
Apache Parquet is a columnar storage format available to any project in the Hadoop ecosystem, regardless of the choice of data processing framework, data model or programming language.
我们把嵌套数据类型的一行叫做一个记录(record),嵌套数据类型的特点是一个 record 中的 column 除了可以是 Int, Long, String 这样的原语(primitive)类型以外,还可以是 List, Map, Set 这样的复杂类型。
在行式存储中一行的多列是连续的写在一起的,在列式存储中数据按列分开存储,例如可以只读取 A.B.C 这一列的数据而不去读 A.E 和 A.B.D,那么如何根据读取出来的各个列的数据重构出一行记录呢?
Google 的Dremel系统解决了这个问题,核心思想是使用“record shredding and assembly algorithm”来表示复杂的嵌套数据类型,同时辅以按列的高效压缩和编码技术,实现降低存储空间,提高 IO 效率,降低上层应用延迟。
Parquet 就是基于 Dremel 的数据模型和算法实现的。
Parquet 适配多种计算框架
Parquet 是语言无关的,
而且不与任何一种数据处理框架绑定在一起,
适配多种语言和组件,能够与 Parquet 配合的组件有:
- 查询引擎: Hive, Impala, Pig, Presto, Drill, Tajo, HAWQ, IBM Big SQL
- 计算框架: MapReduce, Spark, Cascading, Crunch, Scalding, Kite
- 数据模型: Avro, Thrift, Protocol Buffers, POJOs
那么 Parquet 是如何与这些组件协作的呢?
这个可以通过图 2 来说明。
数据从内存到 Parquet 文件或者反过来的过程主要由以下三个部分组成:

- 存储格式 (storage format)
parquet-format项目定义了Parquet的文件格式,其中元数据在parquet-format中定义,包括Parquet原始类型定义、Page类型、编码类型、压缩类型等等。
- 对象模型转换器 (object model converters)
这部分功能由parquet-mr项目来实现,主要完成外部对象模型与 Parquet 内部数据类型的映射。
- 对象模型 (object models)
对象模型可以简单理解为内存中的数据表示,Avro, Thrift, Protocol Buffers, Hive SerDe, Pig Tuple, Spark SQL InternalRow 等这些都是对象模型。
说明:
这里需要注意的是 Avro, Thrift, Protocol Buffers 都有他们自己的存储格式,但是 Parquet 并没有使用他们,而是使用了自己在parquet-format项目里定义的存储格式。所以如果你的应用使用了 Avro 等对象模型,这些数据序列化到磁盘还是使用的parquet-mr定义的转换器把他们转换成 Parquet 自己的存储格式。
数据模型
Parquet支持嵌套的数据模型,类似于Protocol Buffers,每一个数据模型的schema包含多个字段,每一个字段又可以包含多个字段,每一个字段有三个属性:重复数、数据类型和字段名,重复数可以是以下三种:required(出现1次),repeated(出现0次或多次),optional(出现0次或1次)。每一个字段的数据类型可以分成两种:group(复杂类型)和primitive(基本类型)。例如Dremel中提供的Document的schema示例,它的定义如下:
message Document {
required int64 DocId;
optional group Links {
repeated int64 Backward;
repeated int64 Forward;
}
repeated group Name {
repeated group Language {
required string Code;
optional string Country;
}
optional string Url;
}
}
可以把这个Schema转换成树状结构,根节点可以理解为repeated类型,如下图:
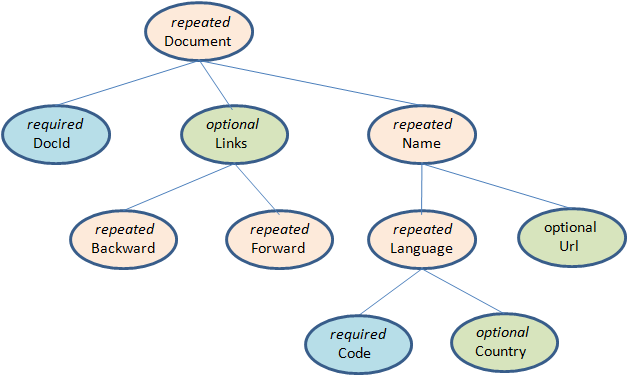
可以看出在Schema中所有的基本类型字段都是叶子节点,在这个Schema中一共存在6个叶子节点,如果把这样的Schema转换成扁平式的关系模型,就可以理解为该表包含六个列。
Parquet中没有Map、Array这样的复杂数据结构,但是可以通过repeated和group组合来实现这样的需求。在这个包含6个字段的表中有以下几个字段和每一条记录中它们可能出现的次数:
DocId int64 只能出现一次
Links.Backward int64 可能出现任意多次,但是如果出现0次则需要使用NULL标识
Links.Forward int64 同上
Name.Language.Code string 同上
Name.Language.Country string 同上
Name.Url string 同上
由于在一个表中可能存在出现任意多次的列,对于这些列需要标示出现多次或者等于NULL的情况,它是由Striping/Assembly算法实现的。
Parquet文件格式
Parquet文件是以二进制方式存储的,所以是不可以直接读取的,文件中包括该文件的数据和元数据,因此Parquet格式文件是自解析的。在HDFS文件系统和Parquet文件中存在如下几个概念。
- HDFS块(Block):它是HDFS上的最小的副本单位,HDFS会把一个Block存储在本地的一个文件并且维护分散在不同的机器上的多个副本,通常情况下一个Block的大小为256M、512M等。
- HDFS文件(File):一个HDFS的文件,包括数据和元数据,数据分散存储在多个Block中。
- 行组(Row Group):按照行将数据物理上划分为多个单元,每一个行组包含一定的行数,在一个HDFS文件中至少存储一个行组,Parquet读写的时候会将整个行组缓存在内存中,所以如果每一个行组的大小是由内存大的小决定的,例如记录占用空间比较小的Schema可以在每一个行组中存储更多的行。
- 列块(Column Chunk):在一个行组中每一列保存在一个列块中,行组中的所有列连续的存储在这个行组文件中。一个列块中的值都是相同类型的,不同的列块可能使用不同的算法进行压缩。
- 页(Page):每一个列块划分为多个页,一个页是最小的编码的单位,在同一个列块的不同页可能使用不同的编码方式。
Glossary
-
Block (hdfs block): This means a block in hdfs and the meaning is unchanged for describing this file format. The file format is designed to work well on top of hdfs.
-
File: A hdfs file that must include the metadata for the file. It does not need to actually contain the data.
-
Row group: A logical horizontal partitioning of the data into rows. There is no physical structure that is guaranteed for a row group. A row group consists of a column chunk for each column in the dataset.
-
Column chunk: A chunk of the data for a particular column. These live in a particular row group and is guaranteed to be contiguous in the file.
-
Page: Column chunks are divided up into pages. A page is conceptually an indivisible unit (in terms of compression and encoding). There can be multiple page types which is interleaved in a column chunk.
Hierarchically, a file consists of one or more row groups. A row group contains exactly one column chunk per column. Column chunks contain one or more pages.

Parquet文件的每个文件块负责存储一个行组,行组由列块组成,且一个列块负责存储一列数据。每个列块中的的数据以页为单位。
Unit of parallelization
- MapReduce - File/Row Group
- IO - Column chunk
- Encoding/Compression - Page
File format
This file and the thrift definition should be read together to understand the format.
4-byte magic number "PAR1"
<Column 1 Chunk 1 + Column Metadata>
<Column 2 Chunk 1 + Column Metadata>
...
<Column N Chunk 1 + Column Metadata>
<Column 1 Chunk 2 + Column Metadata>
<Column 2 Chunk 2 + Column Metadata>
...
<Column N Chunk 2 + Column Metadata>
...
<Column 1 Chunk M + Column Metadata>
<Column 2 Chunk M + Column Metadata>
...
<Column N Chunk M + Column Metadata>
File Metadata
4-byte length in bytes of file metadata
4-byte magic number "PAR1"
In the above example, there are N columns in this table, split into M row groups. The file metadata contains the locations of all the column metadata start locations. More details on what is contained in the metadata can be found in the thrift files.
Metadata is written after the data to allow for single pass writing.
Readers are expected to first read the file metadata to find all the column chunks they are interested in. The columns chunks should then be read sequentially.
Metadata
There are three types of metadata: file metadata, column (chunk) metadata and page header metadata. All thrift structures are serialized using the TCompactProtocol.
文件格式
通常情况下,在存储Parquet数据的时候会按照Block大小设置行组的大小,由于一般情况下每一个Mapper任务处理数据的最小单位是一个Block,这样可以把每一个行组由一个Mapper任务处理,增大任务执行并行度。Parquet文件的格式如下图所示
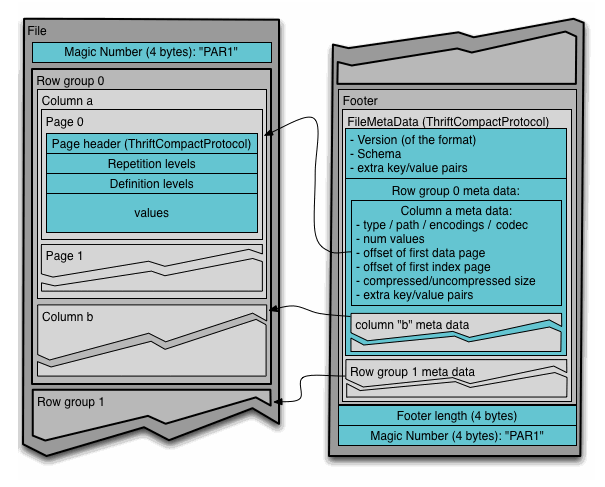
上图展示了一个Parquet文件的内容,一个文件中可以存储多个行组,文件的首位都是该文件的Magic Code,用于校验它是否是一个Parquet文件,Footer length了文件元数据的大小,通过该值和文件长度可以计算出元数据的偏移量,文件的元数据中包括每一个行组的元数据信息和该文件存储数据的Schema信息。除了文件中每一个行组的元数据,每一页的开始都会存储该页的元数据,在Parquet中,有三种类型的页:数据页、字典页和索引页。数据页用于存储当前行组中该列的值,字典页存储该列值的编码字典,每一个列块中最多包含一个字典页,索引页用来存储当前行组下该列的索引,目前Parquet中还不支持索引页,但是在后面的版本中增加。
在执行MR任务的时候可能存在多个Mapper任务的输入是同一个Parquet文件的情况,每一个Mapper通过InputSplit标示处理的文件范围,如果多个InputSplit跨越了一个Row Group,Parquet能够保证一个Row Group只会被一个Mapper任务处理。
映射下推(Project PushDown)
说到列式存储的优势,映射下推是最突出的,它意味着在获取表中原始数据时只需要扫描查询中需要的列,由于每一列的所有值都是连续存储的,所以分区取出每一列的所有值就可以实现TableScan算子,而避免扫描整个表文件内容。
在Parquet中原生就支持映射下推,执行查询的时候可以通过Configuration传递需要读取的列的信息,这些列必须是Schema的子集,映射每次会扫描一个Row Group的数据,然后一次性得将该Row Group里所有需要的列的Cloumn Chunk都读取到内存中,每次读取一个Row Group的数据能够大大降低随机读的次数,除此之外,Parquet在读取的时候会考虑列是否连续,如果某些需要的列是存储位置是连续的,那么一次读操作就可以把多个列的数据读取到内存。
谓词下推(Predicate PushDown)
在数据库之类的查询系统中最常用的优化手段就是谓词下推了,通过将一些过滤条件尽可能的在最底层执行可以减少每一层交互的数据量,从而提升性能,例如”select count(1) from A Join B on A.id = B.id where A.a > 10 and B.b < 100”SQL查询中,在处理Join操作之前需要首先对A和B执行TableScan操作,然后再进行Join,再执行过滤,最后计算聚合函数返回,但是如果把过滤条件A.a > 10和B.b < 100分别移到A表的TableScan和B表的TableScan的时候执行,可以大大降低Join操作的输入数据。
无论是行式存储还是列式存储,都可以在将过滤条件在读取一条记录之后执行以判断该记录是否需要返回给调用者,在Parquet做了更进一步的优化,优化的方法是对每一个Row Group的每一个Column Chunk在存储的时候都计算对应的统计信息,包括该Column Chunk的最大值、最小值和空值个数。通过这些统计值和该列的过滤条件可以判断该Row Group是否需要扫描。另外Parquet未来还会增加诸如Bloom Filter和Index等优化数据,更加有效的完成谓词下推。
性能
相比传统的行式存储,Hadoop生态圈近年来也涌现出诸如RC、ORC、Parquet的列式存储格式,它们的性能优势主要体现在两个方面:
1、更高的压缩比,由于相同类型的数据更容易针对不同类型的列使用高效的编码和压缩方式。
2、更小的I/O操作,由于映射下推和谓词下推的使用,可以减少一大部分不必要的数据扫描,尤其是表结构比较庞大的时候更加明显,由此也能够带来更好的查询性能
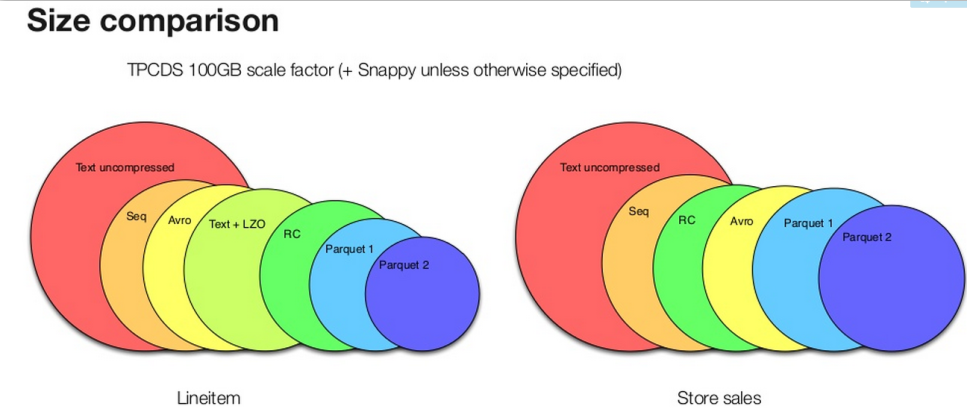
上图是展示了使用不同格式存储TPC-H和TPC-DS数据集中两个表数据的文件大小对比,可以看出Parquet较之于其他的二进制文件存储格式能够更有效的利用存储空间,而新版本的Parquet(2.0版本)使用了更加高效的页存储方式,进一步的提升存储空间。
criteo公司在Hive中使用ORC和Parquet两种列式存储格式执行TPC-DS基准测试的结果,测试结果可以看出在数据存储方面,两种存储格式在都是用snappy压缩的情况下量中存储格式占用的空间相差并不大,查询的结果显示Parquet格式稍好于ORC格式,两者在功能上也都有优缺点,Parquet原生支持nested式数据结构,而ORC对此支持的较差,这种复杂的Schema查询也相对较差;而Parquet不支持数据的修改和ACID,但是ORC对此提供支持,但是在OLAP环境下很少会对单条数据修改,更多的则是批量导入。
总结
本文介绍了一种支持嵌套数据模型对的列式存储系统Parquet,作为大数据系统中OLAP查询的优化方案,它已经被多种查询引擎原生支持,并且部分高性能引擎将其作为默认的文件存储格式。通过数据编码和压缩,以及映射下推和谓词下推功能,Parquet的性能也较之其它文件格式有所提升,可以预见,随着数据模型的丰富和Ad hoc(即席查询)查询的需求,Parquet将会被更广泛的使用。
浅析即席查询 在数据仓库领域有一个概念叫Ad hoc queries,中文一般翻译为“即席查询”。即席查询是指那些用户在使用系统时,根据自己当时的需求定义的查询。即席查询生成的方式很多,最常见的就是使用即席查询工具。一般的数据展现工具都会提供即席查询的功能。通常的方式是,将数据仓库中的维度表和事实表映射到语义层,用户可以通过语义层选择表,建立表间的关联,最终生成SQL语句。即席查询与通常查询从SQL语句上来说,并没有本质的差别。它们之间的差别在于,通常的查询在系统设计和实施时是已知的,所以我们可以在系统实施时通过建立索引、分区等技术来优化这些查询,使这些查询的效率很高。而即席查询是用户在使用时临时生产的,系统无法预先优化这些查询,所以即席查询也是评估数据仓库的一个重要指标。即席查询的位置通常是在关系型的数据仓库中,即在EDW或者ROLAP中。多维数据库有自己的存储方式,对即席查询和通常查询没有区别。在一个数据仓库系统中,即席查询使用的越多,对数据仓库的要求就越高,对数据模型的对称性的要求也越高。对称性的数据模型对所有的查询都是相同的,这也是维度建模的一个优点。
参考来源:
https://www.cnblogs.com/ITtangtang/p/7681019.html
http://parquet.apache.org/documentation/latest/
https://baike.baidu.com/item/%E5%8D%B3%E5%B8%AD%E6%9F%A5%E8%AF%A2/2886987?fr=aladdin
https://www.jianshu.com/p/76b7776ed567

 浙公网安备 33010602011771号
浙公网安备 33010602011771号