

二、函数计算部分

--------------------标量聚合--------------------
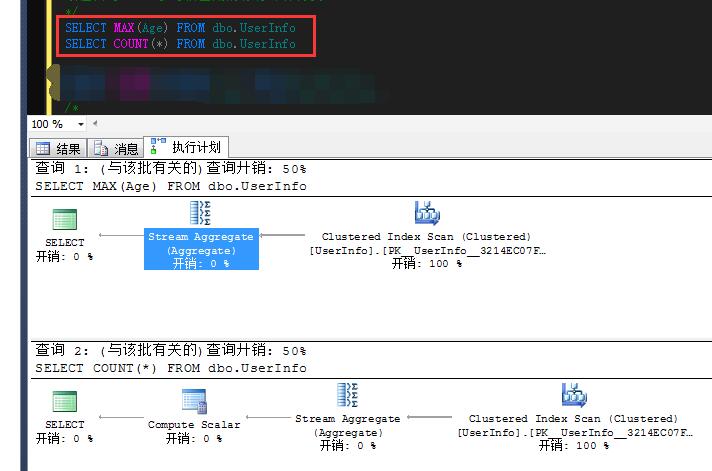
/* 标量聚合-主要在聚合函数操作中产生 计算标量:根据行中的现有值计算出一个新值 流聚合:在相应排序的流中,计算多组行的汇总值 所有的聚合函数都会有流聚合出现,但是其不会消耗IO,只消耗CPU 除MAX()和MIN()外其他聚合函数都会同时出现标量和聚合两个操作 当列列表只包含聚合函数时,则结果集只具有一个行给出的聚合值, 该值由与WHERE子句相匹配的源行计算得到。 */ SELECT MAX(Age) FROM dbo.UserInfo SELECT COUNT(*) FROM dbo.UserInfo
/* 执行以下语句,你会发现对[Id]进行去重由于是主键不会有重复,所以直接 通过流聚合就可以计算出结果,而[Name]字段进行去重的时候会有一个Sort排序的操作, 排序是比较消耗资源的尤其在数据量较大的表中,所以我们可以针对这个进行一下优化 */ SELECT COUNT(DISTINCT Id) FROM dbo.UserInfo SELECT COUNT(DISTINCT Name) FROM dbo.UserInfo

/* 为[Name]字段建立一个非聚集索引再执行一下,会发现出现两个流聚合却没有了排序, 这样就节省了排序的开销,标量聚合算法比较简单,适合非重复值的聚合操作,调优时 尽量避免排序的产生,将分组(GROUP BY)字段锁定在索引覆盖范围内 */ DROP INDEX dbo.UserInfo.Index_UserInfo_Name CREATE INDEX Index_UserInfo_Name ON dbo.UserInfo(Name)

--------------------散列聚合(哈希匹配)--------------------/* 散列聚合(哈希匹配)-为了解决流聚合的不足,应对大数据的操作而产生的 对于数据量比较大时,SQL Server选择的是哈希匹配。 在内存中建立好散列表后,会按照GROUP BY后面的值作为键, 然后依次处理集合中的每条数据,当键在散列表中不存在时, 向散列表添加条目,当键已经在散列表中存在时,按照规则 聚合函数计算散列表中的值 */ SELECT Name,COUNT(*) FROM dbo.UserInfo GROUP BY Name SELECT [Type],COUNT(*) FROM dbo.UserInfo GROUP BY [Type]

--------------------排序--------------------/* 排序-资源消耗较高的操作 对于数据量比较小时,执行GROUP BY操作会使用SORT 注意:Sort操作是占用内存的操作,当内存不足时会占用Tempdb (SQL Server总是会在Sort操作和散列匹配中选择成本最低的) 调优时为排序字段建立索引可以更好的提高查询效率,如果想 按照添加时间倒序,那么Order By Id(Identity)可以达到同样的 结果,而且效率还更高 */ SELECT * FROM dbo.UserInfo ORDER BY AddTime SELECT * FROM dbo.UserInfo ORDER BY Id

--------------------查看查询IO、时间、内存占用--------------------/* 使用SET STATISTICS IO, TIME还有其他的监控元素可以查看到当前 执行的SQL性能,有针对性的进行调优操作 选中表按Alt+F1可以显示选中表的结构,包括列、主键、索引等 执行SQL语句使用Ctrl+M可以显示当前SQL的执行计划,便于调试 dbo是SQL Server的架构名,默认就是dbo,除非强制将函数等写在其他架构名 下才无法调用 */ SET STATISTICS IO, TIME ON SELECT * FROM dbo.UserInfo SET STATISTICS IO, TIME OFF




