

三、连接查询部分

--------------------嵌套循环-------------------- /* UserInfo表数据少、Coupon表数据多
嵌套循环可以理解为就是两层For循环,外层For会循环其中的每一项,内层For进行匹配,
相应的外层For对应外部输入表,执行计划的图示排在上面,内层For对应内部出入表,执行计划的图示排在下面,
外部表每一行都要使用来匹配,而内部表却不一定每一行都在匹配中被使用,所以,
1、外部表输入越小越好,也可以利用索引来减少输入行数
2、内部表匹配则可以利用索引来减少匹配条件的范围,尽快获取匹配行
3、多大多数情况下,查询优化器会自动更替结果集小的表为外部,大的为内部
当两个Join的表外部输入结果集比较小,而内部输入所查找的表非常大时,查询优化器更倾向于选择循环嵌套方式。 */ SELECT * FROM dbo.UserInfo AS u INNER JOIN dbo.Coupon AS c ON u.Id = c.UserId

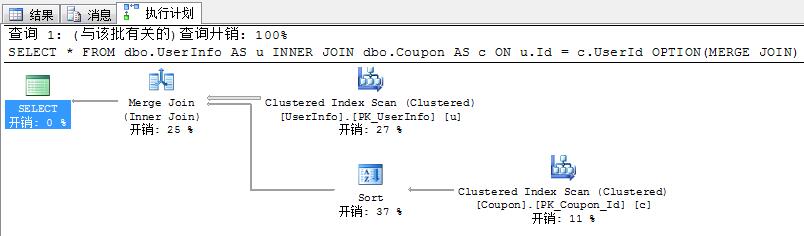
--------------------合并连接-------------------- /*
UserInfo表数据少、Coupon表数据多 不同于循环嵌套的是,合并连接是从每个表仅仅执行一次访问,对于两个输入列都有序的情况下,合并连接的效率更高,
其中排序的的重要性毋庸置疑了,B树中的叶层就是按照一定的逻辑顺序维护的。也就是说,聚集索引和非聚集覆盖索引,
都可以通过对叶层的有序扫描以较小的代价就可以获取有序的数据。在这种情况下,就算输入表的规模比较大,合并联接也相当给力。
如果计划分析器确定连接的一侧记录集中的元素是唯一确定的,那么就会采用一对多的匹配方式(多指另一侧的元素会有重复),
在这种情况下,合并排序效率应该是几种连接方式中最高的。但如果所需的数据列并不存在上述的条件的时候,对于较大的输入来说排序
往往是一个开销非常大的操作(因为基于比较的排序最快也就是n log n的),因此优化器通常不会在这种情况下选用合并联接。
但是对于较小的输入排序的消耗还是可以接受的。合并连接需要双方有序,并且要求join的条件为等号,如果输入数据的双方无序,
则查询分析器不会选择合并连接,我们也可以通过索引提示强制使用合并连接,这就是SQL语句为什么要加OPTION(MERGE JOIN)的原因 */ CREATE NONCLUSTERED INDEX Index_Coupon_UserId ON dbo.Coupon(UserId) --DROP INDEX Index_Coupon_UserId ON dbo.Coupon
SELECT * FROM dbo.UserInfo AS u INNER JOIN dbo.Coupon AS c ON u.Id = c.UserId --OPTION(MERGE JOIN)
--------------------哈希连接-------------------- /* 散列连接同样仅仅只需要只访问1次双方的数据。散列连接通过在内存中建立散列表实现。 这比较消耗内存,如果内存不足还会占用tempdb。但并不像合并连接那样需要双方有序。 删除掉UserInfo的主键及其中的聚集索引,在执行以下SQL 要删除掉聚集索引,否则两个有序输入SQL Server会选择代价更低的合并连接。 SQL Server利用两个上面的输入生成哈希表,下面的输入来探测,可以在属性窗口看到这些信息, 通常来说,所求数据在其中一方或双方没有排序的条件达成时,会选用哈希匹配。 */ ALTER TABLE dbo.UserInfo DROP CONSTRAINT PK_UserInfo_Id --删除主键 --DROP INDEX Index_UserInfo_Name --删除聚集索引 --ALTER TABLE dbo.UserInfo ADD CONSTRAINT PK_UserInfo_Id PRIMARY KEY CLUSTERED(Id) --创建主键 SELECT * FROM dbo.UserInfo AS u INNER JOIN dbo.Coupon AS c ON u.Id = c.UserId

--------------------多表并行-------------------- /* 当多个表连接时,SQL Server还允许在多CPU或多核的情况下允许查询并行,这样无疑提高了效率。 */ SELECT * FROM dbo.UserInfo AS u INNER JOIN dbo.Coupon AS c ON u.Id = c.UserId INNER JOIN dbo.OneWayAirPolicy_20w AS o ON u.Id = o.PId



