Web工作流程
前言
最近在学习web安全方面相关的知识,小白一枚,也是从基础开始学起吧,希望可以把所学的进行总结写到博客里,以前学习的时候没有总结的习惯,不太会系统的处理知识,现在希望可以学着进行总结,总结的好处不言而喻。当然,也希望各位大牛看到有不合适的地方及时指出,欢迎大家来进行交流学习。
web的基本工作流程
首先,我们先来思考一下我们平常在上网浏览网页时候的场景,大致就是打开一个web浏览器,输入某一个网站的地址,然后转到该网址,在浏览器中得到该网址的页面。从这个场景中我们可以抽象出来几个基本对象,我们(用户)、web浏览器(客户端)和发送过来页面的地方(服务端),这些对象其实就是整个web工作流程中的重要组成部分。
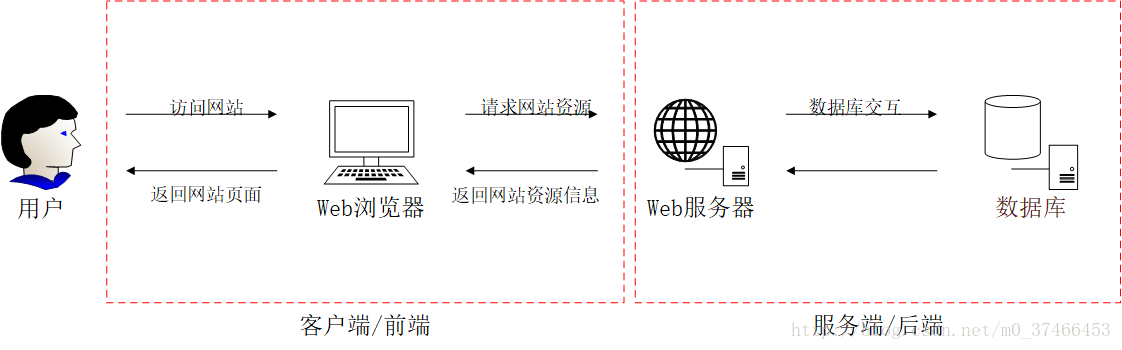
为了加强理解,其实可以将这个工作流程看做去吃饭时点餐的流程,web浏览器就是服务员,而服务端就是厨房。你给服务员说你要点什么菜,然后服务员将你点的菜端上来,具体厨房里是怎么忙活的也并不知道,其实web服务器就相当于厨师,有着各种各样的技能,根据你的成菜要求,为你进行服务,数据库在这里可以认为是个菜窖,需要什么菜去拿什么菜。
web中的一些基本概念
HTTP
HTTP协议(Hyper Text Transfer Protocol,超文本传输协议)是用于从web服务器传输超文本到本地浏览器的传输协议,是因特网中的“多媒体信使”。它可以使浏览器更加高效,使网络传输减少。它不仅保证计算机正确快速地传输超文本文档,还确定传输文档中的哪一部分,以及哪部分内容首先显示(如文本先于图形)等。同时,HTTP使用的是可靠的数据传输协议,即使是来自于地球另一端的数据,它也可以确保数据在传输的过程中不会丢失和损坏,保证了用户在访问信息时的完整性。HTTP是互联网上应用最为广泛的一种协议,后面还会介绍其他的互联网常用协议(https,ftp,file,mailto等)。
按照上述点餐流程理解的话就是厨师具备煎、炒、烹、炸、溜、爆、煸、蒸、烧、煮等多种烹调技法,你需要告诉厨师这道菜怎么做。
web客户端和服务端
web服务器是web资源的宿主,每天都有数以亿计的图片、HTML页面、视频、音频等资源在互联网上传输,而这些资源信息都是存储在web服务器(由于web服务器使用的是HTTP协议,所以也常常被称作HTTP服务器)上的。如果客户端向服务器发送HTTP请求,服务器会在HTTP响应中回送所请求的数据以及其他一些数据信息,包括对象,对象类型,对象长度等。
最常见的web客户端就是web浏览器,web浏览器向服务器请求HTTP对象,并将这些对象显示在你的屏幕上。其他的客户端还有“网络蜘蛛”(spiders)、“web机器人”(Web robots)等。这些客户端还被称作Agent代理,可以代表用户发起HTTP请求,后面提到的“网络蜘蛛”、“web机器人”都是自动代理,可以在无人监视的情况下,自动发起HTTP请求并获取相应内容,也就是我们常说的“网络爬虫”。
URI
Web上可用的每种资源 HTML文档、图像、视频片段、程序等,均由一个通用资源标识符(Uniform Resource Identifier, 简称”URI”)进行定位。这个就像是快递地址一样,快递小哥根据你的地址才能找到你你给你快递,然后你返回给快递小哥一个签收单,而这个地址在世界范围内唯一标识并定位资源信息。
给定了URI,HTTP就可以解析出来对象,URI有两种形式——URL和URN。
URL
统一资源定义符(Uniform Resource Locator)是资源标识符最常用的形式,它提供了一种定位因特网上任意资源的手段。URL精确地说明了某资源的位置以及如何去访问它。

URL的语法会随着方案的不同而有所变化,但都遵循一个通用的语法规则。
大多数URL方案的语法都遵循由这9个部分构成的通用格式上,但是几乎没有URL全部包含了这些组件。
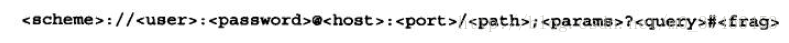
下面对这些组件进行解释说明

正如前面所说几乎没有哪个URL包含了全部组件,这其中最重要三个部分是方案(scheme)、主机(host)和路径(path)。
URN
URL是个强有力的工具,它提供了一种可以在各种互联网协议间共享的统一命名机制,这大大简化了复杂的互联网世界。但是它并不完美,它表示的是实际的地址,而不是准确的名字,所以仔细思考会发现,如果我要请求的这个资源被移走了呢?也就是说快递小哥送快递时,发现收快递方搬家了,这就很懵逼了,那么这个URL也就没用了,没法定义资源位置了。
所以为了应对这个问题,IETF小组已经对一种叫做统一资源名(Uniform Source Name)的新标准进行了研究,无论对象资源被搬移到哪个地方,URN都能为对象提供一个稳定的名称。
不过要完成这种转换,还需要漫长的标准化过程,URL的问题并不是一个需要紧迫解决的问题,只是有所缺陷,但好在大家都已经接受它并熟练地进行使用,所以在可预见的未来互联网中还是会以URL为主。
HTTP报文
现在我们来看看客户端是怎么与web服务器进行事务处理的。一个事务由一条请求命令和一个响应结果组成,这种通信是通过HTTP报文(HTTP message)的格式化数据块进行的。
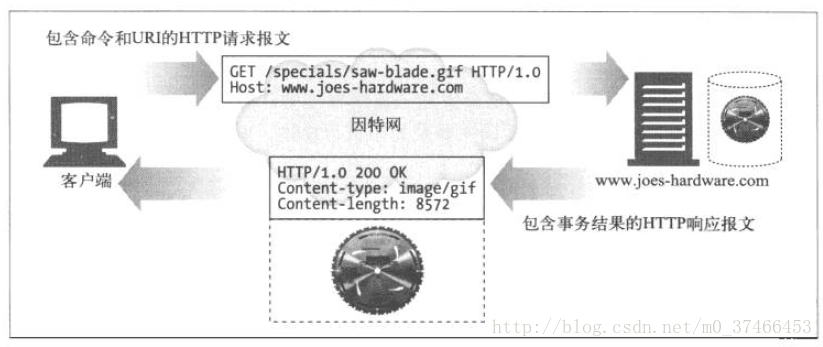
HTTP支持几种不同的请求命令,这些命令被称为HTTP方法(HTTP method),每条HTTP请求都包含一个方法,这个方法告诉服务器执行什么样的动作,下面列出几个常用方法以供了解:

同时,在HTTP响应报文中还会包含一个状态码,它是一个由三位数字组成的代码,告知用户请求是否成功,或者是需要采取其他什么动作,常见的状态码:

知道了这些基本组件后,我们再来看一下HTTP报文的结构,HTTP报文是由一行行的简单字符串组成的。HTTP报文都是纯文本,而非二进制,这样更方便人们对其书写和阅读。HTTP只有请求报文(request message)和响应报文(response message)两种类型,没有其他类型,这两种报文的结构很类似。


浏览器的工作流程
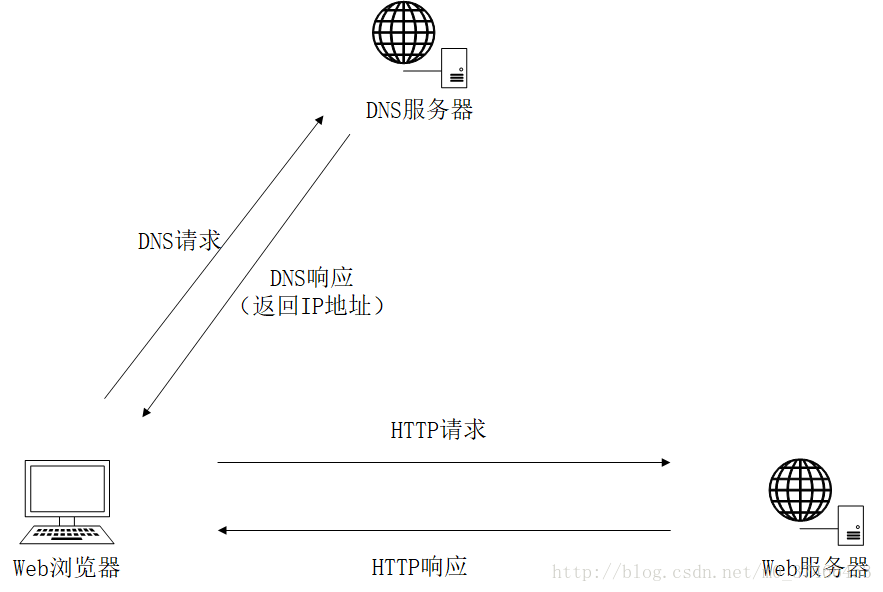
在了解完web的工作流程后及相关基本概念后,再来了解一下浏览器的工作流程。浏览器是我们最常用的客户端工具,那它的工作流程是怎样的呢?在这之前我们先来了解一下IP地址的概念。
这个概念是不是和前面介绍的URL很像?那其实URL没有使用数字形式的IP地址,它使用的是文本形式的域名,或者称为主机名。主机名就是IP地址比较人性化的别称。想象一下,每次访问网站的时候,需要输入的是一串IP地址,那得有多繁琐。所以可以通过一种名为域名服务(DNS)的机制帮我们将主机名转化为IP地址,这样繁琐的问题就简单化了。浏览器的工作流程也就基本清楚了。
连接
大概介绍了web的工作流程和HTTP报文之后,我们来看一下报文是如何传输的。在HTTP客户端向服务器发送报文之前,需要用到我们前面所提到的IP地址和端口号在客户端与服务器之间建立一条TCP/IP连接。这里涉及到一个传输控制协议(Transmission Control Protocol,TCP)的概念。首先我们看一下HTTP网络协议栈

从图上我们可以看出,HTTP是个应用层协议。HTTP无需操心网络通信中的具体细节,这些细节全部交给通用的可靠的互联网传输协议TCP/IP。TCP具有以下几个特征
-无差错的数据传输
-按序传输(按照发送顺序送达)
-未分段的数据流(可以在任何时候以任意尺寸发出数据)
所以只要建立了TCP连接,客户端与服务器之间的报文交换就不会丢失、不会被破坏、不会出现错序。在TCP中,你只需要知道服务器的IP地址以及运行在服务器上特定程序相关的端口号,就可以了,而具体到客户端与服务器之间是需要通过Socket“三次握手”进行连接,这里不做赘述。
在解析域名,建立TCP/IP连接,发送http报文,得到响应结果后,服务器会断开TCP连接,浏览器显示内容。但是如果服务器或客户端在报文中增加connection:keep-alive的名/值对,就表示客户端与服务器之间会继续保持连接,在下次使用时可以继续使用该连接。
---------------------
原文:https://blog.csdn.net/m0_37466453/article/details/72752684

 浙公网安备 33010602011771号
浙公网安备 33010602011771号