☕️【系统设计】如何设计出优雅且实用的 API 接口
记得最开始的时候在设计接口的时候规范还没有那么多,因为前后端还没分离。不管是前端还是后端都是一个人开发,为了追求"效率"。所谓的接口规范百花齐放,各有各自的一套。后来前后端分离,哪些为了追求"效率"而写的代码,重构起来的代码也是头疼。
所以到了现在已经基本固定基本的机构体系,针对业务得不同还可以垂直拓展。
如何构建这几个部分每个公司要求都不同,没有什么“一定是最好的”标准,但一个优秀的后端接口和一个糟糕的后端接口对比起来差异还是蛮大的,其中最重要的关键点就是看是否规范!
在设计接口时,有很多因素要考虑,如接口的业务定位,接口的安全性,接口的可扩展性、接口的稳定性、接口的跨域性、接口的协议规则、接口的路径规则、接口单一原则、接口过滤和接口组合等诸多因素。
本文主要针对接口返回参数结合一些网上的案例比较和思考,来讲述接口返回参数需要怎么设计更加合理。
行业案例
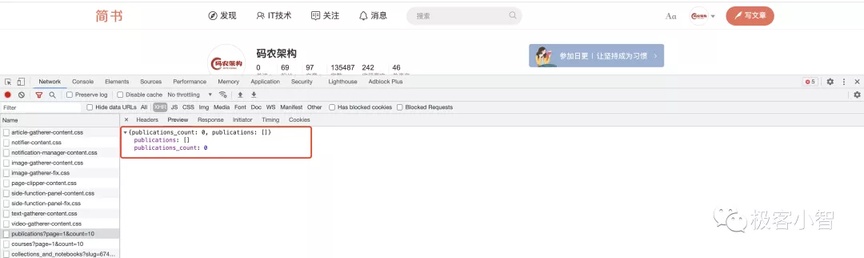
- 简书
这可能是我看到过最差的设计,打开几个网页可以看到接口返回参数设计,简单粗暴,这里就不错过多的评论。
{ // 结果集}
- 掘金
看完简书再看下另外一个产品掘金,掘金相对而言会好点。至少有了明显的层次结构,包含状态码、结果集、成功或错误,但是这个命名确实让人有点误解,至少我个人看到后是这种感觉。

- CSDN
就论接口参数 CSDN 算是中规中矩的接口,接口包含了三大要素:状态码、结果集、成功或错误的的提示。
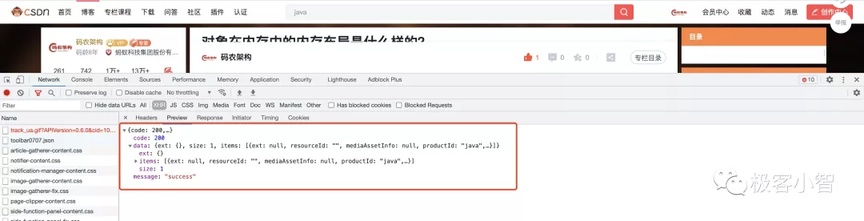
针对这种返回参数针对单体服务来讲算是合格的,知道每个接口的状态、对应状态的结果、针对状态如果要展示提示可以根据 message 对应的信息来确定。对于单体服务这种设计基本能满足要求。
- InfoQ
看到 InfoQ 的接口返回值,让我觉得不错的一点就是有一个拓展的返回参数设计,里面有个参数 cost(成本),通熟一点就是接口的耗时。
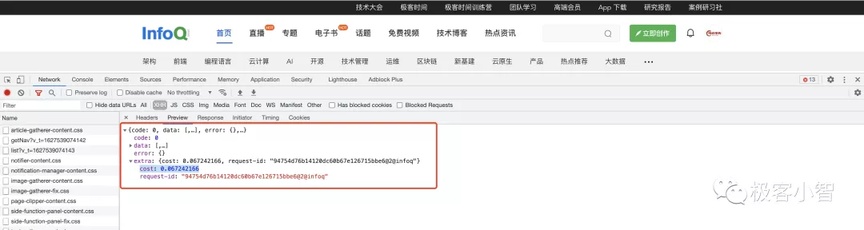
针对 InfoQ 的接口返回参数设计,相对上述几个产品而已确实优化了很多,尤其是针对接口做了成本/耗时统计。但是这种设计还是有点冗余,为什么这么讲呢?因为浏览器自带功能
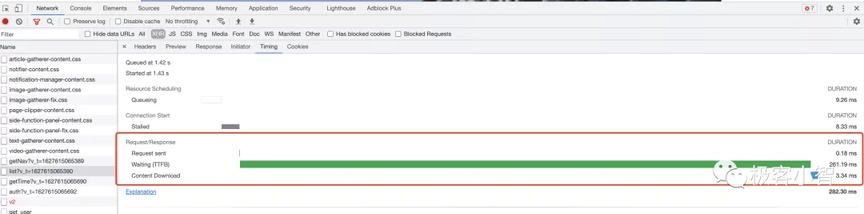
对于 request-id 个人理解为当前请求线程的链路 ID。在微服务体系中用于追踪服务的日志,算是一把利器。
设计优化
结合上面几个产品的接口返回参数设计,可以简单归纳接口返回参数的几个要点
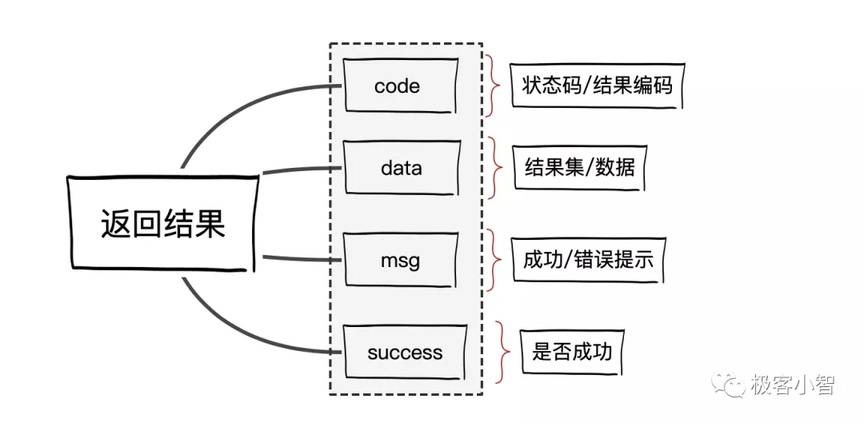
在结合 InfoQ 和 CSDN 的基础上,加上了 boolean 类型的是接口执行是否成功的标识,当然也你也可以用状态码,但是这里做了一些的优化调整。
再思考一下一种常见国际化问题
-
如何统一国家化提示?针对后端的一些校验异常抛出提示怎么处理国际化问题?
其实解决上诉问题国际化问题不是特别难,稍微做一下调整。
-
code 调整为:成功/错误的 messageKey,由前后端统一约束国际化的 key
-
msg 调整为:成功/错误的提示信息,由后端根据国际化配置转化成对应的错误信息
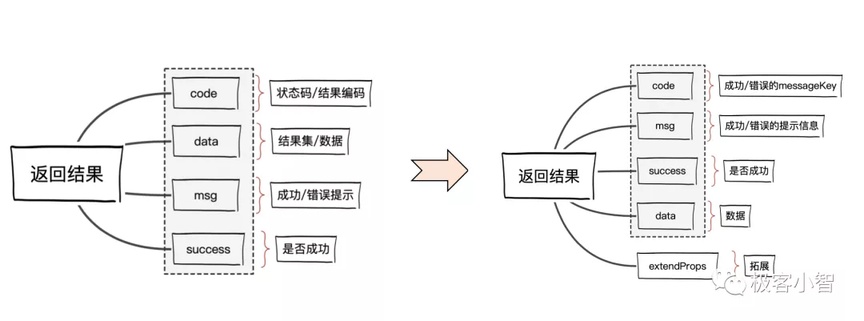
{ "success": true, "code": "return.optSuccess", "msg": "您的操作已成功!", "data": { // 数据 }, "extendProps":{ // 拓展 }}
设计拓展
在基础返回信息中针对拓展的补充,其实这里的目的主要是对于开发和运维人员来补充的。
思考下如果一个接口返回了错误信息,你的第一反应是怎样的?
查看后端日志,但是日志采集信息那么多,基于什么信息去查后台服务器的日志才能快速定位问题?
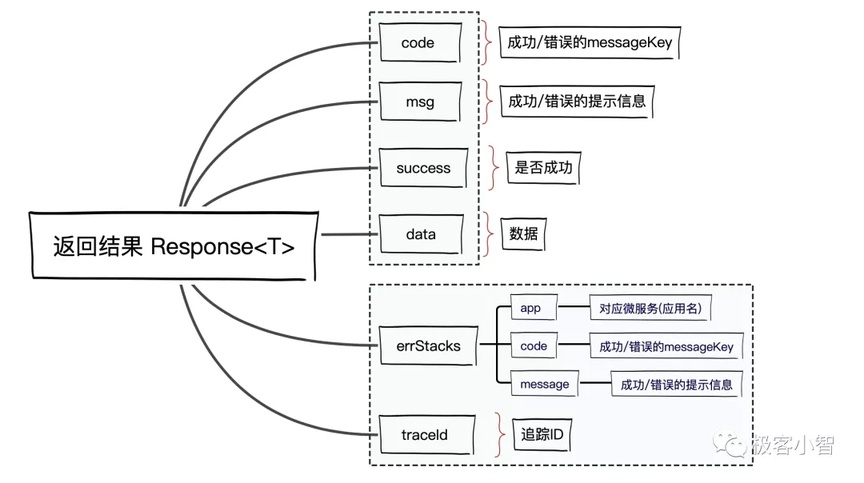
为了解决日志查询难定位的场景,这里建议加上链路 ID 也可称为追踪 ID,因此可以继续优化设计
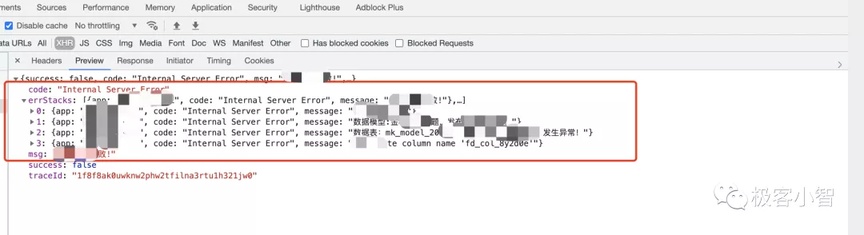
当然并不是所有的错误都需要去查看日志,必要的时候针对一些错误,后端开发完全可以将堆栈信息缓存抛出来,例如这样
针对接口看到堆栈信息大致可以定位到自己代码错误的位置,如果还定位不到就要通过链路 ID 查看后具体错误位置,因此针对接口返回参数可以继续优化
总结
互联网工程的高速发展,分布式、微服务、容器化架构的流行,互联网已全面进入云原生时代。构建系统的方式由最初的单体大应用演变为分布式架构,不以规矩,不能成方圆。只有我们不断地去优化才会创造出更好的产品。本期主要针对接口返回参数结合一些网上的案例比较和思考。
其实在设计接口时,有很多因素要考虑,如接口的业务定位,接口的安全性,接口的可扩展性、接口的稳定性、接口的跨域性、接口的协议规则、接口的路径规则、接口单一原则、接口过滤和接口组合等诸多因素。后期几期会逐一分享。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号