')[0] collections1 = h.xpath('.//span[@class="product-fav-count"]/text()')[0] # result = requests.get(url=url1, headers=self.get_header()) # tree = etree.HTML(result.text) # print(tree) # time.sleep(1.0) # price = tree.xpath("//div[@class='price ']/span/text()")[0] data = { 'title': title1, 'urls': url1, 'address': address1, 'configuration': configuration1, 'collections': collections1, 'price': price1, 'unit': '元' } print(data) self.save_mysql(data) def save_mysql(self, data): # str_sql = "insert into ftx values(0, '{}', '{}');".format(data['first_category'],data['second_category']) str_sql = "insert into meituan values(0, '{}', '{}', '{}', '{}', '{}', '{}', '{}');".format( data['title'], data['urls'],data['address'], data['configuration'], data['collections'], data['price'], data['unit']) self.cur.execute(str_sql) self.mysql.commit() def __del__(self): self.cur.close() self.mysql.close() # 入口函数 def run(self): try: for i in range(1,4): url = self.url.format(i) print(i) self.parse_html(url) time.sleep(random.randint(3, 5)) # 每次抓取一页要初始化一次self.blog self.blog = 1 except Exception as e: print('发生错误', e) if __name__ == '__main__': spider = MeituanSpider() spider.run()
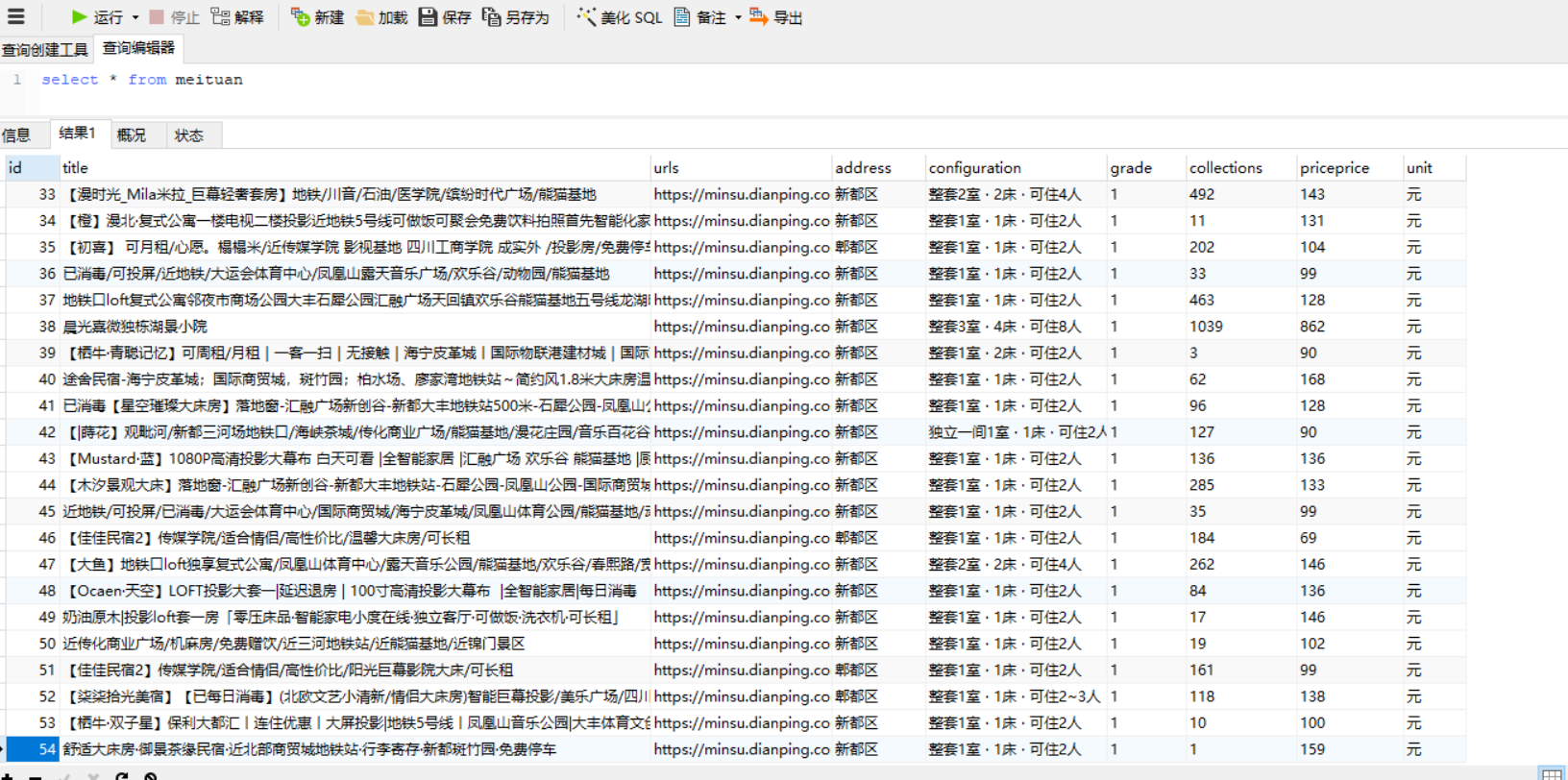
2.运行结果


 浙公网安备 33010602011771号
浙公网安备 33010602011771号