RabbitMQ调研
Swarm集群上部署RabbitMQ镜像队列集群
Authored by 付建钧
## 1.为什么使用RabbitMQ(1)解耦:实现了消费者与生产者之间的解耦
(2)异步:将消息写入消息队列,非必要的业务逻辑以异步的方式运行,可以加快业务的相应速度
(3)削峰:在高并发的业务场景下,消息队列可以使同步访问变为串行访问达到限流的目的,防止数据库连接过载
(4)持久化:拥有持久化机制可以防止业务数据丢失,保障了数据冗余安全
(5)可扩展:rabbitmq集群在性能瓶颈时可通过横向扩展节点来缓解
2.RabbitMQ技术架构
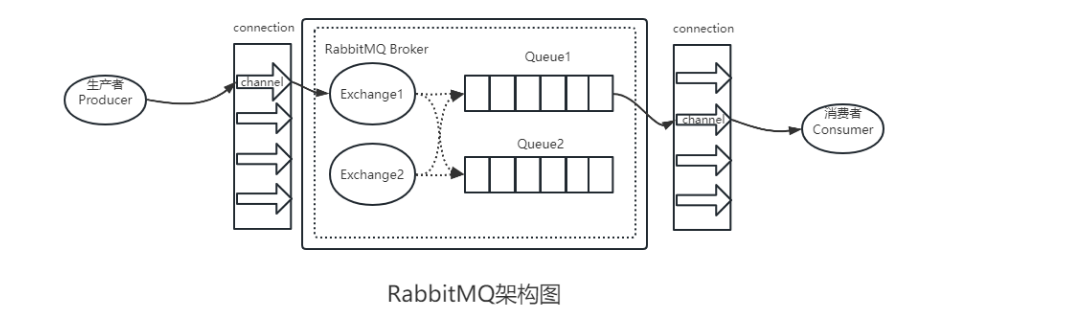
2.1元素解释
(1)生产者producer:发送消息到RabbitMQ的交换机exchange上
(2)交换机exchange:和生产者建立Connection(Broker)以及Channel进程用以接收生产者发来的消息并根据routing-key来将消息投递到对应的队列queue中
(3)消费者consumer:监听RabbitMQ中的队列queue消息并获取消费
(4)队列queue:Exchange将消息发送到指定的队列中,由队列queue来与消费者交互
(5)Broker:由RabbitMQ搭建的服务器节点
(6)绑定Binding:Exchange和Queue之间的绑定关系
(7)连接Connection:生产者/消费者与broker之间建立的TCP长连接
(8)信道Channel:建立在Connection上的虚拟连接,用于传输AMQP指令(节点之间),引入信道概念而不直接使用Connection的TCP连接是为了TCP复用,TCP的创建和开销都特别大,峰值会造成性能瓶颈;而引入信道,一条线程一条信道,一次TCP连接可容纳无限信道,不会造成性能瓶颈
(9)镜像队列Mirror queue,实现高可用,当Master队列宕机可将Slave队列选举为Master队列实现高可用
(10)策略Policy:用于管理RabbitMQ特性的一组规则,以Vhost为限制范围
(11)Vhost:Mini版Rab服务器,拥有独立队列、绑定、交换机和权限控制等,与其他Vhost逻辑分离
3.对比 现有公司使用的RabbitMQ3.7.15与3.12.0 之间的区别
3.7--》3.8 (错误修复/开始支持Erlang23/性能优化)
3.8--》3.9 (更改了公共许可证/修复了几个安全漏洞补丁/引入了对Erlang24的支持/)
3.9--》3.11 (修复支持Erlang25兼容性/管理插件错误/)且3.9、3.10已经停止社区支持了
3.11--》3.12 (支持百万并发连接/端到端延迟降低50%-70%/吞吐量提高30%-40%/降低内存使用率)
4.采用镜像队列的优势与劣势
普通队列:
1、优势:每个节点上的内部元数据都是一致的,队列只存储在一个节点上,充分地利用了存储空间,缓解了集群对消息的积压能力
2、劣势:每个队列仍只存在一个rabbitmq节点上,所有对队列的操作都会有访问节点将请求路由到队列所在节点上进行操作,如果队列所在节点出现故障,那么这个节点上所有队列都不再可用。
镜像队列:
1、优势:队列、交换机、元数据、队列数据都会在每一个rabbitmq节点之间同步
2、优势:能够提供高可用服务,包含一个主master节点和若干个slave节点,数据同步正常情况下保持一致(针对队列)
3、优势:能够通过配置脑裂自动恢复参数autoheal进一步实现高可用(针对节点)
4、优势:可以自主定义队列master所在的rabbitmq节点,使消费者可以连接到最近的节点,提高响应速度
4、劣势: 当存在大量消费者时,性能受限;系统性能占用较多,需要更多的计算资源和存储空间
5、劣势:比普通集群消耗更多的网络带宽,在网络延迟较大的情况下容易出现广播ack确认慢的问题
6、劣势:同步阻塞,如果要同步消息,则需要阻塞整个队列使不可用,在队列非常长的时候会消耗很多时间,也会占用大量内存资源
5.新rabbitmq架构优势
- (存储)持久化消息:节点崩溃不会导致附加在队列上的消费者丢失其订阅的信息且任何匹配该队列绑定信息的新消息也不会消失,都会持久化到硬盘上,节点重启时可以再次获取到该消息。在极端情况下节点无法重启也可以通过备份挂载出来的文件夹数据来进行数据的恢复,从而避免数据的丢失
- (队列)镜像队列:在可用性要求高,对连续性要求高的业务场景下,镜像队列一主多从的架构可以保障非极端情况下队列数据的多重副本,
- (节点)集群自动化处理脑裂:针对集群产生的脑裂,采用autoheal策略集群会根据客户端连接量和节点树依次权衡选出获胜分区并重启另一分区节点,相比人工手动重启会更优,尤其是在所有队列都做持久化的基础上
6.swarm集群中的docker-compose文件
version: '3.6'
services:
rabbitmq1:
image: rdsource.tp-link.com:8088/rabbitmq:management
hostname: mirror_rabbit1
ports:
- 16672:15672
- 6672:5672
configs:
- source: rabbitmq.conf
target: /etc/rabbitmq/rabbitmq.conf
volumes:
- type: volume
source: mirror_rabbit1_data
target: /var/lib/rabbitmq
- type: volume
source: mirror_rabbit1_logs
target: /var/log/rabbitmq
environment:
- RABBITMQ_DEFAULT_USER=root
- RABBITMQ_DEFAULT_PASS=root
- RABBITMQ_ERLANG_COOKIE=CURIOAPPLICATION
- RABBITMQ_NODENAME=mirror_rabbit1
deploy:
replicas: 1
placement:
constraints:
- node.hostname == apptest4-ip
networks:
fac-network2:
aliases:
- mirror_rabbit1
rabbitmq2:
image: rdsource.tp-link.com:8088/rabbitmq:management
hostname: mirror_rabbit2
ports:
- 16673:15672
- 6673:5672
configs:
- source: rabbitmq.conf
target: /etc/rabbitmq/rabbitmq.conf
depends_on:
- rabbitmq1
volumes:
- type: volume
source: mirror_rabbit2_data
target: /var/lib/rabbitmq
- type: volume
source: mirror_rabbit2_logs
target: /var/log/rabbitmq
environment:
- RABBITMQ_DEFAULT_USER=root
- RABBITMQ_DEFAULT_PASS=root
- RABBITMQ_ERLANG_COOKIE=CURIOAPPLICATION
- RABBITMQ_NODENAME=mirror_rabbit2
- CLUSTERED=true
- CLUSTERED_WITH=mirror_rabbit1
deploy:
replicas: 1
placement:
constraints:
- node.hostname == apptest5-ip
networks:
fac-network2:
aliases:
- mirror_rabbit2
rabbitmq3:
image: rdsource.tp-link.com:8088/rabbitmq:management
hostname: mirror_rabbit3
ports:
- 16674:15672
- 6674:5672
configs:
- source: rabbitmq.conf
target: /etc/rabbitmq/rabbitmq.conf
depends_on:
- rabbitmq1
volumes:
- type: volume
source: mirror_rabbit2_data
target: /var/lib/rabbitmq
- type: volume
source: mirror_rabbit2_logs
target: /var/log/rabbitmq
environment:
- RABBITMQ_DEFAULT_USER=root
- RABBITMQ_DEFAULT_PASS=root
- RABBITMQ_ERLANG_COOKIE=CURIOAPPLICATION
- RABBITMQ_NODENAME=mirror_rabbit3
- CLUSTERED=true
- CLUSTERED_WITH=mirror_rabbit1
deploy:
replicas: 1
placement:
constraints:
- node.hostname == apptest6-ip
networks:
fac-network2:
aliases:
- mirror_rabbit3
networks:
fac-network2:
external: true
volumes:
mirror_rabbit1_data:
mirror_rabbit1_configs:
mirror_rabbit1_logs:
mirror_rabbit2_data:
mirror_rabbit2_configs:
mirror_rabbit2_logs:
mirror_rabbit3_data:
mirror_rabbit3_configs:
mirror_rabbit3_logs:
configs:
rabbitmq.conf:
external: true
7.配置configs
因为本文章使用了docker-compose配置的configs参数,所以需要使用docker config create rabbitmq.conf rabbitmq.conf来生成外源config
生成的config可以使用docker config ls来查看
可以使用以下命令对config进行base64解码
docker config inspect -f '{{json .Spec.Data}}' rabbitmq.conf | cut -d '"' -f2 | base64 -d
8.rabbitmq.conf 配置节点信息以及集群信息
8.1注意:rabbitmq集群针对于集群脑裂恢复的配置是cluster_partition_handling = autoheal
这个参数可以使集群在发生脑裂时自动重启不在分区里的节点
#loopback_users.guest = false
listeners.tcp.default = 5672
management.listener.port = 15672
management.listener.ssl = false
log.file.rotation.date = $D0
log.file.rotation.count = 5
total_memory_available_override_value=4G
vm_memory_high_watermark.relative = 0.4
cluster_partition_handling = autoheal
## Make clustering happen *automatically* at startup. Only applied
## to nodes that have just been reset or started for the first time.
##
## Relevant doc guide: https://rabbitmq.com//cluster-formation.html
##
##If peer discovery isn't configured, or it fails, or no peers are reachable, a node that wasn't a cluster member in the past will initialise from scratch and proceed as a standalone node.
##If a node previously was a cluster member, it will try to contact its "last seen" peer for a period of time. In this case, no peer discovery will be performed. This is true for all backends.
cluster_formation.peer_discovery_backend = rabbit_peer_discovery_classic_config
cluster_formation.classic_config.nodes.1 = mirror_rabbit1@mirror_rabbit1
cluster_formation.classic_config.nodes.2 = mirror_rabbit2@mirror_rabbit2
cluster_formation.classic_config.nodes.3 = mirror_rabbit3@mirror_rabbit3
9.在swarm集群上启动镜像队列服务
9.1配置Makefile文件
NAME = mirror_rabbitmq
deploy:
docker stack deploy --with-registry-auth --resolve-image always -c docker-compose.yml $(NAME)
remove:
docker stack rm $(NAME)
9.2执行make deploy
9.2.1查看镜像队列服务是否启动

10.各节点加入以节点1为主节点的集群
root@mirror_rabbit3:/# rabbitmqctl stop_app
Stopping rabbit application on node mirror_rabbit3@mirror_rabbit3 ...
root@mirror_rabbit3:/# rabbitmqctl reset
Resetting node mirror_rabbit3@mirror_rabbit3 ...
root@mirror_rabbit3:/# rabbitmqctl join_cluster mirror_rabbit1@mirror_rabbit1
Clustering node mirror_rabbit3@mirror_rabbit3 with mirror_rabbit1@mirror_rabbit1
root@mirror_rabbit3:/# rabbitmqctl start_app
Starting node mirror_rabbit3@mirror_rabbit3 ...

11.web管理界面配置镜像队列策略
11.1关于Operator Policy
11.2关于Policy
11.3policy之于operator policy
(1)相同点:二者都需要名称,正则参数和数据定义
(2)不同点,policy可以指定exchange或exchange和queue,而operator只能指定queue
也可以在节点命令行执行
rabbitmqctl set_policy mirror_rabbitmq "^" '{"ha-mode":"all","ha-sync-mode":"automatic"}'
在节点查看policy
rabbitmqctl list_operator_policies
12.主队列选择策略
rabbitmq集群的master主节点需要通过设置策略来决定,
12.1策略详解
HA Mode(键)
值存在三个:all/exactly/nodes
(1)all:镜像同步到集群队列的所有节点
(2)exactly:按个数同步到集群的一个或多个节点
(3)nodes:具体的节点名称
HA Sync Mode(键)
rabbitmq节点断连重连或者新加入集群之后通过这个参数控制来实现自动化同步,交换机、队列、元数据、队列内容都保持一致
默认是手动manual
13.验证镜像队列的功能
在mirror_rabbit3节点创建一个test3队列
点击创建的一瞬间截图 可以看到队列是只存在于mirror_rabbit3的

待创建新队列的ack经过一个循环传递到
14.网络分区判定参数 net_ticktime
RabbitMQ中与网络分区的判定相关的是net_ticktime这个参数,默认为60s。在RabbitMQ集群中的每个broker节点会每隔 net_ticktime/4 (默认15s)计一次tick(如果有任何数据被写入节点中,此节点被认为被ticked),如果在连续四次某节点都没有被ticked到,则判定此节点处于down的状态,其余节点可以将此节点剥离出当前分区。
当一个RabbitMQ集群发生网络分区时,这个集群会分成两个或者多个分区,它们各自为政,互相都认为对方分区的节点已经down,包括queues,bindings,exchanges这些信息的创建和销毁都处于自身分区内,与其它分区无关。如果原集群中配置了镜像队列,而这个镜像队列又牵涉到两个或者多个网络分区中的节点时,每一个网络分区中都会出现一个master节点,如果分区节点个数充足,也会出现新的slave节点,对于各个网络分区,彼此的队列都是相互独立的,当然也会有一些其他未知的、怪异的事情发生。当网络恢复时,网络分区的状态还是会保持,除非采取一些措施去解决他。
15.Rabbitmq消息传输
15.1rabbitmq消息架构
rabbitmq镜像队列集群节点之间通过AMQP信道传递消息,集群节点之间的架构为DAG(有向无环图),构建在此结构上的消息传递和数据内存分配是很快的。
rabbitmq镜像队列集群队列之间通过循环链表来传递消息,依靠GM模块(Guaranteed Multicast),其实现的是一种可靠的组播通信协议,能够保证组播消息的原子性。
实现原理为每个节点都会监控左右的节点,有节点新增则保证广播消息会复制到新节点,节点失效则由相邻节点接管传递广播消息,一个队列的master和slave会组成一个group保存在Mnesia中。Master进行操作后会发送一个广播沿着循环链表的链路进行传递,当他收到自己传递出去的消息后就知道操作命令同步到了所有的节点上。
个人理解:在rabbitmq镜像队列中,如果一个master队列进行操作,它会向gm_group(即给所有镜像队列发送)发送一次广播,收到消息的的slave队列会进行本地的操作,完成后再向gm_group发送一次ack广播,表示自己已经完成了操作。如果ack广播发送失败,那么广播重新发送。但是master队列并不需要等待所有slave队列的ack广播,只有收到达到majority的ack广播后才确认操作完成。因此,一个master队列进行操作只会发送一次广播和接收majority次ack广播,不会重复发送
16.镜像队列原理
16.1数据流传输
16.1.1客户端连接主节点
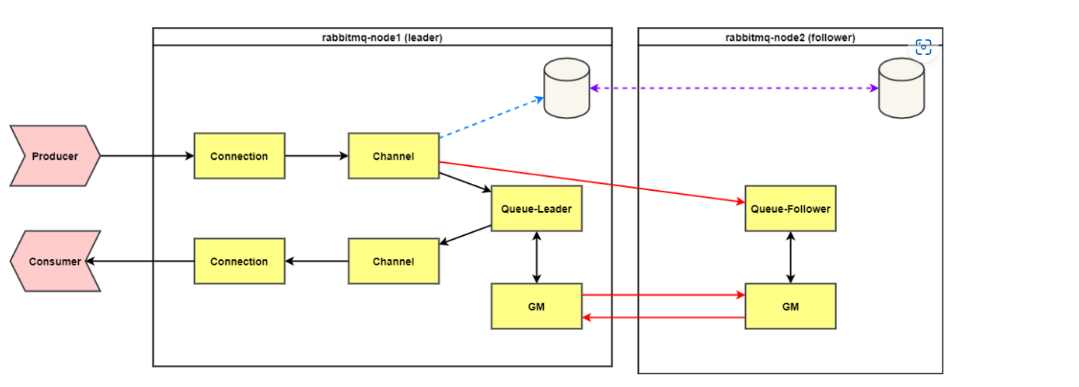
生产者/消费者连接到 RabbitMQ后,在 RabbitMQ 内部会创建对应的 Connection,Channel进程。Connecton进程从 socket上接收生产者发送的消息后将其投递到Channel进程,Channel根据消息发送的exchange与消息的routing-key,在内部数据库的路由表中,查找所有匹配的 Queue 的进程 PID,然后将消息投递到Queue的进程中。在镜像队列的情况下,Channel进程除了将消息发送给Master队列外,还会将消息发送给所有的slave队列,而slave队列都在远端节点上,因此这里就多了一次网络交互。
镜像队列的Master收到消息后,需要将消息同步给所有的slave。RabbitMQ采用GM(组播)算法实现,镜像队列中的Master和所有Slave都会发送一次消息和接收一次消息,同时还会发送一次对消息的ACK,和接收一次消息的ACK
16.1.2客户端连接从节点
如果生产者和消费者连接的是从节点,由于镜像队列的机制只有主节点向外提供服务,所以镜像队列的消费是需要由node2的队列接受/消费消息
17.手动处理网络分区
为了从网络分区中恢复,首先需要挑选一个信任的分区,这个分区才有决定Mnesia内容的权限,发生在其他分区的改变将不被记录到Mnesia中而直接丢弃。手动恢复网络分区有两种思路:
停止其他分区中的节点,然后重新启动这些节点。最后重启信任分区中的节点,以去除告警。关闭整个集群的节点,然后再启动每一个节点,这里需确保你启动的第一个节点在你所信任的分区之中。
rabbitmqctl stop_app
rabbitmqctl start_app
(禁止操作)rabbitmqctl reset 此操作仅可以在全新节点加入RabbitMQ集群之前可以执行,其余不得执行
18.自动处理网络分区
(1)autoheal
在autoheal模式下,当认为发生网络分区时,RabbitMQ会自动决定一个获胜的(winning)分区,然后重启不在这个分区中的节点以恢复网络分区。一个获胜的分区是指客户端连接最多的一个分区。如果产生一个平局,既有两个或者多个分区的客户端连接数一样多,那么节点数最多的一个分区就是获胜的分区。如果此时节点数也一样多,将会以一种特殊的方式来挑选获胜分区。
在外部挂载的rabbitmq.conf中声明如下参数
cluster_partition_handling = autoheal
(2)ignore 默认参数
网络分区的时候,不做自动处理,即需要手动处理
(3)pause_minority
集群中的节点检测到某些节点down了,会判断自己是否属于小于等于集群一半节点数,如果属于少数则会关闭app,此时erlang虚拟机是运行的,然后每秒会检测一次其它分区的连通性,如果连通正常,则启动app,集群恢复正常。因为这个原因,所以集群节点为2或者偶数时,不适合用此配置,可能会造成俩个分区全部关闭的情况
cluster_partition_handling = pause_minority
(4)pause_if_all_down
在pause-if-all-down模式下,RabbitMQ会自动关闭不能和list中节点通信的节点,如果一个节点与list中的所有节点都无法通信时,关闭其自身,如果list中的所有节点都down时,其余节点是正常的话,也会根据这个规则关闭其自身,此时集群中所有的节点会关闭。如果某个节点可以和list中的节点恢复通信,那么会启动其自身的RabbitMQ应用,慢慢的集群可以恢复。
cluster_partition_handling.pause_if_all_down.nodes.[节点数字] = rabbit@xxx
