Mysql:常见问题
字段越多,查询越慢吗?为什么
字段越多,查询通常会变慢。具体原因涉及数据库内部的一些机制:
-
数据读取:
每个查询都需要从硬盘或者内存中读取数据。字段越多,每行的数据量越大,意味着更多的数据需要被读取到内存中进行处理。这增加了IO操作次数和时间。 -
内存使用:
字段越多,查询的结果集越大,需要占用更多的内存。对于复杂的查询,数据库可能需要在内存中存储和处理大量数据,这会导致内存开销增大,可能导致性能下降。 -
锁和并发控制:
在多用户环境中,字段多的查询可能会持有锁更长时间,特别是如果这些字段分布在不同的行或页面上。这可能会导致锁争用和等待,从而影响整体性能。
在关联查询时,比如A和B表是一对多关系,select * from A inner join B on A.id = B.A_id,数据库在原理上是怎么去查询A和B的数据的,请一步步说明
- 扫描表 A: MySQL 会先从表 A 开始扫描数据。如果select的字段和表A关联字段是同一个或者id字段,那么则会遍历索引,而不是全表扫描
- 连接表 B: 对于表 A 的每一行数据,MySQL 会使用连接条件 A.id = B.A_id 在表 B 中进行匹配。这里的连接方式(join type)取决于查询计划,常见的连接方式有嵌套循环连接(Nested Loop Join)和哈希连接(Hash Join)。
嵌套循环连接: 对于表 A 的每一行数据,MySQL 会扫描表 B,并根据连接条件 A.id = B.A_id 查找匹配的数据行。当B表的A_id有索引时,可以通过索引快速查找B表数据,而不是全表扫描
哈希连接: MySQL 会先构建一个哈希表,将表 B 的连接列(B.A_id)哈希化,然后在扫描表 A 时,通过哈希表进行快速匹配。
- 提取数据: 对于每一个匹配的行,MySQL 会提取需要的字段数据,并将匹配结果返回给客户端。在 SELECT * 的情况下,会提取 A 表和 B 表的所有列。
笛卡尔积查询如何实现?
比如A和B表都有10条记录,如下SQL:
select * from A,B
查询的结果会有100条记录,相当两个表相乘
为什么推荐小表来join大表?
其实绝大部分情况下,from A表是走全表的,join表很多时候能走索引,因此尽量from表是小数据量表,join是大数据量表也可以快速查询
7种SQLjoin写法?
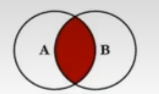
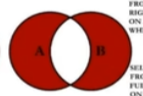
SELECT employee_id, department_ name
FROM employees e Inner JoIN departments d ON e.`department_id` = d. 'department_id `;
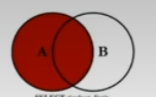
SELECT employee_id, department_name
FROM employees e
LEFT JoIN departments d ON e. `department_id` = d. department_id `;
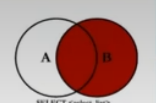
SELECT employee_id, department_name
FROM employees e
RIGHT JoIN departments d ON e. `department_id` = d. department_id `;
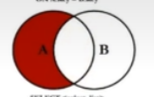
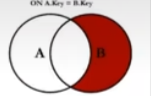
SELECT employee_id, department_name
FROM employees e
LEFT JOIN departments d ON e. `department_id` = d.'department_id`
WHERE d. department_id IS NUL;
SELECT employee_id, department name
FROM employees e
RIGHT JOIN departments d ON e. `department_id = d. `department_id`
WHERE e.'department_id`IS NULL;
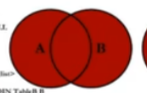
SELECT employee_id, department_name
FROM employees e
LEFT JoIN departments d ON e. `department_id` = d. department_id `;
union all
SELECT employee_id, department name
FROM employees e
RIGHT JOIN departments d ON e. `department_id = d. `department_id`
WHERE e.'department_id`IS NULL;
SELECT employee_id, department_name
FROM employees e
LEFT JOIN departments d ON e. `department_id` = d.'department_id`
WHERE d. department_id IS NUL;
union all
SELECT employee_id, department name
FROM employees e
RIGHT JOIN departments d ON e. `department_id = d. `department_id`
WHERE e.'department_id`IS NULL;
视图的作用是什么?为啥真实开发中很少见到创建视图?
视图并不是一张真实表,而是将各个真实表拼接展示的虚拟表,不过我们对视图进行增加、更新、删除,是能影响到实体表的。视图的出现是为了让一些人员不能看到真实表的某一些字段,比如表A有工资等敏感字段,不希望开发人员能看到这张表的全部数据,那么就可以根据A创建视图,让开发人员看这张视图即可
在中小型企业中,其实对信息安全这块不是很严格,往往开发人员是可以直接看到表的全部字段数据的,所以就不需要创建视图。但在一些大型企业,视图还是挺常见到的
默认字符集?
在MysQL 8.0版本之前,默认字符集为latin1,utf8字符集指向的是utf8mb3。网站开发人员在数据库设计的时候往往会将编码修改为utf8字符集。如果遗忘修改默认的编码,就会出现乱码的问题。从MySQL 8.0开始,数据库的默认编码将改为utf8mb4,从而避免上述乱码的问题。
utf8字符集是什么?
utf8与utf8mb4
utf8字符集表示一个字符需要使用14个字节,但是我们常用的一些字符使用13个字节就可以表示了。而字符集表示一个字符所用的最大字节长度,在某些方面会影响系统的存储和性能,所以设计MysQL的设计者偷偷的定义了两个概念:
utf8mb3︰阉割过的utf8字符集,只使用1~3个字节表示字符。
utf8mb4 :正宗的utf8字符集,使用1~4个字节表示字符。
在MysQL中utf8是utf8mb3的别名,所以之后在MysQL中提到utf8就意味着使用1~3个字节来表示一个字符。如果大家有使用4字节编码一个字符的情况,比如存储一些emoji表情,那请使用utf8mb4 。
比较规则是什么?


Mysql,什么SQL语句下会出现锁表情况
1. DDL 操作
任何修改表结构的操作都会锁住表,例如:
ALTER TABLE:修改表结构,如增加或删除列。
DROP TABLE:删除表。
TRUNCATE TABLE:清空表数据。
总结:最好在数据库低峰的时候进行ALTER TABLE操作。
2. 全表扫描的 DML 操作
如果在没有索引的情况下对表进行全表扫描的操作,可能会导致表锁,例如:
UPDATE:对表中所有行进行更新。
DELETE:删除表中所有行。
总结:每次写update语句时,保证where是有索引的。在事务开启下,多次对同一张表执行相同的update语句不会锁表,但会锁行,因此尽量缩短事务时间。
3. 大量数据操作
在表上执行大规模数据操作也可能导致锁表,例如:
大批量的 INSERT 操作。
总结:一次性插入的数量不宜太多
4. 行锁升级为表锁
在 InnoDB 存储引擎中,如果行锁的数量过多,也可能会升级为表锁,例如:
多行更新操作 UPDATE,涉及的行数特别多时。
总结:尽量确保每次更新的数据行不会太多
存储过程为什么很少见到?
存储过程其实就是程序化的sql语句,贴近编程语言的编写习惯。它最大的好处:
提前将复杂的SQL逻辑预先编译后,能被客户端直接调用
有它的弊端有明显,主要有两个:
- 调试困难。如果用Java编写逻辑使用idea进行调试就会方便很多,而存储过程是在数据库上,不方便调试
- 数据库压力。数据库来承担这个工作,对于一些高并发的系统的来说,是需要减少数据库压力的
索引
索引的目的是什么?
减少IO次数

 浙公网安备 33010602011771号
浙公网安备 33010602011771号