

STM32的RAM分区介绍
对RAM分区的了解
在一个STM32程序代码中,从内存高地址到内存低地址,依次分布着栈区、堆区、全局区(静态区)、常量区、代码区,其中全局区中高地址分布着.bss段,低地址分布着.data段,
其分布图如下: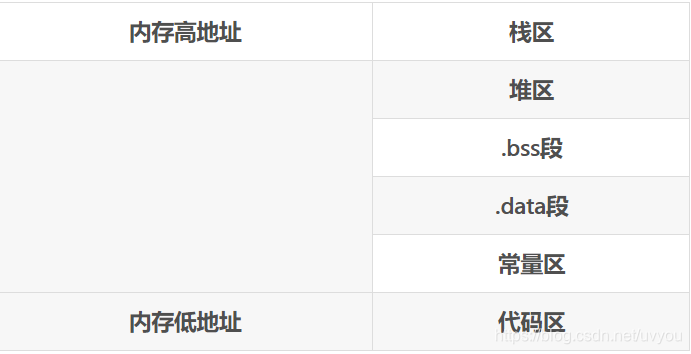
各区特点
一、栈区(stack)
临时创建的局部变量存放在栈区。
函数调用时,其入口参数存放在栈区。
函数返回时,其返回值存放在栈区。
const定义的局部变量存放在栈区。
2、堆区(heap)
堆区用于存放程序运行中被动态分布的内存段,可增可减。
可以有malloc等函数实现动态分布内存。
有malloc函数分布的内存,必须用free进行内存释放,否则会造成内存泄漏。
3、全局区(静态区)(对应C程序的数据段,不包含ro-data)
全局区有.bss段和.data段组成,可读可写。
4、.bss段
未初始化的全局变量存放在.bss段。
初始化为0的全局变量和初始化为0的静态变量存放在.bss段。
.bss段不占用可执行文件空间,其内容有操作系统初始化。
5、.data段
已经初始化的全局变量存放在.data段。
静态变量存放在.data段。
.data段占用可执行文件空间,其内容有程序初始化。
const定义的全局变量存放在.rodata段。
6、常量区
字符串存放在常量区。
常量区的内容不可以被修改。
7、代码区
程序执行代码存放在代码区。
字符串常量也有可能存放在代码区。
stm32下实现对分区的了解
通过在keil中编程,在串口通信中借助调试助手查看输出
代码如下:
#include "delay.h"
#include "key.h"
#include "sys.h"
#include "usart.h"
#include <stdlib.h>
int k1 = 1;
int k2;
static int k3 = 2;
static int k4;
int main(void)
{
static int m1=2, m2;
int i = 1;
char *p;
char str[10] = "hello";
char *var1 = "123456";
char *var2 = "abcdef";
int *p1=malloc(4);
int *p2=malloc(4);
u16 t;
u16 len;
u16 times=0;
free(p1);
free(p2);
delay_init();
NVIC_PriorityGroupConfig(NVIC_PriorityGroup_2);
uart_init(115200);
KEY_Init();
while(1)
{
for(t=0;t<len;t++)
{
while(USART_GetFlagStatus(USART1,USART_FLAG_TC)!=SET);
}
USART_RX_STA=0;
times++;
if(times%500==0)
{
printf("代码区地址\r\n");
printf(" i=%p\r\n", &i);
printf(" p=%p\r\n", &p);
printf(" str=%p\r\n", str);
printf("\n¶ÑÇø-¶¯Ì¬ÉêÇëµØÖ·\r\n");
printf(" %p\r\n", p1);
printf(" %p\r\n", p2);
printf("\r\n.bss¶Î");
printf("\nÈ«¾ÖÍⲿÎÞ³õÖµ k2£º%p\r\n", &k2);
printf("¾²Ì¬ÍⲿÎÞ³õÖµ k4£º%p\r\n", &k4);
printf("¾²Ì¬ÄÚ²¿ÎÞ³õÖµ m2£º%p\r\n", &m2);
printf("\r\n.data¶Î");
printf("\nÈ«¾ÖÍⲿÓгõÖµ k1£º%p\r\n", &k1);
printf("¾²Ì¬ÍⲿÓгõÖµ k3£º%p\r\n", &k3);
printf("¾²Ì¬ÄÚ²¿ÓгõÖµ m1£º%p\r\n", &m1);
printf("\r\n³£Á¿Çø\n");
printf("ÎÄ×Ö³£Á¿µØÖ· £º%p\r\n",var1);
printf("ÎÄ×Ö³£Á¿µØÖ· £º%p\r\n",var2);
printf("\r\n´úÂëÇø\n");
printf("³ÌÐòÇøµØÖ· £º%p\n",&main);
}
delay_ms(10);
}
}
补充:
1、全局区(静态区)
全局区有.bss、.data段组成,可读可写
①.bss段:未初始化的全局变量、初始化为0的全局变量、初始化为0的静态变量存放在.bss段。
②.data段:已经初始化的全局变量存放在.data段,静态变量存放在.data段,const定义的全局变量通常存放在.rodata段【也就是通常是在flash内,也可以通过修改分散加载修改】。
2、堆、栈区:
STM32中堆栈是为了存储不同信息而开辟的空间,具体对应于启动文件中的head和stack所定义的内存空间。
STM32中,堆向高地址增长,栈向低地址增长。
堆:是用户调用malloc时申请的内存空间。
栈:临时创建的局部变量(一般的局部变量+const修饰的局部变量),函数入口、函数参数,函数返回值存放在栈区。
3、常量区
①字符串存放在常量区
②常量区的内容不可修改
4、代码区
程序执行的代码,存放在代码区。
那么这些个区和实际的内存之间什么关系呢?
我们知道,一般选择STM32会考虑其RAM、ROM(即FLASH),RAM的特点是掉电丢失数据,仅在上电运行时存储数据。ROM的特点是掉电不丢失数据,一般用来存储代码和常量区数据。
至此我们可知:堆、栈、全局区(.bss段、.data段)都是存放在RAM中,而代码区和常量区的内容编译后存放在RAM中。
即:
RAM :堆 + 栈 + 全局区(.bss段、.data段))
ROM:代码区+常量区
我们在KEIL编译框下面,可以看到,Code、RO-data、RW-data、ZI-data四个部分,分别代表:代码占用空间、只读常量占用空间、已初始化的可读可写的变量占用空间、未初始化的可读可写变量。
此时:
RAM = RW-data + ZI-data
ROM = Code + RO-data + RW-data
————————————————
原文链接:https://blog.csdn.net/Z523588/article/details/130219635
.bss: 未被初始化的全局的C变量。这一节在o文件中不占实际的空间,只是一个place holder。o文件格式之所以区分初始化的变量和未被初始化的变量是因为处于空间利用率上的考虑。没有被初始化的变量确实没有必要占用实际的磁盘空间。https://www.cnblogs.com/idorax/p/6400210.html
1.1 data 段
用来存储已经初始化的全局变量,也属于静态内存分配区,会占用程序文件空间。
与bss相比,data就容易明白多了,它的名字就暗示着里面存放着数据。当然,如果数据全是零,为了优化考虑,编译器把它当作bss处理。通俗的说,data指那些初始化过(非零)的非const的全局变量。它有什么特点呢,我们还是来看看一个小程序的表现。
int data_array[1024 * 1024] = {1};
int main(int argc, char* argv[])
{
return 0;
}
[root@localhost data]# gcc -g data.c -o data.exe
[root@localhost data]# ll
total 4112
-rw-r--r-- 1 root root 85 Jun 22 14:35 data.c
-rwxr-xr-x 1 root root 4200025 Jun 22 14:35 data.exe
仅仅是把初始化的值改为非零了,文件就变为4M多。由此可见,data类型的全局变量是即占文件空间,又占用运行时内存空间的。
1.2 bss 段
BSS(Block Started by Symbol)用来存储未初始化的全局变量和静态变量,全局变量或静态变量值为0或NULL(对于指针变量而言)的通常会被编译器认为未初始化,属于静态内存分配区,不会占用程序文件空间,不存储这些变量在外存上,但是还是会占用一部分空间,这些空间用来标识未初始化的变量大小、属性等信息。
BSS段(bsssegment)通常是指用来存放程序中未初始化的全局变量的一块内存区域
并不给该段的数据分配空间,只是记录数据所需要的空间大小。
它有什么特点呢,让我们来看看一个小程序的表现。
int bss_array[1024 * 1024] = {0};
int main(int argc, char* argv[])
{
return 0;
}
[root@localhost bss]# gcc -g bss.c -o bss.exe
[root@localhost bss]# ll
total 12
-rw-r--r-- 1 root root 84 Jun 22 14:32 bss.c
-rwxr-xr-x 1 root root 5683 Jun 22 14:32 bss.exe
变量bss_array的大小为4M,而可执行文件的大小只有5K。 由此可见,bss类型的全局变量只占运行时的内存空间,而不占文件空间。
另外,大多数操作系统,在加载程序时,会把所有的bss全局变量全部清零,无需要你手工去清零。但为保证程序的可移植性,手工把这些变量初始化为0也是一个好习惯。
1.3 rodata
rodata的意义同样明显,ro代表read only,即只读数据(const)。
关于rodata类型的数据,要注意以下几点:
常量不一定就放在rodata里,有的立即数直接编码在指令里,存放在代码段(.text)中。
对于字符串常量,编译器会自动去掉重复的字符串,保证一个字符串在一个可执行文件(EXE/SO)中只存在一份拷贝。
rodata是在多个进程间是共享的,这可以提高空间利用率。
在有的嵌入式系统中,rodata放在ROM(如norflash)里,运行时直接读取ROM内存,无需要加载到RAM内存中。
在嵌入式linux系统中,通过一种叫作XIP(就地执行)的技术,也可以直接读取,而无需要加载到RAM内存中。
由此可见,把在运行过程中不会改变的数据设为rodata类型的,是有很多好处的:在多个进程间共享,可以大大提高空间利用率,甚至不占用RAM空间。同时由于rodata在只读的内存页面(page)中,是受保护的,任何试图对它的修改都会被及时发现,这可以帮助提高程序的稳定性。
text段:
代码段(codesegment/textsegment)通常是指用来存放程序执行代码的一块内存区域。这部分区域的大小在程序运行前就已经确定,并且内存区域通常属于只读,某些架构也允许代码段为可写,即允许修改程序。在代码段中,也有可能包含一些只读的常数变量,例如字符串常量等。
heap堆:
堆是用于存放进程运行中被动态分配的内存段,它的大小并不固定,可动态扩张或缩减。当进程调用malloc等函数分配内存时,新分配的内存就被动态添加到堆上(堆被扩张);当利用free等函数释放内存时,被释放的内存从堆中被剔除(堆被缩减)
stack栈:
是用户存放程序临时创建的局部变量,也就是说我们函数括弧“{}”中定义的变量(但不包括static声明的变量,static意味着在数据段中存放变量)。除此以外,在函数被调用时,其参数也会被压入发起调用的进程栈中,并且待到调用结束后,函数的返回值也会被存放回栈中。由于栈的先进先出特点,所以栈特别方便用来保存/恢复调用现场。从这个意义上讲,我们可以把堆栈看成一个寄存、交换临时数据的内存区。
常量段:
常量段一般包含编译器产生的数据(与只读段包含用户定义的只读数据不同)。比如说由一个语句a=2+3编译器把2+3编译期就算出5,存成常量5在常量段中
1.8.变量与关键字
static关键字
用途太多,以致于让新手模糊。不过,总结起来就有两种作用,改变生命期和限制作用域。如:
l 修饰inline函数:限制作用域
l 修饰普通函数:限制作用域
l 修饰局部变量:改变生命期
l 修饰全局变量:限制作用域
静态局部变量属于静态储存类别,在静态储存区内分配储存单元。在整个程序运行期间都不释放
const 关键字
倒是比较明了,用const修饰的变量放在rodata里,字符串默认就是常量。对const,注意以下几点就行了。
l 指针常量:指向的数据是常量。如 const char* p = “abc”; p指向的内容是常量 ,但p本身不是常量,你可以让p再指向”123”。
l 常量指针:指针本身是常量。如:char* const p = “abc”; p本身就是常量,你不能让p再指向”123”。
l 指针常量 + 常量指针:指针和指针指向的数据都是常量。const char* const p =”abc”; 两者都是常量,不能再修改。
volatile关键字
通常用来修饰多线程共享的全局变量和IO内存。告诉编译器,不要把此类变量优化到寄存器中,每次都要老老实实的从内存中读取,因为它们随时都可能变化。这个关键字可能比较生僻,但千万不要忘了它,否则一个错误让你调试好几天也得不到一点线索。
问题1,二进制文件不包含BSS段,那把BSS段放在哪
答:修改有1000个全局变量,难道要BIN里要存1000个0吗?在链接脚本里把BSS段组织在一起,记下它的起始地址、结束地址,重定位后把这块内存清0即可
问题2:全局变量不初始化的话默认初始化为零,干嘛还要手动清零
答:因为它是在BSS段的
————————————————
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/y13182588139/article/details/125559846


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构