
以下操作,集群每台机器都要做
以下操作,集群每台机器都要做
以下操作,集群每台机器都要做
----------------------------------------------------------------------------------------------------------
1. 安装conda, 我选择是 miniconda3
2. 下载安装geospark(最新版本需要 python3.7)
https://github.com/apache/incubator-sedona/tree/master/python/geospark
安装包(最新版本不提供 whl,python目录下有个 build_wheel.sh ,需自己生成,且必须python3.7)
如果是老版本,则自带这个安装文件,老版本支持python3.6
pip install geospark-1.3.0-py3-none-any.whl

安装 PyArrow:
spark.sql.execution.arrow.enabled 设置为 true , 则必须安装
pip3 install PyArrow==0.14.1 -i https://pypi.tuna.tsinghua.edu.cn/simple/
安装pyproj==2.4.0:
使用geopandas进行坐标系转换时,报错RuntimeError: b'no arguments in initialization list' 问题是由proj造成的,可以通过更新proj修复
pip3 install --ignore-installed pyproj==2.4.0 -i https://pypi.douban.com/simple/
3. 把自己的程序放到某个位置,比如 /opt/myproject。 然后在 /opt/software/miniconda3/envs/datamining/lib/python3.6/site-packages 目录下创建 my.pth文件,加入以下包,否则无法识别自定义包。
比如以下内容:
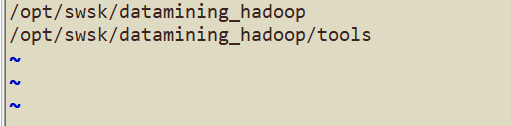
4. 下载下来的对应jar包(GeoSpark\python\geospark\jars\2_4) 拷贝到 /opt/cloudera/parcels/SPARK2-2.3.0.cloudera4-1.cdh5.13.3.p0.611179/lib/spark2/jars 下面。 (我使用的是 cloudera manager)

5. 环境变量设置

6. 重启集群
7. 测试
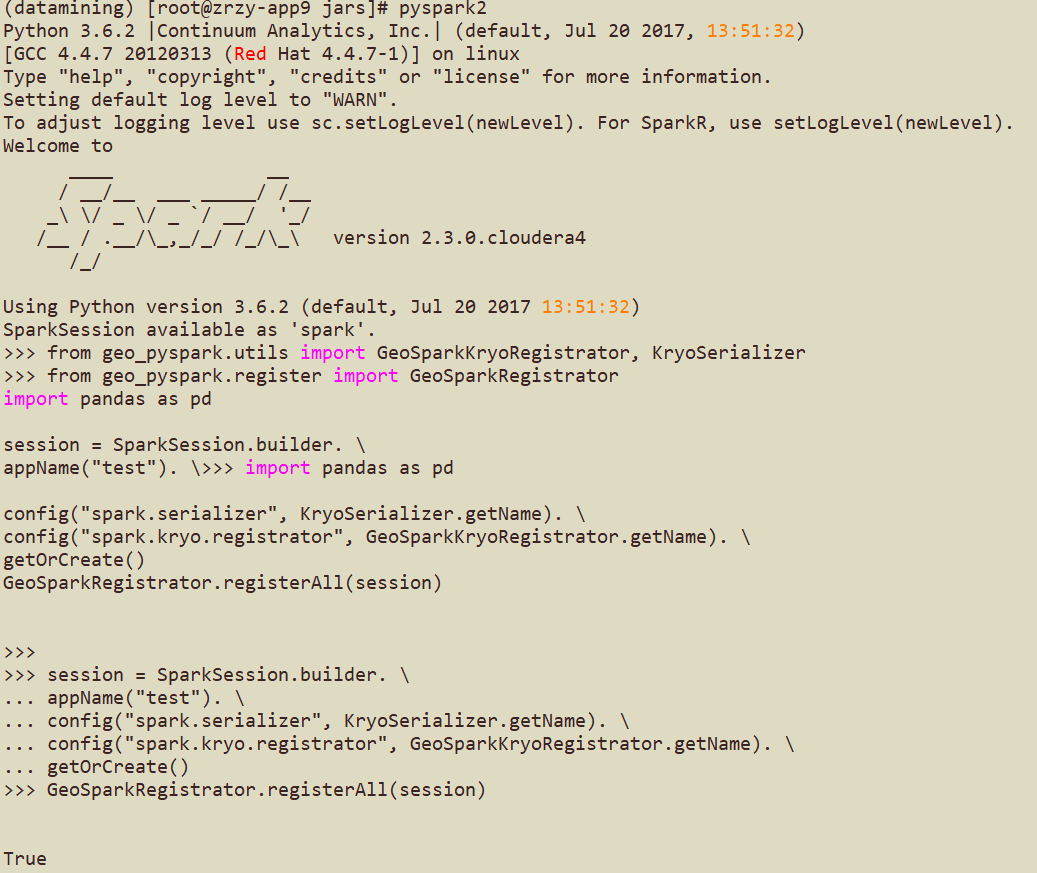
测试代码如下(返回 True就是ok了):
from geo_pyspark.utils import GeoSparkKryoRegistrator, KryoSerializer
from geo_pyspark.register import GeoSparkRegistrator
import pandas as pd
session = SparkSession.builder. \
appName("test"). \
config("spark.serializer", KryoSerializer.getName). \
config("spark.kryo.registrator", GeoSparkKryoRegistrator.getName). \
getOrCreate()
GeoSparkRegistrator.registerAll(session)

