编码
1.一个字节==8位二进制数,1Byte == 8bits(比特),一比特就是占二进制数的一位
十进制2的n次方转换成二进制数,这个二进制数有n+1比特位
2.ASCII码:一个英文字母(不分大小写)占一个字节的空间,一个中文汉字占两个字节的空间。
UTF-8编码:一个英文字符等于一个字节,一个中文(含繁体)等于三个字节。中文标点占三个字节,英文标点占一个字节
Unicode编码:一个英文等于两个字节,一个中文(含繁体)等于两个字节。中文标点占两个字节,英文标点占两个字节】
GBK编码,一个汉字占两个字节。
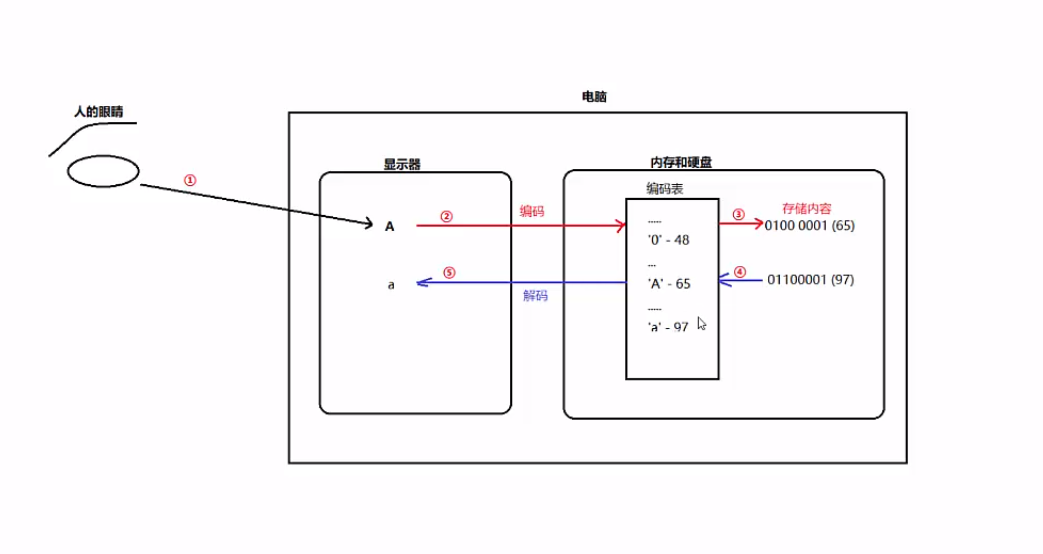
3.字符到二进制数的过程叫做“编码”
二进制数到字符的过程叫做“解码”
4.字符集:字符的集合;ASCLL字符集,UTF-8字符集等等,包含一些字符以及其对应编码数字
5.Unicode是万国码,UTF就是Unicode转换格式,UTF-8,UTF-16都跟它密切相关
6.Unicode为每个字符定制属于自己的ID,这个ID叫做“码点”,码点就是二进制数,“码元”是码点的切分单位
比如说UTF-8,码元有8位,将码点的二进制数以8位为一个单位,也就是一个码元;
ASCII码:一个英文字母(不分大小写)占一个字节的空间,一个中文汉字占两个字节的空间。
UTF-8编码:一个英文字符等于一个字节,一个中文(含繁体)等于三个字节。中文标点占三个字节,英文标点占一个字节
Unicode编码:一个英文等于两个字节,一个中文(含繁体)等于两个字节。中文标点占两个字节,英文标点占两个字节
7.编码和解码示意图:

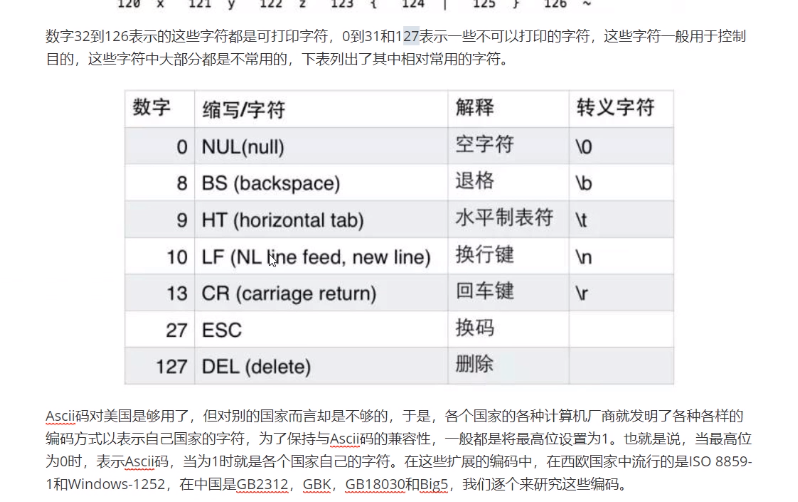
8.ASCLL表

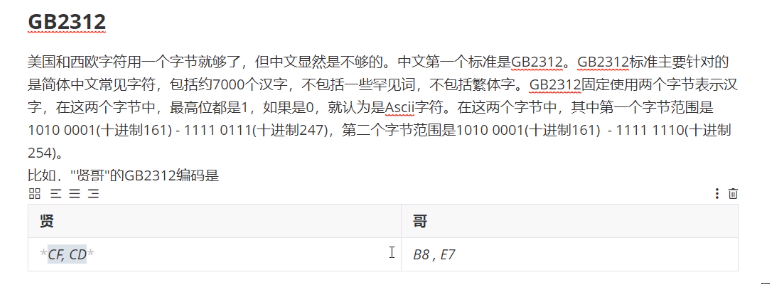
9.GB2312编码
10.GBK

11.GB18030

12.big5

13.编码表总结

二.兼容和乱码
1.兼容:A兼容B是指A包含B,B的全部内容,A都有,而且A还有B一些没有的
2.乱码:相同的字符读和取时用了不兼容的两套编码方案
兼容:
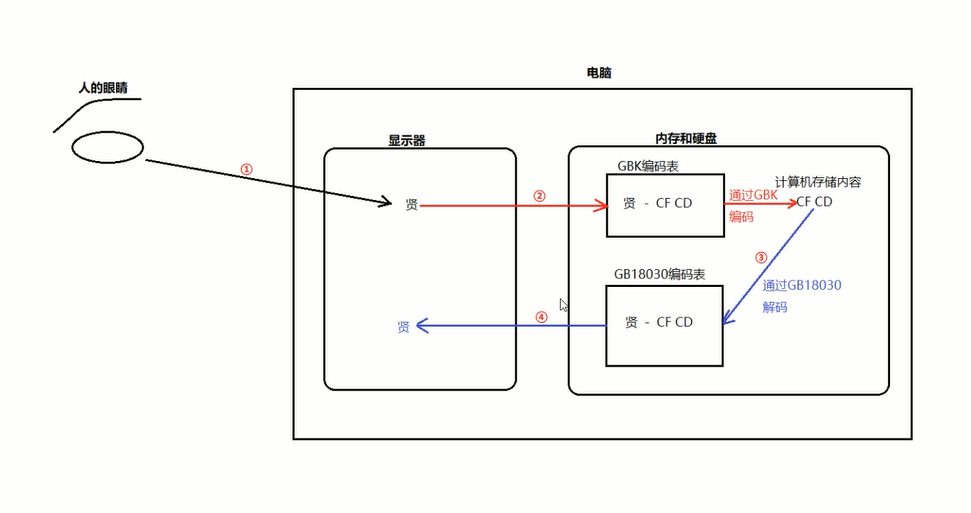
乱码:
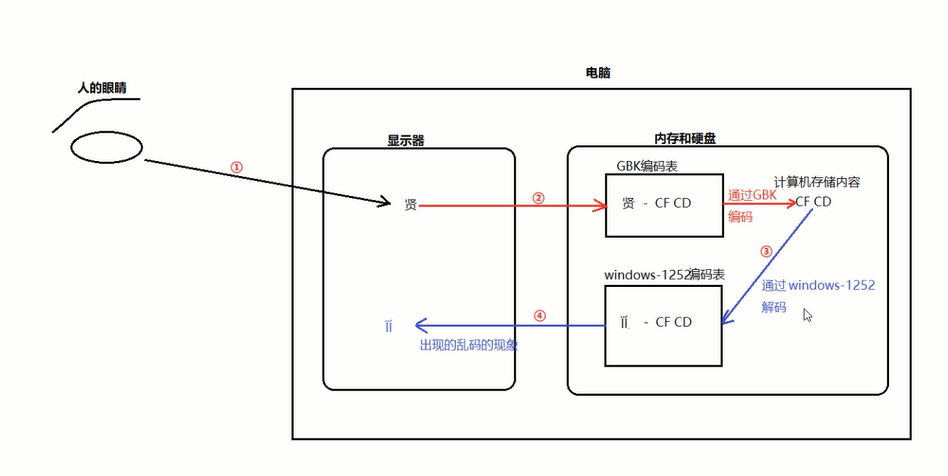
3.Unicode

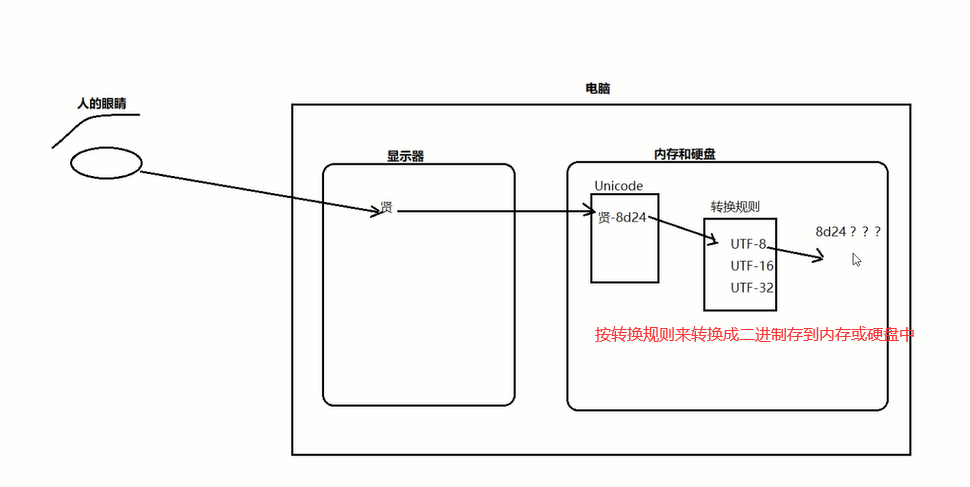
(1)UTF-32:Unicode编码的16进制码值直接换算为二进制存到计算机中,每个字符都用4个字节表示

(2)UTF-16:平时常用字符基本是2个字节表示,其余用4个字节表示。平时说的Unicode编码一般是UTF-16
(3)UTF-8:英文字符用一个字符表示,大部分中文用三个字节表示。这样做的目的是为了节省空间

 浙公网安备 33010602011771号
浙公网安备 33010602011771号