1. 使用excel(简单使用)
数据- 自网站-导入
2.you-get
python爬虫入门
1.环境配置
python,request,lxml
2.原理
爬虫的框架如下:
1.挑选种子URL;
2.将这些URL放入待抓取的URL队列;
3.取出待抓取的URL,下载并存储进已下载网页库中。此外,将这些URL放入待抓取URL队列,进入下一循环;
4.分析已抓取队列中的URL,并且将URL放入待抓取URL队列,从而进入下一循环。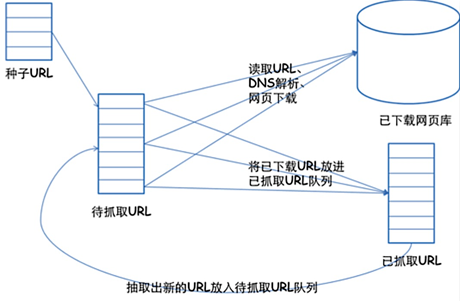
爬虫的基本流程:
简单的说,我们向服务器发送请求后,会得到返回的页面,通过解析页面之后,我们可以抽取我们想要的那部分信息,并存储在指定的文档或数据库中。这样,我们想要的信息就被我们“爬”下来啦~
Requests+Xpath爬去豆瓣电影
import requests
from lxml import etree
from bs4 import BeautifulSoup
def movie_spider(url):
data = requests.get(url).text
s = etree.HTML(data)
# 根据页面的xpath解析数据
film = s.xpath('/html/body/div[3]/div[1]/h1/span[1]/text()')
director = s.xpath('/html/body/div[3]/div[1]/div[3]/div[1]/div[1]/div[1]/div[1]/div[2]/span[1]/span[2]/a/text()')
# 浏览器检查的Xpath和实际不对应?为什么?
actor1= s.xpath('//*[@id="info"]/span[3]/span[2]/a[1]/text()')
time = s.xpath('/html/body/div[3]/div[1]/div[3]/div[1]/div[1]/div[1]/div[1]/div[2]/span[13]/text()')
print(film,director,actor1,time)
静态网页抓取
def top250_movie_spider():
"""
1.定制请求头,network>user-agent
:return:
"""
movie_list = []
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:63.0) Gecko/20100101 Firefox/63.0',
'Host':'movie.douban.com'
}
for i in range(0,10):
link = 'https://movie.douban.com/top250?start='+str(i*25)+'&filter='
r = requests.get(link,headers=headers,timeout=10)
# 使用BeautifulSoup解析网页
soup = BeautifulSoup(r.text,'lxml')
div_list = soup.find_all('div',class_='hd')
for each in div_list:
movie = each.a.span.text.strip()
movie_list.append(movie)
return movie_list
if __name__ == "__main__":
url = "https://movie.douban.com/subject/1292052/"
# movie_spider(url)
print(top250_movie_spider())
动态网页抓取
解析真实地址抓取:
network(刷新网页抓包)>XHR>确定真实地址
json库解析数据
import requests
import json
link ="https://api-zero.livere.com/v1/comments/list?callback=jQuery1124047657659644175476_1543235317407&limit=10&repSeq=4272904&requestPath=%2Fv1%2Fcomments%2Flist&consumerSeq=1020&livereSeq=28583&smartloginSeq=5154&_=1543235317409"
def single_page_comment(link):
# 定制请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.89 Safari/537.36'}
r = requests.get(link, headers=headers)
json_string = r.text
json_string = json_string[json_string.find('{'):-2]
json_data = json.loads(json_string)
common_list = json_data['results']['parents']
for eachone in common_list:
message = eachone['content']
print(message)
# 对比不同的地址,找出改变的量
for page in range(1,4):
link1 = "https://api-zero.livere.com/v1/comments/list?callback=jQuery112403473268296510956_1531502963311&limit=10&offset="
link2 = "&repSeq=4272904&requestPath=%2Fv1%2Fcomments%2Flist&consumerSeq=1020&livereSeq=28583&smartloginSeq=5154&_=1531502963316"
page_str = str(page)
link = link1 + page_str + link2
print (link)
single_page_comment(link)
使用Selenium模拟浏览器抓取
from selenium import webdriver
from selenium.webdriver.firefox.firefox_binary import FirefoxBinary
import time
# # 需要geckodriver,并放入环境变量中 --错误
# driver = webdriver.Firefox()
# driver.get("https://www.baidu.com")
#动态爬取网页
caps = webdriver.DesiredCapabilities().FIREFOX
caps["marionette"] = True
# 计算机中firefox的地址
binary = FirefoxBinary(r"C:\Program Files (x86)\Mozilla Firefox\firefox.exe")
driver = webdriver.Firefox(firefox_binary=binary,capabilities=caps)
for i in range(0,20):
driver.get("https://zh.airbnb.com/s/Shenzhen--China/homes?refinement_paths%5B%5D=%2Fhomes&click_referer=t%3ASEE_ALL%7Csid%3Ad66de168-dbd5-42e7-a122-bd4a001f781e%7Cst%3AMAGAZINE_HOMES&title_type=MAGAZINE_HOMES&query=Shenzhen%2C%20China&allow_override%5B%5D=&s_tag=ckaduMCI§ion_offset=4&items_offset="+str(i*18))
rent_list = driver.find_elements_by_css_selector('div._gig1e7')
for eachhouse in rent_list:
comment = eachhouse.find_element_by_css_selector('span._1cy09umr')
comment = comment.text
price_detail = eachhouse.find_elements_by_css_selector("span._1sfeueqe")
price_list = [i.text for i in price_detail]
price = price_list[1]
name = eachhouse.find_element_by_css_selector("div._190019zr")
name = name.text
details = eachhouse.find_element_by_css_selector("div._1etkxf1")
details = details.text
print(comment,price,name,details)

