
用Python实现简单的HTTP服务器(1)--使用Firebug简单分析HTTP协议
2011-12-31 16:37 会被淹死的鱼 阅读(4448) 评论(0) 编辑 收藏 举报HTTP协议是超文本传输协议, 每天浏览网页, 看新闻都在接触HTTP, 可以在地址栏看到最前面大多是http.
HTTP协议, 实质上就是使用了网络编程, 使用TCP/IP连接, 来传输文本和图片等数据, 再通过浏览器进行解析和显示的.
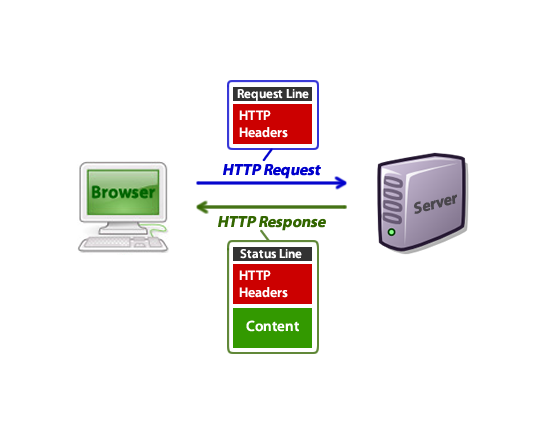 (图来自参考1)
(图来自参考1)
上述的图片就可以帮我们理解http协议的过程, 上述的结构是一个典型的BS模型.
首先, 浏览器发送http请求, 服务器接收请求后进行处理, 之后返回一个http响应. 浏览器接收到响应之后, 会对响应进行处理, 其中的html会被解析和渲染成为我们平时看到的网页.
分析http协议
分析http协议有很多方法, 我这里使用火狐插件Firebug. 这个插件被广泛地用于网页调试, 功能强大, 使用简便, 网页开发利器之一.
Firebug的安装
方法有两种: (前提是你先安装了火狐)
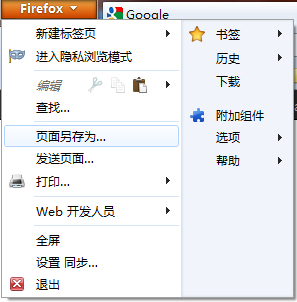
1.在火狐左上角的菜单中单击附加组件, 在右上角的搜索框中输入firebug, 回车即可搜索到.
2.也可以在Firefox中打开http://getfirebug.com/这个网页, 上面有个Install Firebug的按钮.
HTTP headers
我们先打开firebug, 在地址栏中输入百度的主页(注意: 必须先打开firebug, 否则firebug捕获不到数据).
你会看到一个firebug面板, 选择其中的网络面板(初次安装, 可能需要先启用), 如下图.

我们可以看到, 这里的百度主页有多个请求, 第一个是主页html代码的请求, 剩下的都是在html解析中发出的新请求, 比如说加载js, 加载图片等. 你可以在这个面板中试试, 操作还是很简单的.
点开第一项: GET www.baidu.com. 我们可以看到头信息, 响应, 缓存, HTML等选项.
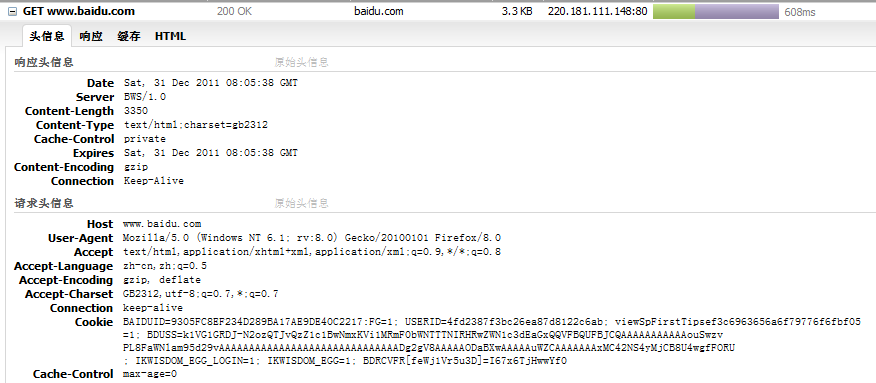
对应最开始的那个图, 这里面包含了我们在前面说过的, HTTP headers头信息, 包含了请求头信息和响应头信息.
使用Firebug工具, 获得这些头信息, 我们就可以大概理解HTTP协议的工作流程了.
获取百度页面, 首先是发送请求, 这个请求是浏览器帮我们发出的, 我们只负责了一个网址的输入. 浏览器自动发送一个请求头信息(有删减).
GET / HTTP/1.1
Host: www.baidu.com
User-Agent: Mozilla/5.0 (Windows NT 6.1; rv:8.0) Gecko/20100101 Firefox/8.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: zh-cn,zh;q=0.5
Accept-Encoding: gzip, deflate
Accept-Charset: GB2312,utf-8;q=0.7,*;q=0.7
Connection: keep-alive
Cache-Control: max-age=0
第一行:GET / HTTP/1.1 分为三个部分, GET是说明使用的HTTP方法, 常用的HTTP方法有GET和POST, 表示拿取一个资源
后面是/, 这个表示拿取根目录的资源, 默认是index.html或default.html等, 根据各服务器的配置不同而不同, 反正就是要拿到默认的页面.
HTTP/1.1表示了HTTP的版本, 一般是固定不变的.
后面的都是Key-Value的形式, Host表明了请求的主机域名或ip, 通过host和第一行的信息, 就可以知道地址栏中请求的资源, 这个例子请求的是http://www.baidu.com/主页.
如果是http://www.baidu.com/logo.png(注:示例链接不可用), 那么这个头信息肯定会包含这样的内容.
GET /logo.png HTTP/1.1
Host: www.baidu.com
在这个例子中, 整个响应如下:
HTTP/1.1 200 OK
Date: Sat, 31 Dec 2011 08:23:40 GMT
Server: BWS/1.0
Content-Length: 3350
Content-Type: text/html;charset=gb2312
Cache-Control: private
Expires: Sat, 31 Dec 2011 08:23:40 GMT
Content-Encoding: gzip
Connection: Keep-Alive
<!doctype html><html><head><meta http-equiv="Content-Type" content="text/html;charset=gb2312"><title>百度一下,你就知道
(省略...)
</html> <script type="text/javascript" src="http://www.baidu.com/cache/hps/js/hps-1.4.js"></script> <!--ade6dd8ede8ff3ea-->
最前面的就是响应头信息, 后面空一行, 跟着就是html代码, 经过渲染后就是我们看到的网页. 响应头信息主要说下第一行: HTTP/1.1 200 OK , 也是三个部分, 第一个和之前一样, 是个HTTP版本信息, 后面200叫做状态码, 根据这个可以知道相应的状态(具体看参考2), 主要是以下几个大类:
1xx:信息,请求收到,继续处理
2xx:成功,行为被成功地接受、理解和采纳
3xx:重定向,为了完成请求,必须进一步执行的动作
4xx:客户端错误,请求包含语法错误或者请求无法实现
5xx:服务器错误,服务器不能实现一种明显无效的请求
一个最简单的HTTP服务器
一个HelloWorld的http服务器作为第一个服务器, 这个服务器不处理请求头信息, 只是返回一个固定的内容, 可以在页面显示HelloWorld.
# -.- coding:utf-8 -.-
'''
Created on 2011-11-19
@author: icejoywoo
'''
import socket
import datetime
# 初始化socket
s = socket.socket()
# 获取主机名, 也可以使用localhost
#host = socket.gethostname()
host = "localhost"
# 默认的http协议端口号
port = 80
# 绑定服务器socket的ip和端口号
s.bind((host, port))
# 服务器名字/版本号
server_name = "MyServerDemo/0.1"
# 缓存时间, 缓存一天
expires = datetime.timedelta(days=1)
# GMT时间格式
GMT_FORMAT = '%a, %d %b %Y %H:%M:%S GMT'
# 相应网页的内容
content = '''
<html>
<head><title>MyServerDemo/0.1</title></head>
<body>
<h1>Hello, World!</h1>
</body>
</html>
'''
# 可同时连接五个客户端
s.listen(5)
# 提示信息
print "You can see a HelloWorld from this server in ur browser, type in", host, "\r\n"
# 服务器循环
while True:
# 等待客户端连接
c, addr = s.accept()
print "Got connection from", addr, "\r\n"
# 显示请求信息
print "--Request Header:"
# 接收浏览器的请求, 不作处理
data = c.recv(1024)
print data
# 获得请求的时间
now = datetime.datetime.utcnow()
# 相应头文件和内容
response = '''HTTP/1.1 200 OK
Server: %s
Date: %s
Expires: %s
Content-Type: text/html;charset=utf8
Content-Length: %s
Connection: keep-alive
%s''' % (
server_name,
now.strftime(GMT_FORMAT),
(now + expires).strftime(GMT_FORMAT),
len(content),
content
)
# 发送回应
c.send(response)
print "--Response:\r\n", response
c.close()
参考:
1. HTTP Headers for Dummies: http://net.tutsplus.com/tutorials/other/http-headers-for-dummies/
2.Status Code Definitions: http://www.w3.org/Protocols/rfc2616/rfc2616-sec10.html



{kind=link}