

python基础 day18 模块回顾
-
自定义模块
-
模块是什么
-
模块就是一个py文件
-
-
为什么要有模块?
-
拿来即用,提高开发效率。
-
便于管理和维护。
-
什么是脚本
-
脚本就是py文件,长期保存代码的文件
-
模块的分类
-
内置模块:python解释器自带的 time 、datetime os、sys、 hashlip等等
-
第三方模块:一些大牛写的 pip install 模块名称 beautifil_soup、Django
-
自定义模块:自己写的一个py文件
-
-
import的使用
-
-
第一次引用模块,会先把模块内的代码执行一次,加载到内存中,下次引用会直接从内存中取,如果已经加载了,不在重新加载
-
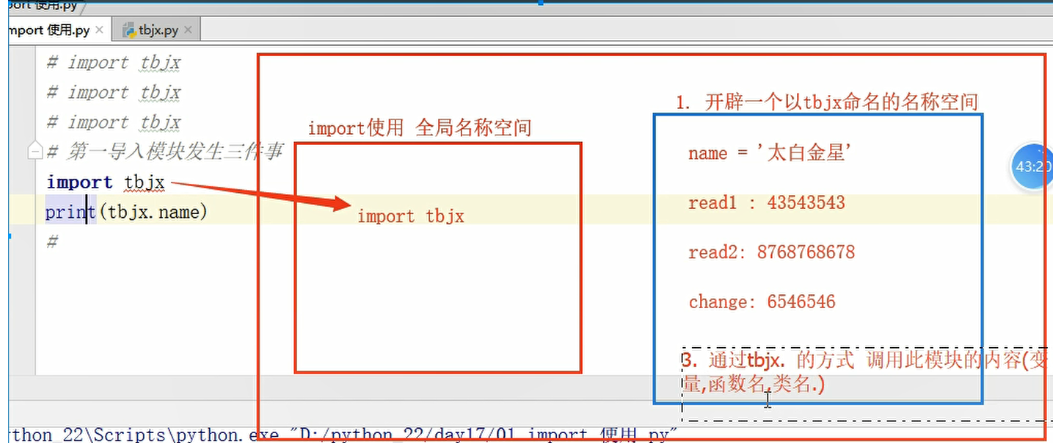
第一次导入模块执行的三件事
-
在内存中创建一个以tbjx命名的名称空间
-
执行此名称空间所有可执行的代码
-
通过tbjx.的方式引用模块内的代码
-
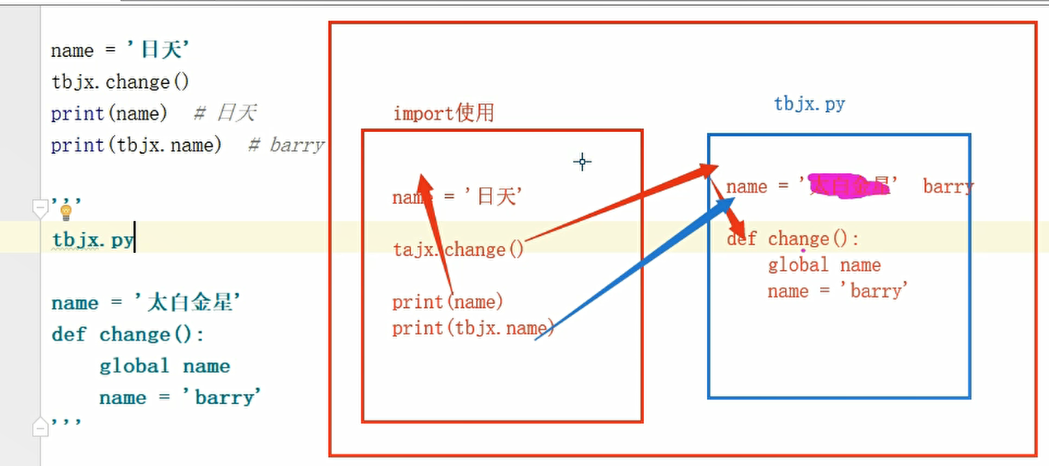
被导入模块有独立的名称空间
-
-
-
为模块起别名
-
-
简单便捷
-
有利于简化了代码

-
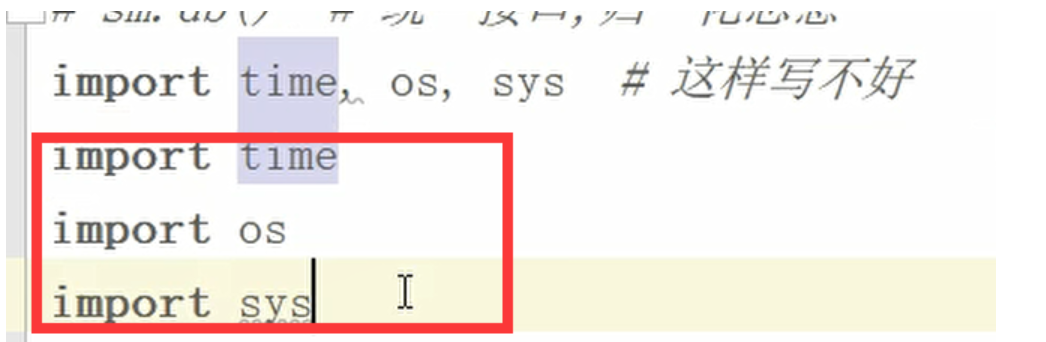
导入多个模块
-
-
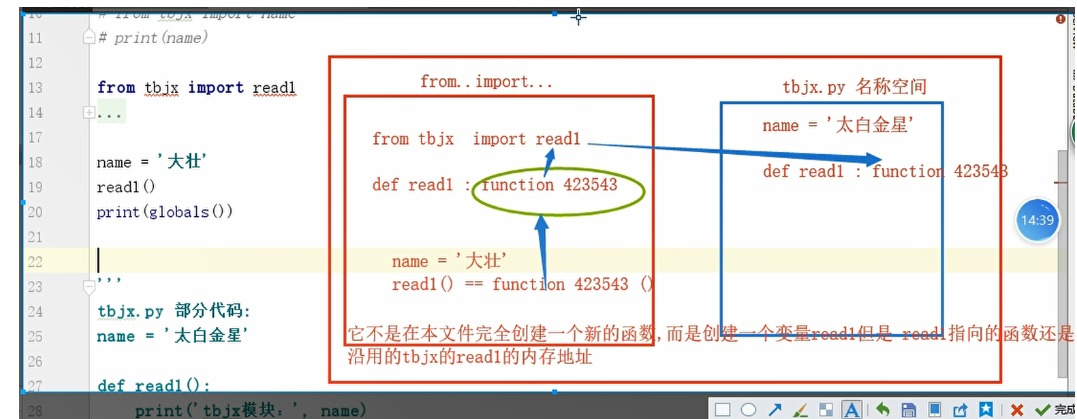
form 。。。。import。。。
-
form 。。。。import。。。的使用
-
form 。。。。import。。。与import对比
-
-
form 。。。。import。。。 用起来更方便
-
form 。。。。import。。。容易与本文件内的变量产生冲突

-
一行导入多个
-
form 。。。。import *
-
模块循环导入的问题
-
py文件的两种功能
-
-
自己用(脚本)
__name__ == __main__ -
被被人引用(模块使用)
__name__ == 模块名称-
模块的搜索路径
-
-
先从内存中寻找有没有已经命名的模块名称空间
-
它会从内置模块中找,time、datetime、os、sys等等
-
它从sys.path中找寻
-
json与pickle模块
-
序列化
-
-
将一种数据结构(list、str、tuple、dict、get)转换成一种特殊的序列
-
反序列化
-
-
将这个特殊的序列反转会原来的数据结构
-
特殊的序列:(特殊的字符串,bytes)
-
为什么要有序列化模块
-
序列化——> bytes:文件的存储,网络的传输

网络传输:
l1 = [i for i in range(1000)]
print(l1)
# print(lst.encode("utf-8")) # 'list' object has no attribute 'encode'不能直接转
#先转成str在转换
s1 = str(l1)
print(s1)
b1 = s1.encode("utf-8")
print(b1)
#接收到后进行反系列化
s2 = b1.decode("utf-8")
print(s2)将数据结构转换成str可以,但是在转换回去,现阶段不行
我们急需一个特殊的字符串,将所有的数据结构可以转换成这个特殊的字符串。并且还可以转换回去。
-
json:
1. 不同语言之间可以使用
2. 缺点L支持的python数据类型比较少: dict,list, tuple,str,int, float,True,False,None
-
pickle:
-
只能是Python语言遵循的一种数据转化格式,
-
只能在python语言中使用。
-
支持
-
Python所有的数据类型包括实例化对象。
-
-
json序列化

-
序列化模块的分类
-
-
hashlip模块
-
-
包含很多的加密算法MD5
-
用途
-
密码加密
-
文件的校验
-
-
用法
-
将bytes类型字节转换成固定长度的16进制字符串
-
不同的bytes利用相同的算法(md5)转换的结果一定不同
-
相同的bytes利用相同的算法(md5)转换的结果一定相同
s1 = "fdhaskjhfdsak老板都会附件是看"
import hashlib
ret = hashlib.md5()
ret.update(s1.encode("utf-8"))
print(ret.hexdigest()) #ca82ece99fac5f6649293c109e5172c0
#md5
#加盐
s1 = "fdhaskjhfdsak老板都会附件是看"
import hashlib
ret = hashlib.md5('太白金星'.encode("utf-8"))
ret.update(s1.encode("utf-8"))
print(ret.hexdigest()) #ca82ece99fac5f6649293c109e5172c0
#md5
#动态加盐()切片
s1 = "fdhaskjhfdsak老板都会附件是看"
import hashlib
ret = hashlib.md5('太白金星'[::2].encode("utf-8"))
ret.update(s1.encode("utf-8"))
print(ret.hexdigest()) #ca82ece99fac5f6649293c109e5172c0
#md5

-
-
