联合索引在B+树上的存储结构及数据查找方式
关注BiggerBoy公众号,第一时间获取干货!!
引言
上一篇文章《MySQL索引那些事》主要讲了MySQL索引的底层原理,且对比了B+Tree作为索引底层数据结构相对于其他数据结构(二叉树、红黑树、B树)的优势,最后还通过图示的方式描述了索引的存储结构。但都是基于单值索引,由于文章篇幅原因也只是在文末略提了一下联合索引,并没有大篇幅的展开讨论,所以这篇文章就单独去讲一下联合索引在B+树上的存储结构。
本文主要讲解的内容有:
- 联合索引在B+树上的存储结构
- 联合索引的查找方式
- 为什么会有最左前缀匹配原则
在分享这篇文章之前,我在网上查了关于MySQL联合索引在B+树上的存储结构这个问题,翻阅了很多博客和技术文章,其中有几篇讲述的与事实相悖。庆幸的是看到搜索引擎列出的有一条是来自思否社区的问答,有答主回答了这个问题,贴出一篇文章和一张图以及一句简单的描述。PS:贴出的文章链接已经打不开了。
所以在这样的条件下这篇文章就诞生了。
联合索引的存储结构
下面就引用思否社区的这个问答来展开我们今天要讨论的联合索引的存储结构的问题。
来自思否的提问,联合索引的存储结构(https://segmentfault.com/q/1010000017579884)有码友回答如下:
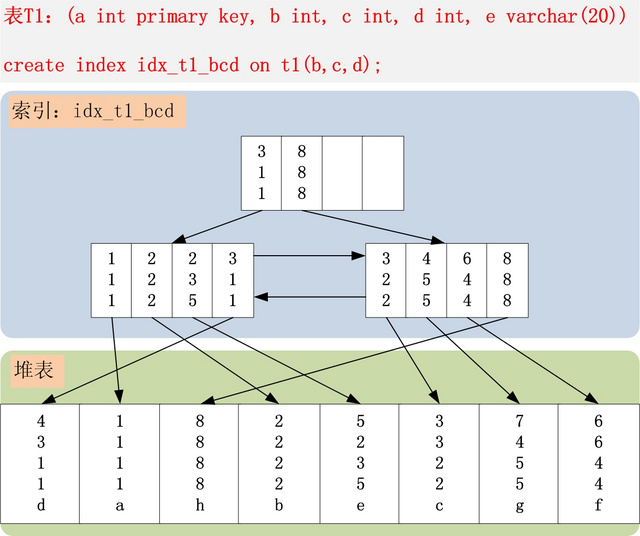
联合索引 bcd , 在索引树中的样子如图 , 在比较的过程中 ,先判断 b 再判断 c 然后是 d ,
由于回答只有一张图一句话,可能会让你有点看不懂,所以我们就借助前人的肩膀用这个例子来更加细致的讲探寻一下联合索引在B+树上的存储结构吧。
首先,表T1有字段a,b,c,d,e,其中a是主键,除e为varchar其余为int类型,并创建了一个联合索引idx_t1_bcd(b,c,d),然后b、c、d三列作为联合索引,在B+树上的结构正如上图所示。联合索引的所有索引列都出现在索引数上,并依次比较三列的大小。上图树高只有两层不容易理解,下面是假设的表数据以及我对其联合索引在B+树上的结构图的改进。PS:基于InnoDB存储引擎。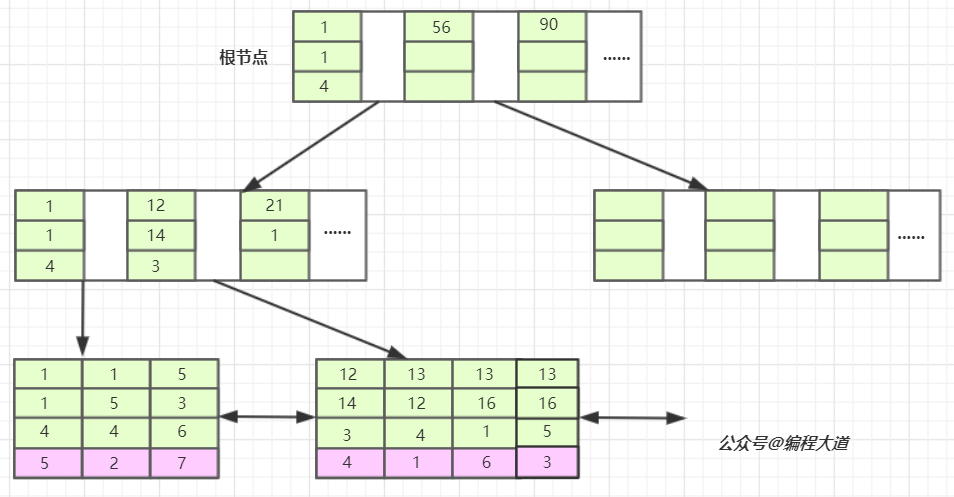
bcd联合索引在B+树上的结构图
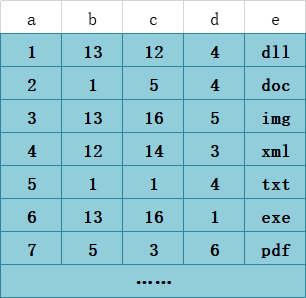
T1表
通过这俩图我们心里对联合索引在B+树上的存储结构就有了个大概的认识。下面用我的语言为大家解释一下吧。
我们先看T1表,他的主键暂且我们将它设为整型自增的(PS:至于为什么是整型自增上篇文章有详细介绍这里不再多说),InnoDB会使用主键索引在B+树维护索引和数据文件,然后我们创建了一个联合索引(b,c,d)也会生成一个索引树,同样是B+树的结构,只不过它的data部分存储的是联合索引所在行的主键值(上图叶子节点紫色背景部分),至于为什么辅助索引data部分存储主键值上篇文章也有介绍,感兴趣或还不知道的可以去看一下。
好了大致情况都介绍完了。下面我们结合这俩图来解释一下。
对于联合索引来说只不过比单值索引多了几列,而这些索引列全都出现在索引树上。对于联合索引,存储引擎会首先根据第一个索引列排序,如上图我们可以单看第一个索引列,如,1 1 5 12 13....他是单调递增的;如果第一列相等则再根据第二列排序,依次类推就构成了上图的索引树,上图中的1 1 4 ,1 1 5以及13 12 4,13 16 1,13 16 5就可以说明这种情况。
联合索引的查找方式
当我们的SQL语言可以应用到索引的时候,比如 select * from T1 where b = 12 and c = 14 and d = 3; 也就是T1表中a列为4的这条记录。存储引擎首先从根节点(一般常驻内存)开始查找,第一个索引的第一个索引列为1,12大于1,第二个索引的第一个索引列为56,12小于56,于是从这俩索引的中间读到下一个节点的磁盘文件地址,从磁盘上Load这个节点,通常伴随一次磁盘IO,然后在内存里去查找。当Load叶子节点的第二个节点时又是一次磁盘IO,比较第一个元素,b=12,c=14,d=3完全符合,于是找到该索引下的data元素即ID值,再从主键索引树上找到最终数据。
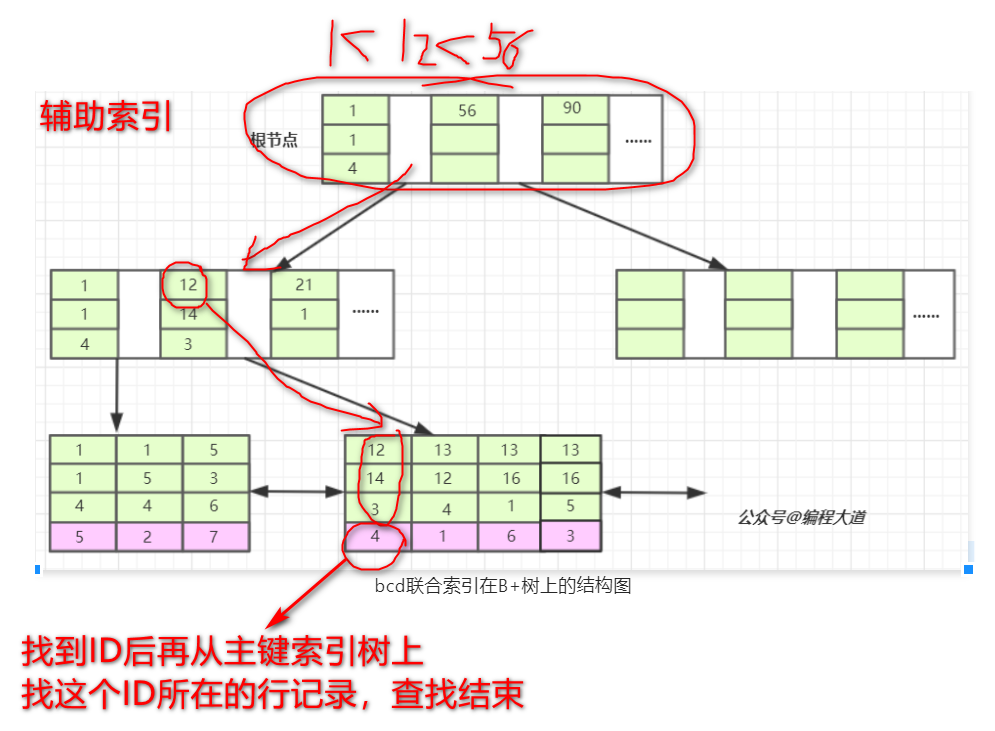
最左前缀匹配原则
之所以会有最左前缀匹配原则和联合索引的索引构建方式及存储结构是有关系的。
首先我们创建的idx_t1_bcd(b,c,d)索引,相当于创建了(b)、(b、c)(b、c、d)三个索引,看完下面你就知道为什么相当于创建了三个索引。
我们看,联合索引是首先使用多列索引的第一列构建的索引树,用上面idx_t1_bcd(b,c,d)的例子就是优先使用b列构建,当b列值相等时再以c列排序,若c列的值也相等则以d列排序。我们可以取出索引树的叶子节点看一下。
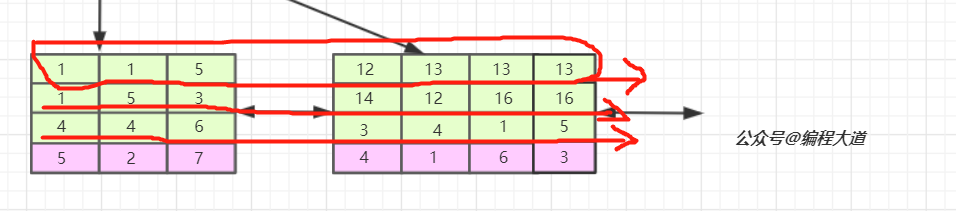
索引的第一列也就是b列可以说是从左到右单调递增的,但我们看c列和d列并没有这个特性,它们只能在b列值相等的情况下这个小范围内递增,如第一叶子节点的第1、2个元素和第二个叶子节点的后三个元素。
由于联合索引是上述那样的索引构建方式及存储结构,所以联合索引只能从多列索引的第一列开始查找。所以如果你的查找条件不包含b列如(c,d)、(c)、(d)是无法应用缓存的,以及跨列也是无法完全用到索引如(b,d),只会用到b列索引。
这就像我们的电话本一样,有名和姓以及电话,名和姓就是联合索引。在姓可以以姓的首字母排序,姓的首字母相同的情况下,再以名的首字母排序。
如:
M
毛 不易 178********
马 化腾 183********
马 云 188********
Z
张 杰 189********
张 靓颖 138********
张 艺兴 176********
我们知道名和姓是很快就能够从姓的首字母索引定位到姓,然后定位到名,进而找到电话号码,因为所有的姓从上到下按照既定的规则(首字母排序)是有序的,而名是在姓的首字母一定的条件下也是按照名的首字母排序的,但是整体来看,所有的名放在一起是无序的,所以如果只知道名查找起来就比较慢,因为无法用已排好的结构快速查找。
到这里大家是否明白了为啥会有最左前缀匹配原则了吧。
实践
如下列举一些SQL的索引使用情况
1 select * from T1 where b = 12 and c = 14 and d = 3;-- 全值索引匹配 三列都用到 2 3 select * from T1 where b = 12 and c = 14 and e = 'xml';-- 应用到两列索引 4 5 select * from T1 where b = 12 and e = 'xml';-- 应用到一列索引 6 7 select * from T1 where b = 12 and c >= 14 and e = 'xml';-- 应用到bc两列索引及索引条件下推优化 8 9 select * from T1 where b = 12 and d = 3;-- 应用到一列索引 因为不能跨列使用索引 没有c列 连不上 10 11 select * from T1 where c = 14 and d = 3;-- 无法应用索引,违背最左匹配原则
后记
到这里MySQL索引的联合索引的存储结构及查找方式就讲完了,本人能力有限,也是站着前人的肩膀上创作的此文,因为看到搜索引擎的搜索结果前几个技术文章中有存在讲述不清或讲述有误的地方,所以自己才总结出这篇文章分享给大家,如有不对的地方一定要指正哦,谢谢了。
这篇文章断断续续利用工作之余画图加写作用了两三天,主要内容就是上面这些了。不可否认,这篇文章在一定程度上有纸上谈兵之嫌,因为我本人对MySQL的使用属于菜鸟级别,更没有太多数据库调优的经验,在这里高谈阔论实属惭愧。就当是我个人的一篇学习笔记了。
另外,MySQL索引及知识非常广泛,本文只是涉及到其中一部分。如与排序(ORDER BY)相关的索引优化及覆盖索引(Covering index)的话题本文并未涉及,同时除B-Tree索引外MySQL还根据不同引擎支持的哈希索引、全文索引等等本文也并未涉及。如果有机会,希望再对本文未涉及的部分进行补充吧。
创作不易,如果对你有帮助,请不要吝啬你的赞,这对我是很大的鼓励~
~~手机阅读的用户请扫码关注公众号,你的关注是对我最大的支持!~~

觉得好看,请点这里↓↓↓

 浙公网安备 33010602011771号
浙公网安备 33010602011771号