
SPSS Modeler相关问题
问题1:在SPSS Modeler 14.1调用了某些Statistics功能之后,原来的节点为什么无法正常工作?
答:Modeler 14.1 Fix Pack 1 及Fix Pack 2 已修复此问题,请下载安装。
问题2:SPSS Modeler Server在Unix环境安装时,是否一定要使用root权限?
答:是的,Modeler 15 版本之前,必须root权限安装Modeler Server,但是可以使用非根权限运行服务。若您正在使用的是15版本,可以参考IBM SPSS Modeler Server 15 for UNIX Installation Instructions手册以使用非跟权限安装。
问题3:为什么更新了SPSS Modeler为最新版本时,在运行某流文件时所需的时间更长了?
答:在之前版本的SPSS Modeler设置中,”SQL优化”可能出于关闭状态。在使用新版本SPSS Modeler时此项被打开,但是可能因为流文件与SQL转化过程中,数据库无法更快地解读转化后的SQL,反而给计算造成了负担。您可以尝试在合并等节点钟增加缓存,并精简优化数据流,从而达到提高运算速度的目的。
问题4:Modeler可以用同样的模型和输入字段,一次对多个目标字段做分析吗?因为待求目标很多,手动建立多个流不现实。
答:对于时间序列模型来说,是可以一次预测多个变量,对于其他模型,可以通过script来实现。
问题5:Modeler 14.1 关联分析中GRI算法没有了?
答:这个是老算法,14.0之后已经不被采用了。
问题6: 在使用Modeler过程中遇到unicode_value函数的使用问题,unicode_value(to_string(sex)) ,sex字段本身是数值字段,也尝试其它办法,不过基本都是显示错误,请问下这个函数具体怎么使用?
答:关于这个函数的使用,需要注意两点,一个是函数参数只能是一个字符,比如unicode_value(`a`),另外,字符的引号是键盘左上角第二行第一个的引号。
问题7: 做流失预测时,常用的算法有哪些,用哪个更好?
答:因为流失预测的结果只有两种,流失(1)或者不流失(0),所以常用的二元预测方法都适用:如决策树、Logistic回归、判别分析、神经网络、支持向量机等。一般来说Logistic回归的运用更普遍一些,但是一般在实践中会把每种模型都尝试一下,然后比较哪种模型的预测结果更好。
具体的方法是:将数据分为训练样本和测试样本(如70%:30%)。用训练样本来用不同的算法训练模型,之后将测试样本代入到训练好的模型中,评估预测的效果。
问题8: 如何用提升(lift)指标评估二元预测的结果?
答:除此以外,提升(Lift)也是一个很好的评价指标,特别是在预算有限的情况下。比如(因为预算或其它原因)企业只对最有可能流失的那10%的客户有兴趣,那么这时将概率在前10%的样本预测为Positive,剩余90%预测为Negative。那么在10%的阀值下:提升=(TP/P) / (P/(P+N)),也就是前10%的样本中Positive样本所占比例除以Positive样本在整体样本中的比例。
比如总样本有1000个,包括900个Negative样本和100个Positive样本。假设Positive概率最高的那100个样本中,实际包括了40个Positive样本和60个Negative样本。这时的提升= (40/100) / (100/1000) = 4.0。
提升表明了预测模型优于随机选择的倍数。以上面的例子为例,模型选择出来的10%的样本所包括Positive样本数量是随机选择出来的10%的样本所包括Positive样本数量的4倍。
问题9: 购物篮数据怎么分析?怎么运用分析的结论?
关联规则是最常用的购物篮数据的分析算法。一个最有名的例子即是沃尔玛的“啤酒与尿布”的故事。如购买牛奶的顾客有80%也会买面包,购买了铁锤的顾客有70%也买了钉子。典型的关联规则算法包括:Apriori、Carma以及Sequence(在Modeler中均有相关的节点)。
对于零售企业而言,关联规则的结果可以用于产品推荐及精准营销(购买了该产品的顾客同时也会购买……;电子邮件促销等);对超市这类有固定营业场所的商家而言可以对产品的摆放进行指导。
问题10: 在使用决策树时为什么需要对决策树进行修剪?
首先想想一下我们熟悉的一元回归模型,假设有N个观测值,那么总是可以用N-1次线性模型来完美拟合:比如有两个观测值的情况下,可以用一条直线来完美拟合这两个点;有三个观测值的时,可以用一条二次曲线……。我们训练模型的目的并不是完美地拟合这批训练样本,而是为了预测更一般性的数据。然而随着指数的增加,模型会变得越来越贴近这批特定的训练样本,而失去了一般性,导致用来预测一般性的数据时的效果反而变差。这种现象叫做“过拟合”。
同样地,在决策树中,随着决策树的生长,其对数据总体规律的代表程度会有一个先升后降的过程,降低是因为越来越贴近于训练样本而失去了一般性。为了解决“过拟合”的问题,我们需要用修剪的方法来调整决策树。具体的方法是:用训练样本训练完整的决策树后,用修剪的方法生成多个修剪后的决策树(修剪的层数不同);然后将测试样本代入到这些决策树模型中,寻找预测效果最好的那个树最为最终的决策树模型。
问题11: Modeler中能否使用K折叠的交叉验证?
答: 可以,在KNN节点中的设置项下,可以设置交叉验证。此外在C5节点的模型选项下,也可以设置交互验证。
问题12: 我能否对自己创建的流进行加密?
答: 可以,在保存节点对话框中,点击加密选项,勾选对文件加密,就可以输入密码并对模型加密。
问题13: 如何探索离散变量间的关联?
答:可以使用网络图分析事件同时出现的潜在关联。在图形节点类中选择网络节点,该图可以显示两个或更多符号字段的值之间,关系的紧密程度。其图形使用不同类型的线条显示链接,说明链接强度。如果有某个目标字段,可以使用导向网路,分别定义结束字段和源字段。在绘制出网络图后,通过调节阈值,可以隐去关联过弱或者关联过强的线。
问题14: 如何利用图形评估预测的结果?
答:可以使用评估节点,评估节点提供了一个评估并比较预测模型,以选择最适合模型的便捷方法。评估图表显示模型如何执行对特定结果的预测。评估图表的工作原理是:根据预测值及预测的置信度排序记录、将记录分割为大小相等的组(分位数)并按由高到低顺序为每个分位数绘制业务标准值。在散点图中,将以单独的线条显示多个模型。
通过将具体值或值的范围定义为匹配,处理结果。通常,匹配表示相关的某类别(如向顾客销售)或某事件(如某项医疗诊断)成功执行。您可以在对话框的“选项”选项卡上定义匹配标准,或使用以下描述的默认匹配标准:
• 标志输出字段是正向的,即匹配表现为 true 值。
• 对于名义输出字段,集合中的第一个值确定是否匹配。
• 对于连续输出字段,大于字段范围中点的值即为匹配。
一共有五种评估图表,每一种针对不同的评估标准:
1.收益图表
收益的定义是相对于全部匹配,发生于每个分位数中的匹配的百分比。其计算方法为(分位数中的匹配数量/全部匹配数量) × 100%。
2.提升图
提升将每个分位数中匹配记录的百分比与在全部训练数据中匹配的百分比进行比较。其计算方式为(在分位数中的匹配/在分位数中的记录)/(全部匹配/全部记录)。
3.响应图
响应即分位数中,匹配记录的比例。其计算方式为(分位数中的匹配/分位数中的记录)× 100%。
4.利润图
利润等于每个记录的收入减去该记录的成本。也就是说,分位数的利润就是位于该分位数内的所有记录的利润总和。这里假定收入仅应用于匹配项,但成本可应用于所有的记录。利润及成本都可以是固定的,也可以由数据中的字段决定。其计算方法为(分位数中所有记录收入的总和 − 分位数中所有记录成本的总合)。
5.投资回报图
投资回报 (ROI) 也需要确定收入和成本,从这一点上来说,它与利润相同。ROI 将分位数的成本和利润进行比较。其计算方法为(分位数利润/分位数成本)× 100%。
评估图表也可以累积,因此每个点等于相应分位数的值加上所有更高分位数的值。累积图表通常能够更好的表现模型性能,而非累积图则更有利于指出模型中可能存在问题的地方。
问题15:使用modeler server进行大数据量挖掘时,会用到缓存,然而数据流中使用缓存节点过多,可能导致流自动关闭,如何解决这种情况?
答:这时可以设置缓存的存储位置,将缓存文件暂时存放于空间较大的硬盘上,设置方式:在modeler server的安装目录的config文件夹下找到option.cfg文件,打开option.cfg文件,默认的缓存路径是空的,即temp_directory, "",需要填入新的路径,比如temp_directory, "C:/Temp"。
问题16:modeler数据流运行过程中,报错SPSS modelevaluation/menode无法评估模型,产生该错误的原因是什么,怎么解决?
答:这种情况是modeler安装目录下menode.dll文件损坏,可以将其他人机器上正常的文件拷贝到IBM/SPSS/Modeler/15/ext/bin/SPSS modelevaluation文件夹中覆盖原来的文件,即可。
问题17:精确度是评估二元预测的结果的一个很好指标吗?
答:二元的预测的真实数据与预测的结果都只有两种可能:Positive/Negative(1/0)。因此将真实数据与预测结果做成一个列联表,既是我们熟知的混淆矩阵。

- TP(True Positive):一个样本的真实值为Positive,被正确地预测值为Positive。
- TN(True Negative):一个样本的真实值为Negative,被正确地预测值为Negative。
- FP(False Positive):一个样本的真实值为Negative,被错误地预测为Positive。
- FN(False Negative):一个样本的真实值为Positive,被错误地预测为Negative。
精确度(ACC) = (TP+TN)/(TP+TN+FP+FN),即被正确预测的样本数所占的比例。在均衡样本的情况下(P与N的比例大致一样),精确度是一个不错的预测指标,简单易用。但是我们面对的往往是不均衡样本——如流失预测(或者欺诈检测),流失客户(欺诈客户)的比例一般远远小于未流失(非欺诈)客户。对于这种不均衡样本,精确度并不是一个很好的模型评价指标:比如真实的情况是90%的客户不流失,10%的客户流失;当模型将全部的客户都预测为不流失客户时,模型的精确度是90%,一个非常高的分数,但这样的模型是毫无意义的。
问题18:重新结构化和设为标志的区别?
答:重新结构化节点可用于根据名义字段或标志字段的值生成多个字段。新生成的字段可包含来自另一个字段或数值标志(0 和 1)的值。此节点的功能与设为标志节点类似,但更加灵活。使用这种节点,可以使用另一个字段的值创建任意类型的字段(包括数值标志)。随后,您可以对其他下游节点执行汇总或其他操作。设为标志节点允许您在一个步骤中汇总字段,因此如果要创建标志字段,使用设为标志节点更为方便。
问题19 : 针对连续型数据分箱一直是个头痛的问题,有没有可以自动分或者其他的做法呢?
答:在SPSS Statistics软件中,有一个最优离散化的菜单,进行离散化的。不过,它也是针对另外一个分类变量进行的。操作:菜单“转换”---“最有离散化”。
在IBM SPSS Modeler中的分箱节点里,也有最优化分箱选项的。功能和Statistics一致。
问题20 : Modeler软件,数据出现空值,如何快速过滤所有空值啊?
答:利用数据审核节点,在'生成'里选择数据质量高于OO%的。
问题21 : SPSS Modeler怎样与SQL Server连接?如何安装odbc驱动?要装SPSS Modeler server吗?
答:Modeler通过配置ODBC连接SQL,如果数据量不大的话,可以不安装Modeler server。配置ODBC的过程是:控制面板-ODBC数据源-添加-SQL server,然后填上SQL数据库的用户名和密码。
问题22 : SPSS Modeler做聚类分析时提示:字段指定的类型不足?
答:在建模节点之前加个类型节点,给字段指定类型。
问题23 : 用决策树 c5.0算法建模,可否用收益图来进行模型评价?收益图代表什么含义?
答:收益的定义是相对于全部匹配,发生于每个分位数中的匹配的百分比。其计算方法为(分位数中的匹配数量/全部匹配数量) × 100%。解读收益图: 累积收益图的线 从左至右的走势通常是从0% 到100%。优秀模型的收益图将陡升至100%,然后保持平直。无法提供有用信息的模型将呈对角线状,即从左下角到右上角(选择了包含基线后将显示类似图表)。
问题24 : 用神经网络模型进行预测,有一点不明白:就是利用modeler软件建模时,还需要对原始数据进行预处理?比如,标准化或归一化等处理。
答:神经网络和其他模型类似,需要大量对数据的准备和预处理;比如,由于神经网络要求数量变量,对于分类变量就要用许多二值变量来替换;多层感知器算法要求输入值是数值型的取值在[0,1]闭区间内,因此建模前要进行数据转换。
问题25 : 假设有一个数据集A有自变量x,应变量y。选好节点,完成建模;现有另一个数据集B有x,要用前面的模型做预测,应该如何操作,结果如何输出到数据集?
答:把数据集B替换数据集A,中间数据处理过程不变,建模得到模型(右上角模型列表)拖入数据流区域,将建模节点去掉,在模型节点后边连接表查看结果,或者连接excel表或数据库将结果导出。
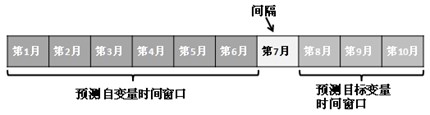
问题26 : 在流失分析数据挖掘应用中如何定义预测的输入变量(自变量)和预测目标变量(因变量)的时间窗口?
答:对自变量来说,进行流失分析的目的是希望客户流失之前发现他,在业务系统中,客户行为是连续发生的,选取分析数据时,取的时间过短,可能客户的行为受随机因素影响较大,数据不具有代表性,取时间过长,久远的历史数据不能反映客户最新的行为趋势,综合考虑数据的可获取性和有效性,建议取6个月的数据。对于因变量(是否流失)的数据窗口来说,为了使得到的预测结果具有前瞻性,又要留出营销时间,流失定义的时间窗口与自变量的定义时间窗口间隔一个月,再考虑流失定义一般需要3个月的观察期,具体预测自变量和目标变量的时间窗口如图所示:
问题27:输入为Excel时,有些列的内容在Modeler中被误认为空值或无效值怎么办?
答:可以在Modeler中,先把Excel文件导出为csv文件,再把此csv文件作为输入源输入模型中。
问题28:如何为原数据增加一列从2013-1-1到2013-3-31的日期?
答:可以利用用户输入节点生成日期,然后和原数据合并。

问题29:为什么我的流不能保存?
答:在Modeler15.0中,由图形或其他生成的选择节点会导致流不能保存。如果碰到此问题,需要将Modeler升到15.1或15.2即可。
问题30:完成有输入的时间序列时,为何在生成包含预测值的时间散点图时会报错?
答:对于有输入的时间序列,由于目标值是根据输入值得到的,因此在对目标值进行预测时,需要先填充输入在未来一段时间内的数值,然后再绘制时间散点图。


