
python基础 day19 正则表达式及re模块
-
模块和实际工作之间的关系
-
re模块和正则表达式的关系
-
有了re模块就可以在python中操作正则表达式
-
-
正则表达式 ( 重要五星)
-
re模块——>regex正则表达式
-
什么是正则表达式
-
一套规则——匹配字符串的规则
-
-
能做什么
-
1、检测一个输入的字符串是否合法——》web开发项目、表单验证
-
用户输入一个内容,提前做检测,能够提高程效率和减轻服务器的压力
-
-
2、从一个大文件中找到所有符合规则的内容 ——》日志分析,爬虫
-
能够高效的从一大段文字中快速找到符合规则的内容
-
-
-
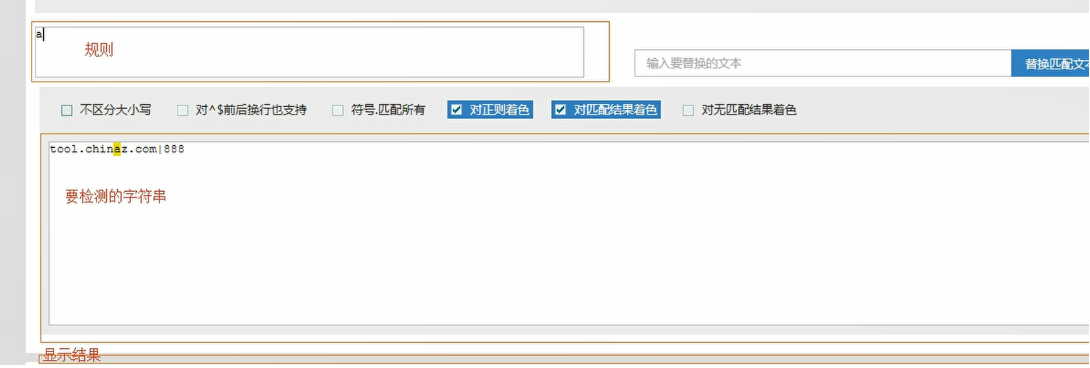
-
正则规则
-
所有的规则中的字符就可以刚好匹配到字符串中的内容
-
-
-
字符组
-
描述的是一个位置上能出现的所有可能性
-
接受范围,可以描述多个范围,连着写就可以
-
[abc] 一个中括号只表示一个字符位置
-
代表意思:匹配a或者匹配b或者匹配c
-
[0-9] 表示0到9范围内的数字,根据ascii码来进行匹配
-
[a-z] 或者 [A-Z] 或者 [a-Z]
-
范围只能是从小到大
-
[0-9] \d 表示匹配所有的数字
-
[a-zA-Z] 大小写字母
-
[0-9a-z]
-
[0-9a-zA-Z]
-
-
元字符定义:
-
在正则表达式中能够帮助我们表示匹配内容的符号都都市正则中的 元字符
-
-
[0-9] ——》\d 表示匹配所有的数字 digit
-
[0-9a-zA-Z]——》\w 表示匹配数字字母下划线 word
-
空白(空格/tab/enter)——》 \s表示所有空白
-
空格——》空格
-
tab ——》 \t
-
enter ——》 \n
-
\W 非数字字母下划线
-
\D 非数字
-
\S 非空白符
-
[\d\D] [\s\S] [\w\W] 代表匹配所有
-
.(点) 匹配除换行符的所有字符
-
[^] 代表非
-
^ 匹配一个字符组开始
-
$ 匹配一个字符组结尾
-
a表达式|b表达式 代表匹配a或者b表达式,
-
如果匹配a成功后,就不继续匹配
-
所有如果两个规则有重叠的地方,总是把长的规则放在前面
-
-
() 约束 | 描述的内容的范围
-
www.oldboy.com|www.taobao.com|www.jd.com|
-
www.(oldboy|taobao|jd).com

-
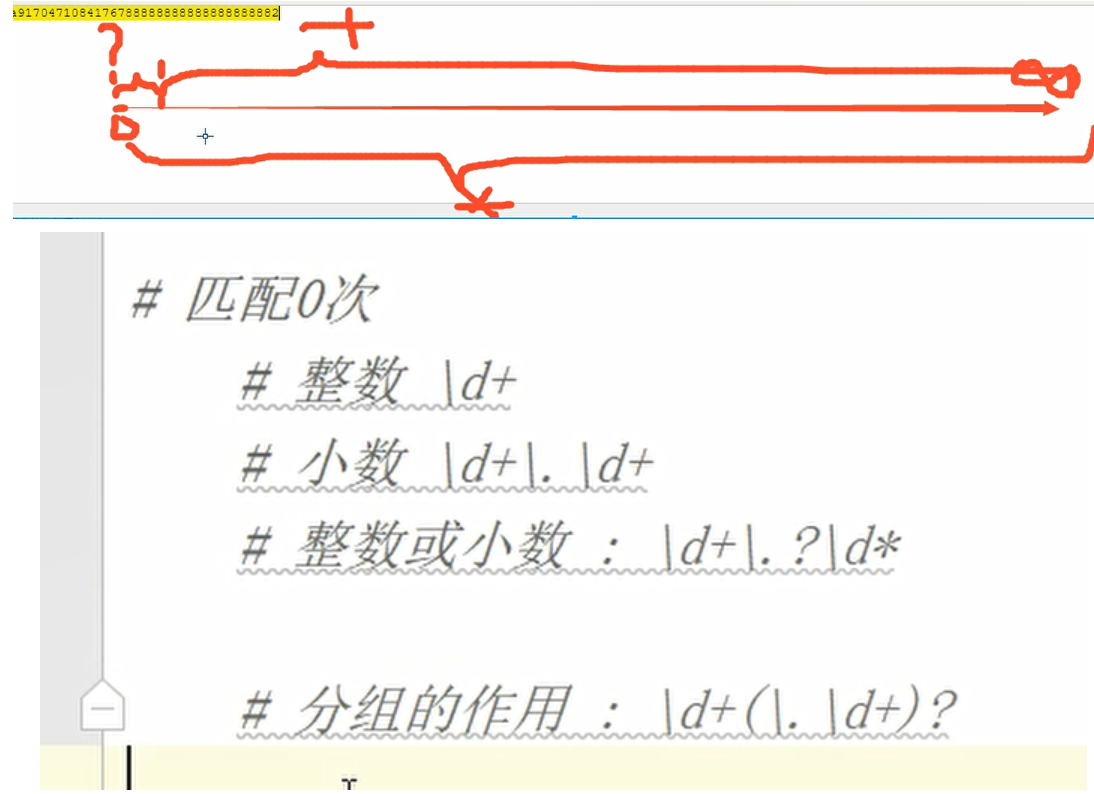
量词
-
定义:
-
{n} 表示匹配n次
-
{n,} 表示匹配至少n次
-
{n,m} 表示至少匹配n次,至多匹配m次
-
? 表示匹配 0 次或 1 次 {0,1}
-
+表示 1 次或多次 {1,}
-
*表示 0 次或多次 {0,}
-
-
练习题:匹配一个电话号码
#第一位 1 第二位 3-9 一共11位
1[3-9]\d{9}
^1[3-9]\d{9}$
贪婪匹配
-
定义:在量词范围允许的情况下,尽量多的匹配内容
.*?x :表示匹配任意字符,(任意多次数,遇到最后一个x就停下来) -
-
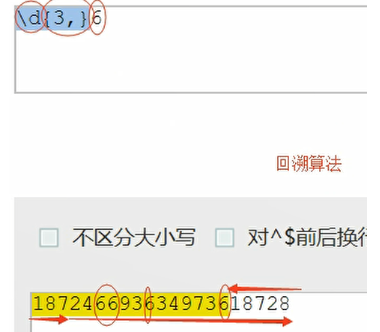
非贪婪匹配
\d{3,}?6
.*?x :表示匹配任意字符,(任意多次数,但是一旦遇到x就停下来)
转义符
-
原本有特殊意义的字符,到了表达它本身的意义的时候,需要转移
-
有一些有特殊意义的内容,放在字符组中,会取笑他的特殊意义
-
[.] 只表示点
-
[().+?] 只表示本身的意义
-
二、总结



^[1-9]\d{14}(\d{2}(\d|x))?$
([1-9]\d{16}[0-9x]|[1-9]\d{14})$
三、re模块
import re
ret = re.findall('\d','121638126fksdjdjdh213')
#findall 按照完整的正则表达式匹配,只是显示小括号内匹配到的内容
ret_1 = re.findall('\d(\d)\d','121638126fksdjdjdh213')
print(ret)
print(ret_1)
ret = re.search('\d\d\d','121638126fksdjdjdh213')
#findall 按照完整的正则表达式匹配,显示也是显示匹配到的第一个内容,但是我们可以通过
#使用group方法传递参数来获取具体分组中的内容
ret_1 = re.search('\d(\d)\d','121638126fksdjdjdh213')
print(ret)
print(ret.group())
print(ret_1) #<_sre.SRE_Match object; span=(0, 3), match='121'>
if ret and ret_1:
print(ret_1.group())
print(ret_1.group(1))

四、什么是爬虫
-
通过代码获取一个网页的源码
-
-
import re
with open("douban.html",encoding="utf-8") as f:
content = f.read()
ret = re.findall(' <img src=.*? alt=(.*?) rel=.*? class=.*? />',content)
print(ret)
-
-
-
