
Java点面总结-非现实可行性方案
一.Java内存结构
1.程序计数器:
当前线程执行的字节码指令的行号指示器;
执行的是Java方法,程序计数器记录的是正在执行的虚拟机字节码指令的地址;
执行的是native方法,程序计数器存储的是undefined;
2.虚拟机栈:
线程私有,Java方法执行的动态内存模型;
局部变量表,操作数栈,动态链接,方法出口等信息;
局部变量表存放的是基本数据类型,引用类型,returnAddress等;
3.本地方法栈:
为本地的native方法服务的,其他的都和虚拟机栈一样;
4.堆:
线程共享的一块区域;
存放对象实例;
垃圾回收的主要区域;
内存回收的角度上看:划分为新生代,老年代;
https://blog.csdn.net/qq906627950/article/details/81324825
5.方法区:
线程共享的区域;
JVM加载的类信息,类版本,字段,方法,接口,常量,静态变量,即时编译后的代码;
运行时常量池,class文件中的常量池在类加载后就被放入运行时常量池;
https://www.cnblogs.com/javatalk/p/10146534.html
https://www.jianshu.com/p/bf158fbb2432
二.Java内存模型
1.主内存
2.本地内存:
每个线程都有一个私有的本地内存,存储了该线程以读/写共享变量的副本;
3.Volatile:保证内存可见性,每次读取都是从主内存读取
写volatile 变量时,该线程本地内存中的共享变量值刷新到主内存;
读volatile 变量时,该线程的本地内存置为无效,从主内存中读取共享变量;
禁止重排序;
1、编译器优化的重排序。编译器在不改变单线程程序语义的前提下,可以重新安排语句的执行顺序。
2、指令级并行的重排序。现代处理器采用了指令级并行技术来将多条指令重叠执行。如果不存在数据依赖性,处理器可以改变语句对应机器指令的执行顺序。
https://www.cnblogs.com/java1024/p/8589537.html
三.Spring的AOP的实现方法
1.动态代理
有接口的:使用JDK的动态里;
无接口的:使用CGLIB代理;
2.代理模式:
为其他对象提供一种代理以控制对这个对象的访问;
代理可以在不改动目标对象的基础上,增加其他额外的功能;
重要的类或接口,一个是 InvocationHandler(Interface)、另一个则是 Proxy(Class);
动态代理类必须要实现InvocationHandler这个接口,代理类的实例关联到了一个handler;通过代理对象调用一个方法的时候,这个方法的调用就会被转发为由InvocationHandler的 invoke 方法来进行调用;
Proxy这个类的作用就是用来动态创建一个代理对象的类,它提供了许多的方法,但是我们用的最多的就是 newProxyInstance;
3.目标对象实现了接口spring会使用JDK代理;目标对象未实现接口,会使用CGLIB代理;
四.数据库问题定位
1.查看数据库服务器系统负载:
CPU、内存、I/O是否异常,使用top、topas、vmstat、iostat命令;
2.查看异常等待事件:
连接到数据库查看活动的等待事件,查看每个等待事件的个数、等待时长;
异常等待例如:library cache lock,找到具体的session,用kill命令关掉;
3.根据等待事件查会话:
查看哪些会话执行哪些SQL在等待,另外还查出来用户名和机器名称,以及是否被阻塞;
4.查询某个会话详情:
会话的详细信息,如上次个执行的SQL_ID,登录时间等;
5.查询对象信息:
等待的对象ID;
6.查询SQL语句:
SQL语句的执行计划、对象的统计信息、性能诊断、跟踪SQL;分析解决;
7.查询会话阻塞情况
某个会话阻塞了多少个会话;
8.查询数据库的锁
某个会话的锁
9.杀会话
根据分析kill session
https://blog.csdn.net/uxiAD7442KMy1X86DtM3/article/details/96060555
五.数据库性能调优
1.添加索引:
普通索引、主键索引、唯一索引、联合索引、全文索引(某字段包含某词汇时候的查询);
索引实现原理:
底层通过B叉树实现,首先创建索引文件,索引文件中每个值都有一个下标位置;
2.分表分库技术:
1. 垂直切分:
分表:根据业务把大的字段,不常用字段独立拆分成表;大表拆小表;
分库:把相同业务类型的表单独划库,降低单个数据库服务的压力;随着微服务分库;
2. 水平切分:
1. Range范围:某一个数据量一张表
2. Hash取模:根据某个关联字段,做Hash取模,放在不同表;
3. 地理位置划分;
4. 时间划分:根据订单时间划分不同表,一般查询最近一年的订单;
3. 读写分离
4. 存储过程
5. 配置最大连接数
6. SQL语句调优
7.日常:
分表:大表拆小表;按年份划分订单表,早几年数据量少一张表,后几年每年一张表,数据量再大的话就半年一张表,做个时间与表关系的配置,根据每次查询的时间读取配置定位数据表;
分库:微服务化自然分库,随着功能分库;根据机房分库,流水号放入机房标志位,每次查询判断标志位,查询不同的机房库;储存时候获得一个当前机房标志位放入流水号中,数据也储存在这个机房;根据订单时间既分表又分库,年份久的数据单独拉库访问;
分库一般避免join查询,多线程查询时间范围的库,最后集合数据;分表可以用join;
https://blog.csdn.net/tudaojun/article/details/82433064
六. SQL优化技巧
1. group by 后面增加 order by null 就可以防止排序:
group by 分组查询是,默认分组后,还会排序,可能会降低速度;
2.可以使用连接来替代子查询,因为使用join,MySQL不需要在内存中创建临时表;
3.尽量避免全表扫描,在 where 及 order by 涉及的列上建立索引;
4.避免在 where 子句中对字段进行 null 值判断,将导致引擎放弃使用索引而进行全表扫描;
5.尽量避免where后面使用函数,会放弃使用索引;
6.尽量避免where后面使用not in , in的形式,会放弃使用索引(MySQL 4.1 以上版本的 IN 是走索引的, 但4.0及其以下版本是不走索引的);
7.使用执行计划查看索引使用,执行时间等情况,分析优化sql;
https://blog.csdn.net/tudaojun/article/details/82433064
七.索引
1. 存储引擎用于快速找到记录的一种数据结构;将无序的数据变成相对有序的数据;
普通索引、主键索引、唯一索引、联合索引、全文索引;
2.B+树(平衡树):
1) 非叶子结点的子树指针与关键字个数相同;
2) B+树父结点中的记录,存储的是下层子树中的最小值;
3) 所有叶子结点通过一个链指针相连;
4) 所有关键字都在叶子结点出现;
5) 通过左旋右旋维持平衡;
3. Hash 索引结构:
1)仅能满足"=","IN"和"<=>"查询,不能使用范围查询;
https://blog.csdn.net/tfstone/article/details/80951878
4.聚簇索引与非聚簇索引的区别:
1.聚集索引:索引项的顺序与表中记录的物理顺序一致。
对于聚集索引,叶子结点即存储了真实的数据行,不再有另外单独的数据页。
在一张表上最多只能创建一个聚集索引,因为真实数据的物理顺序只能有一种。
2.非聚集索引:表数据存储顺序与索引顺序无关。
对于非聚集索引,叶结点包含索引字段值及指向数据页数据行的逻辑指针,其行数量与数据表行数据量一致。
https://www.jianshu.com/p/fa8192853184
八.数据库底层数据结构
1. MySQL 的常用引擎:
InnoDB:
支持事务,支持外键,存储文件,.frm 是表的定义文件,.idb是数据文件;
Myisam:
不支持事务,不支持外键,每次查询是原子的,.frm 是表的定义文件,.MYD 是数据文件,.MYI 是索引文件;
2. 用 B+Tree 来存储数据;
九.事物隔离级别
1.Mysql支持:读未提交、读已提交、可重复读、串行化;
2.Oracle支持:支持串行化级别和读已提交;
3.脏读,不可重复读,幻读;
4.mysql默认可重复读,其他数据库一般默认读已提交,项目中一般也设置读已提交;
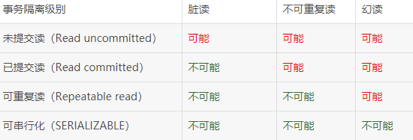
不可重复读的重点是修改:同样的条件, 你读取过的数据, 再次读取出来发现值不一样;
幻读的重点在于新增或者删除:同样的条件, 第1次和第2次读出来的记录数不一样;
十.事物的基本特性
1. 原子性:事务中各项操作,要么全部成功要么全部失败;。
2. 一致性:事务结束后系统状态是一致的;
3. 隔离性:并发执行的事务彼此无法看到对方的中间状态;
4. 持久性:当事务完成后,它对于数据的改变是永久性的;
十一.事物传播行为
传播行为分为两种:分为支持事物的传播和不支持事物的传播
1.PROPAGATION_REQUIRED:(支持事物)如果当前没有事务,就创建一个新事务,如果当前存在事务,就加入该事务,该设置是最常用的设置。
2.PROPAGATION_SUPPORTS:(支持事物)支持当前事务,如果当前存在事务,就加入该事务,如果当前不存在事务,就以非事务执行。‘
3.PROPAGATION_MANDATORY:(支持事物)支持当前事务,如果当前存在事务,就加入该事务,如果当前不存在事务,就抛出异常。
4.PROPAGATION_REQUIRES_NEW:(支持事物)创建新事务,无论当前存不存在事务,都创建新事务。
5.PROPAGATION_NOT_SUPPORTED:(不支持事物)以非事务方式执行操作,如果当前存在事务,就把当前事务挂起。
6.PROPAGATION_NEVER:(不支持事物)以非事务方式执行,如果当前存在事务,则抛出异常。
7.PROPAGATION_NESTED:(不支持事物)如果当前存在事务,则在嵌套事务内执行。如果当前没有事务,则执行与PROPAGATION_REQUIRED类似的操作;
十二.事物回滚机制
1. 核心思想:
读写操作在事物的局部变量中进行,当有效性检查通过,对数据库做真正的更新;
事务对数据的更新首先在自己的工作空间进行,等到要写回数据库时才进行有效性检查,对不符合要求的事务进行回滚;
2. 事物执行三个阶段:
1. 读阶段:数据项被读入并保存在事务的局部变量中。所有write操作都是对局部变量进行,并不对数据库进行真正的更新;
2. 有效性检查阶段:对事务进行有效性检查,判断是否可以执行write操作而不违反可串行性。如果失败,则回滚该事务;
3. 写阶段:事务已通过有效性检查,则将临时变量中的结果更新到数据库中;
十二.事务日志及其分类
1. 每一个操作在真正写入数据数据库之前,先写入到日志文件中;
2. https://blog.csdn.net/Csoap2/article/details/88359002
3. 重做日志(redo log): 确保事务的持久性;
4. 回滚日志(undo log): 保证数据的原子性,保存了事务发生之前的数据的一个版本,可以用于回滚,同时可以提供多版本并发控制下的读(MVCC),也即非锁定读;
5. 二进制日志(binlog): 用于复制,在主从复制中,从库利用主库上的binlog进行重播,实现主从同步;
6. 错误日志: 错误日志记录着mysqld启动和停止,以及服务器在运行过程中发生的错误的相关信息;
7. 普通查询日志: general query log:录了服务器接收到的每一个查询或是命令,无论这些查询或是命令是否正确甚至是否包含语法错误,general log 都会将其记录下来 ,记录的格式为 {Time ,Id ,Command,Argument };开启General log会产生不小的系统开销。 因此,Mysql默认是把General log关闭的;
8. 慢查询日志:慢日志记录执行时间过长和没有使用索引的查询语句,报错select、update、delete以及insert语句,慢日志只会记录执行成功的语句;
9. 中继日志(relay log):在复制环境中产的的日志信息;
10. https://blog.csdn.net/zhang123456456/article/details/72811875
11. https://www.cnblogs.com/myseries/p/10728533.html
十二.分布式事务处理
1. 消息队列事务消息
2. 本地消息表,定时扫描重发
3. 日志补偿,回滚数据方法
十二.MVCC多版本并发控制协议
1. 通过在每行记录中保存两个隐藏的列来实现的,创建事物id,删除事物id。每开始一个新的事务,系统版本号(可以理解为事务的ID)就会自动递增,事务开始时刻的系统版本号会作为事务的ID;
2. 版本并发控制的意义在于,可以实现数据库的非阻塞式读取。同时解决数据库脏读和不可重复读取的问题;
3. https://yq.aliyun.com/articles/644107
4. https://blog.csdn.net/chenyang1010/article/details/84554638
十三.数据库三大范式
1. 第一范式:所有属性都不能在分解为更基本的数据单位,即原子性;
2. 第二范式:中的所有列,都必须依赖于主键,既有一个主键;
3. 第三范式:每个属性都跟主键有直接关系而不是间接关系;
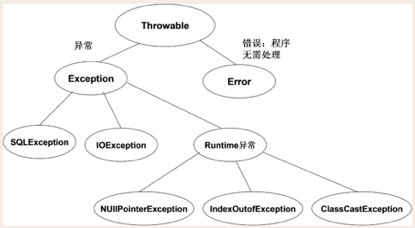
十四. java异常的续承关系
1. 续承关系
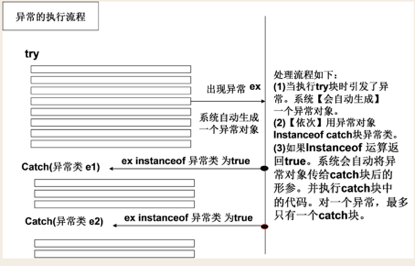
2. 异常的执行流程图
十五.信号量
1. 信号量:
1.Semaphore可以控制某个资源可被同时访问的个数;
2.通过 acquire() 获取一个许可,如果没有就等待,而 release() 释放一个许可;
3.Sync使用AQS提供的setState方法来初始化共享变量state,使用CAS算法设置state的值,后续通过acquire和release 来获取和规划许可;
https://www.cnblogs.com/xbq8080/p/6760445.html
https://www.jianshu.com/p/f50455ad3514
十六.缓存
1. 常见问题及其解决办法:
1.
缓存穿透:DB中不存在数据,每次都穿过缓存查DB,造成DB的压力;
解决方案:放入一个特殊对象(比如特定的无效对象,当然比较好的方式是使用包装对象,无效直接返回,不再查询数据库);
2.
缓存击穿:在缓存失效的瞬间大量请求,造成DB的压力瞬间增大;
解决方案:更新缓存时使用分布式锁锁住服务,防止请求穿透直达DB;
3.
缓存雪崩:大量缓存设置相同的失效时间,同一时间失效,造成服务瞬间性能急剧下降;
解决方案:缓存时间使用基本时间加上随机时间;
https://blog.csdn.net/u011320646/article/details/85491103
十七.消息队列
1. 异步处理
2. 应用解耦
3. 流量削锋:
用户的请求,服务器接收后,首先写入消息队列。假如消息队列长度超过最大数量,则直接抛弃用户请求或跳转到错误页面
4.日志处理:负责日志数据的接收,存储和转发;订阅并消费kafka队列中的日志数据;
5.消息通讯:实现点对点消息队列;
十八.HashMap原理
1. 默认长度16,加载因子0.75,达到原长度的0.75时候扩大两倍;
2. HashMap采用了数组和链表的数据结构(散列桶),非线程安全,所以HashMap很快,多线程会导致链表死循环
1. 1.7扩容采用的是头插入会死循环;1.8扩容采用的是尾插入不会死循环;
2. 内部有transfer方法,在多少线程竞争,链表指针指向循环,导致while死循环;
3. HashMap可以接受null键和值,而Hashtable则不能(原因就是equlas()方法需要对象);
4. put过程:
1. 对Key求Hash值,然后再计算下标;
2. 没有碰撞,直接放入桶中(碰撞的意思是多线程竞争计算得到的Hash值相同);
3. 如果碰撞了,以链表的方式链接到后面;
4. 如果链表长度超过阀值( TREEIFY THRESHOLD==8),就把链表转成红黑树,链表长度低于6,就把红黑树转回链表;
5. 用红黑树的原因是:
1. 红黑树的平均查找长度是log(n),长度为8的时候,平均查找长度为3;
2. 如果继续使用链表,平均查找长度为8/2=4;所以使用红黑树;
3. 链表长度如果是小于等于6,6/2=3,虽然速度也很快的,但是转化为树结构和生成树的时间并不会太短,所以6时使用链表;
4. 6和8,中间有个差值7可以有效防止链表和树频繁转换;
5. 红黑树平均查询效率高;
6. 如果节点已经存在就替换旧值;
7. 如果桶满了(容量16*加载因子0.75),就需要扩容2倍后重排;
5. get过程
1. HashMap会使用键对象的hashcode找到桶位置;
2. 调用keys.equals()方法去找到链表中正确的节点,最终找到要找的值对象;
6. 解决hash碰撞:
1. 使用扰动函数可以减少碰撞;
2. 使用不可变的、声明作final的对象;
3. 使用String,Interger这样的包装类作为键是非常好的选择,String是final的,而且已经重写了equals()和hashCode()方法;
4. 开放定址法:当冲突发生时,使用某种探查技术在散列表中形成一个探查(测)序列。沿此序列逐个单元地查找,直到找到给定的地址;
https://baijiahao.baidu.com/s?id=1618550070727689060&wfr=spider&for=pc
十九.设计模式
1. 单例模式:
懒汉式:双重检查加锁,使用volatile声明对象;
优点:线程安全;延迟加载;效率较高;
饿汉式:静态常量声明加载;
优点:避免线程同步,但是没有懒加载作用;
使用场景:
1.控制资源的使用,通过线程同步来控制资源的并发访问;
2.控制实例产生的数量,达到节约资源的目的;
3.作为通信媒介使用,也就是数据共享,它可以在不建立直接关联的条件下,让多个不相关的两个线程或者进程之间实现通信;
2. 工厂模式:
概述:提供一个用于创建对象的接口(工厂接口),让其实现类(工厂实现类)决定实例化哪一个类(产品类),并且由该实现类创建对应类的实例;
模式作用:一定程度上解耦,消费者和产品实现类隔离开;
3. 代理模式:
实现InvocationHandler这个接口,代理类的实例关联到了一个handler;
通过代理对象调用一个方法的时候,这个方法的调用就会被转发为由InvocationHandler的 invoke 方法来进行调用;
二十.垃圾回收机制
1. 总流程:标记 --> 清除 -->压缩
2. 标记:首先第一次GC时,回收器会把对象标记使用与未使用;
3. 清除:这一步删除所有未引用的对象;
4. 压缩:将剩下的已引用对象放在一起(压缩),更简单快捷地分配新对象,提升性能;
5. 新生代:
1. 先在Eden区分配空间,一旦eden区满了,就会触发第一次GC,进行小型垃圾回收机制,把存活的对象放在第一个S区,并清除Eden空间;
2. 在下一次GC时,重复之前的操作,不过特别的是会把第一个S区的对象移动到第二个S区,并清除Eden和第一个S区,这时,S区已经有了不同年龄的对象;
3. 在下一次Minor GC(新生代对象垃圾回收)中,会重复同样的操作。不过,这一次Survivor区会交换。被引用的对象移动到S,。幸存的对象增加年龄。Eden区和S被清空;
6. 老年代:
1. 到达年龄将进入老年代,每经历一次Minor GC,对象还存活的话Age=Age+1;
年龄临界值由参数:-XX:MaxTenuringThreshold设置
2. 对象的体积太大,新生代无法容纳的话也会绕过新生代,直接在老年代分配空间;
3. 如果在Survivor区中相同年龄(设年龄为age)的对象的所有大小之和超过Survivor空间的一半,年龄大于或等于该年龄(age)的对象就可以直接进入老年代,无需等到MaxTenuringThreshold中要求的年龄;
7. 回收算法:
1. 标记-清除算法(Mark-Sweep);
2. 复制算法;
3. 标记-整理压缩算法;
4. 分代收集算法;
5. https://blog.csdn.net/a602519773/article/details/82529240
8. 垃圾收集器分类:
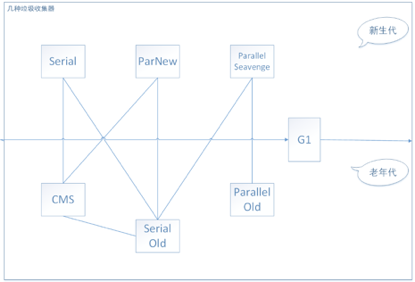
1. G1分代收集;并行与并发,G1能利用多CPU多核心的硬件优势,来缩短STW的时间;可预测的停顿,建立了可以预测的停顿时间的模型,能让使用者明确指定一个长度为M毫秒的时间片段内,消耗在垃圾收集上的时间不得超过N毫秒;
2. CMS:以获取最短回收停顿时间为目标;
3. https://www.cnblogs.com/Yintianhao/p/10127358.html
https://www.cnblogs.com/PrayzzZ/p/10942022.html
https://baijiahao.baidu.com/s?id=1610753983428990724&wfr=spider&for=pc
二十一.多线程创建
1. 线程启动:
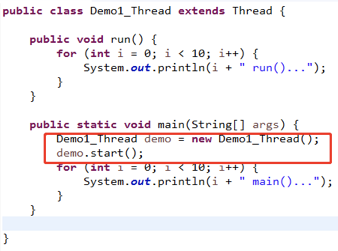
1. 实现Thread类:创建Demo类对象调用start方法,run方法处理具体业务;
2. 实现Runable接口

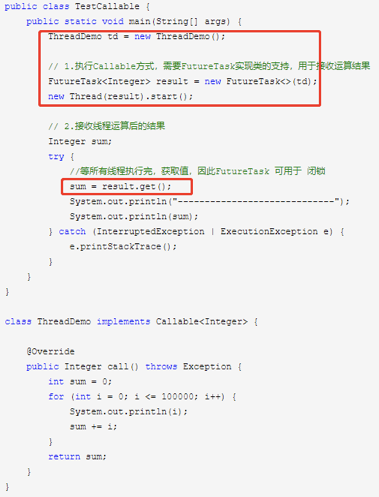
3. 实现Callable接口:运行Callable任务可拿到一个Future对象, Future表示异步计算的结果;使用executor()无返回值;submit()有返回值;
4. 线程池:
1. ExecutorService pool = new ThreadPoolExecutor(3, 10,10L, TimeUnit.SECONDS,new LinkedBlockingQueue<Runnable>(512), Executors.defaultThreadFactory(),new ThreadPoolExecutor.AbortPolicy());
2. corePoolSize : 核心线程数;
1. 当有任务到来,创建核心线程去执行;
2. prestartCoreThread()方法可以在初始化后无任务就去创建线程;
3. 线程池中的线程数目达到corePoolSize后,就会把再次到达的任务放到缓存队列当中;
4. 设置allowCoreThreadTimeOut(true)的时候,默认核心线程根据空闲线程保持时间回收;不设置则不回收;
3. maximumPoolSize : 最大线程数;当任务队列满了之后,会判断最大线程数是否达到最大,没有的话,则会创建线程执行任务;
4. keepAliveTime :空闲线程最大存活时间;
5. unit : 时间单位,TimeUnit.SECONDS等;
6. workQueue : 任务队列,存储暂时无法执行的任务,等待空闲线程来执行任务;
1. 直接提交的任务队列(SynchronousQueue):
没有容量,不保存任务;新任务提交给线程执行。如果没有空闲的线程,则尝试创建新的线程。如果线程数大于最大值maximumPoolSize,则执行拒绝策略;
2. 有界的任务队列(ArrayBlockingQueue):
基于数组,先进先出,需要指定队列的最大容量;
3. 无界的任务队列(LinkedBlockingQueue):
先进先出,可不指定大小;默认Integer.MAX_VALUE;
7. threadFactory : 线程工程,用于创建线程;线程命名;
8. handler : 当线程边界和队列容量已经达到最大时,用于处理阻塞时的程序;
9. handler:表示当拒绝处理任务时的策略,有以下四种取值:
1. ThreadPoolExecutor.AbortPolicy:丢弃任务并抛出RejectedExecutionException异常;
2. ThreadPoolExecutor.DiscardPolicy:也是丢弃任务,但是不抛出异常;
3. ThreadPoolExecutor.DiscardOldestPolicy:丢弃队列最前面的任务,然后重新尝试执行任务(重复此过程);
4. ThreadPoolExecutor.CallerRunsPolicy:由调用线程处理该任务;
10. shutdown():不会立即终止线程池,而是要等所有任务缓存队列中的任务都执行完后才终止,但再也不会接受新的任务;
shutdownNow():立即终止线程池,并尝试打断正在执行的任务,并且清空任务缓存队列,返回尚未执行的任务;
11. 动态线程池:
1. 通过自定义线程池的实例设置最大最小,任务队列,可以设置线程池;
2.
12. 如何合理配置线程池的大小:
1. 根据任务类型:
CPU密集型:参考设置为CPU总核数N+1
IO密集型:参考设置为CPU总核数2N+1
2. 另外根据实际情况系统负载,资源利用率,线程等待时间这些做调整;
二十二:synchronized锁底层原理
1. 对象头有指针指向monitor对象;
2. 线程获得monitor对象,monitor中的owner变量设置为当前线程,monitor中的计数器count加1;
3. 当前线程执行完毕释放monitor(锁)并复位变量的值;
4. static synchronized是类锁,synchronized是对象锁区别:
1. 类锁:是对所有的实例,多线程使用一把锁;
2. 对象锁(实例锁):只对当前实例,多线程使用一把锁;
3. A a = new A();A a2 = new A();
a. a.synchronized_A 与 a.synchronized_B 同一个实例,同步;
b. a.synchronized_A 与 a2.synchronized_B两个实例,不同步
c. a.static synchronized_A 与 a2. static synchronized_B 同一个类锁,同步;
d. a.static synchronized_A 与 a. synchronized_B 锁不同,管理区域不同,不同步;
二十三:乐观锁和悲观锁
1. 乐观锁:表中有一个版本字段,第一次读的时候,获取到这个字段。处理完业务逻辑开始更新的时候,需要再次查看该字段的值是否和第一次的一样。如果一样更新,反之拒绝。之所以叫乐观,因为这个模式没有从数据库加锁。
2. 悲观锁:共享资源每次只给一个线程使用,其它线程阻塞,用完后再把资源转让给其它线程;悲观锁是数据库层面加锁,都会阻塞去等待锁。
二十三:ReentrantLock
1. 先通过CAS算法尝试获取锁;
2. 已经有线程占据了锁,那就加入CLH队列并且被挂起;
3. 当锁被释放之后,排在CLH队列队首的线程会被唤醒,然后CAS再次尝试获取锁;
4. 非公平锁:如果同时还有另一个线程进来尝试获取,那么有可能会让这个线程抢先获取;
5. 公平锁:如果同时还有另一个线程进来尝试获取,当它发现自己不是在队首的话,就会 排到队尾,由队首的线程获取到锁;
6. CAS:比较并交换。CAS有3个操作数:内存值V、预期值A、要修改的新值B。当且仅当预期值A和内存值V相同时,将内存值V修改为B,否则什么都不做;
7. 可重入原理:
acquire方法内部先使用tryAcquire这个钩子方法去尝试再次获取锁,这个方法在NonfairSync这个类中其实就是使用了nonfairTryAcquire,具体实现原理是先比较当前锁的状态是否是0,如果是0,则尝试去原子抢占这个锁(设置状态为1,然后把当前线程设置成独占线程),如果当前锁的状态不是0,就去比较当前线程和占用锁的线程是不是一个线程,如果是,会去增加状态变量的值,从这里看出可重入锁之所以可重入,就是同一个线程可以反复使用它占用的锁;
8. JDK 6之前synchronized效率低的原因:依赖于操作系统Mutex Lock实现的锁,每个线程获得的都是重量级锁;
9. JDK 6引入了偏向锁和轻量级锁,提高了synchronized性能;
10. 锁释放和获取的内存语义
4. 当线程释放锁时,JMM 会把该线程对应的本地内存中的共享变量刷新到主内存中。
5. 当线程获取锁时,JMM 会把该线程对应的本地内存置为无效。从而使得线程必须要从主内存中去读取共享变量。
二十四:类加载机制
1. ClassLoader负责将 Class 加载到 JVM 中;
2. 查每个类由谁加载(父优先的等级加载机制);
3. 将 Class 字节码重新解析成 JVM 统一要求的对象格式;
4. 整个生命周期包括了:加载、验证、准备、解析、初始化、使用和卸载这7个阶段;
二十五:循环删除多个元素
1. 使用iterator的remove方法;

二十六:ConcurrentHashMap原理详细
1.JAVA7之前ConcurrentHashMap主要采用分段锁机制,JAVA8之后采用CAS算法+synchronized,效率提高了一些;
2.内部采用了一个Segment 的结构,Segment 内部维护了一个链表数组;
3.ConcurrentHashMap 定位一个元素的过程需要进行两次Hash操作,第一次 Hash 定位到 Segment,第二次 Hash 定位到元素所在的链表的头部;
4.写操作的时候可以只对元素所在的 Segment 进行操作即可,不会影响到其他的 Segment;
5. HashTable不管是 put 还是 get 操作都需要做同步处理,安全且效率慢;
6. ConcurrentHashMap非绝对安全,因为get未加锁,外部操作put值时,可能未完全操作完成,有其他get操作拿到的是旧值;
二十七.线程监听
1. CountDownLatch
1. 构造参数为计数总量final CountDownLatch latch = new CountDownLatch(2);
2. 在需要监听其他线程运行状态的线程中使用latch.await();
3. 如果超过某个时间后,计数依然没到0,则使当前线程进入阻塞状态,直到CountDownLatch的计数值为0
await(long timeout, TimeUnit unit);
4.使计数器数值-1,在其他被监听的线程中调用latch.countDown();
https://blog.csdn.net/qq_37292960/article/details/86698858
2. CyclicBarrier
1. CyclicBarrier是一个同步辅助类,它允许一组线程相互等待直到所有线程都到达一个公共的屏障点,然后再执行之后的程序;
2. 用于多线程计算数据,最后合并计算结果的场景;
3. CyclicBarrier和CountDownLatch的区别
1.CountDownLatch减计数,CyclicBarrier加计数;(完成一个线程减一次,一个线程到达栅栏位置加一次);
2.CountDownLatch是一次性的,CyclicBarrier通过reset()可以重用;
3.CountDownLatch强调一个线程等多个线程完成某件事情。CyclicBarrier是多个线程互等,等大家都到达栅栏位置,唤醒阻塞线程执行之后的程序;
二十八. Redisson锁
1. 原理步骤:
1. 实现Lock接口,lock加锁和unlock解锁;
2. 客户端加锁,根据hash节点选择一台机器;其他节点主从复制;
3. 发送一段lua脚本到redis上,保证原子性;
4. 脚本对于某个key加锁,默认30秒,设置客户端id,value为1;
5. 如果存在key,判断是否当前线程,是则重入value加1;
二十九. BIO NIO AIO
1. BIO:同步并阻塞IO,适用于连接数目比较小且固定的架构;
2. NIO:同步非阻塞IO,适用于连接数目多且连接比较短(轻操作)的架构;
3. AIO:异步阻塞IO,适用于连接数目多且连接比较长(重操作)的架构;
三十.MQ高可用
1. master slave 配合,master 支持读、写,slave 只读,producer 只能和 master 连接写入消息,consumer 可以连接 master 和 slave;
2. consumer 高可用效果:当 master 不可用或者繁忙时,consumer 会被自动切换到 slave 读。所以,即使 master 出现故障,consumer 仍然可以从 slave 读消息,不受影响;
3. producer 高可用:创建 topic 时,把 message queue 创建在多个 broker 组上(brokerName 一样,brokerId 不同),当一个 broker 组的 master 不可用后,其他组的 master 仍然可以用,producer 可以继续发消息;
三十一.MQ重复消费解决方案
1. 因为网络不可达等原因造成的(确认消息没及时到达到rocketmq,会重复投递);
2. 消费端处理消息的业务逻辑保持幂等性(根据主键数据先查询,有则更新,无则新增);幂等性意思是多次请求结果一致;
3. 如果消费数据写redis,直接set,天然幂等性;
4. 利用日志记录MQ消息,记录消息ID如果存在,则不再处理;
三十二.MQ数据丢失
1. 生产者丢失数据:
1. 送数据之前开启事务功能,MQ未收到,生产者会报错异常,可以回滚事务;重试发送消息,如果成功则提交事务;同步机制比较消耗性能;
2. 开启MQ confirm模式,发送成功MQ回传一个ack消息,发送失败MQ会回调一个nack接口,可以重试;异步可以继续发送其他消息;
2.MQ丢失数据:
1.开启MQ的持久化,MQ恢复之后会读取数据;
2.创建队列的时候将其设置为持久化;
3.发送消息的时候将消息的deliveryMode设置为2,就是将消息设置为持久化;
3.消费端丢失数据:
1.使用ACK机制确认,如果未确认MQ把消息投递给其他消费端消费;
三十三. 息队列里的数据按顺序执行
1. 拆分多个queue,每个queue一个consumer;
2. 一个queue但是对应一个consumer,然后这个consumer内部用内存队列做排队,然后分发给底层不同的worker来处理;
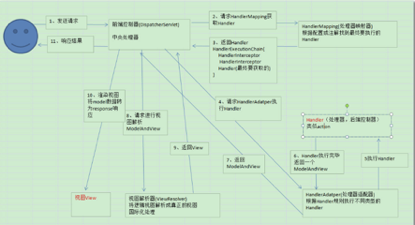
三十四.SpringMvc处理流程
1. 图解
2. https://www.cnblogs.com/5ishare/p/8683971.html
三十五.HashSet如何保证不重复
1. 内部维护的Map, 元素值作为map的key,map的key是不重复的,key是调用了对象的hashCode和equals方法进行的判断,所以不重复;
2. https://www.cnblogs.com/nickhan/p/8550655.html
三十六.url执行过程
1.DNS解析
2.TCP连接
3.发送HTTP请求
4.服务器处理请求并返回HTTP报文
5.浏览器解析渲染页面
6.连接结束
三十七.jvm运行原理
1..java源代码--class字节码--类加载器--字节码校验器--解释器--硬件
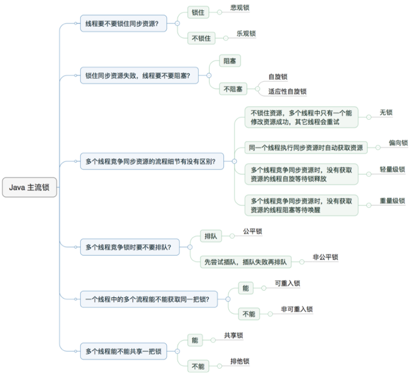
三十八.各种锁总结
1. 乐观锁:操作不会加锁,不阻塞其他线程的任何操作,依据版本号进行对比是否有其他操作更改数据;通过CAS算法实现;
2. 悲观锁:阻塞其他线程操作资源,独享资源直到锁释放;
3. 图解:

4. 自旋锁 VS 适应性自旋锁
1. 自旋锁:线程等待时不进入阻塞,循环自旋尝试获得锁;减少CPU切换时间;CAS算法实现;
2. JDK1.4.2引入自旋锁,默认自旋10次,-XX:PreBlockSpi可以修改默认值;
3. JDK 6中变为默认开启自旋锁,并且引入了自适应 的自旋锁(适应性自旋锁);
4. 适应性自旋锁:自旋的时间(次数)不再固定,而是由上一次在同一个锁上的自旋时间及锁的拥有者的状态决定;
5. 对于同一个锁对象上,上次自旋刚刚成功,且成功持有锁的线程正在运行,虚拟机认为本次自旋成功率高,允许它自旋时间更长;
6. 对于同一个锁对象上,如果历史自旋失败比较多,本次自旋很可能直接进入阻塞,不在自旋;
7. 自旋锁:TicketLock、CLHlock和MCSlock;
5. 无锁:没有对资源进行锁定,所有的线程都能访问并修改同一个资源,但同时只有一个线程能修改成功;
6. 偏向锁:
1. 非多线程环境下,一段同步代码一直被一个线程所访问,那么该线程会自动获取锁,降低获取锁的代价,提高性能;
2. 对象头中,Mark Word里存储锁偏向的线程ID,置换ThreadID的时候依赖一次CAS原子指令,其他进入或者退出锁不在通过CAS操作加锁或者解锁;
3. 遇到其他线程竞争的时候,在全局安全点(在这个时间点上没有字节码正在执行),偏向锁会撤销到无锁或者轻量级锁状态;
4.
7. 轻量级锁:
1. 等待线程会通过自旋的形式尝试获取锁,不会阻塞,减少cpu切换从而提高性能;
2. 当自旋超过一定的次数,或者一个线程在持有锁,一个在自旋,又有第三个来访时,轻量级锁升级为重量级锁;
8. 重量级锁:等待锁的线程都会进入阻塞状态;
9. 总结偏,轻,重锁:
1. 偏向锁通过对比Mark Word解决加锁问题,避免执行CAS操作。
2. 而轻量级锁是通过用CAS操作和 自旋来解决加锁问题,避免线程阻塞和唤醒而影响性能。
3. 重量级锁是将除了拥有锁的线程以外的线程都阻塞;
10. 公平锁:
1.多线程竞争的时候,等待线程在队列中排队;
2.公平锁的优点是等待锁的线程不会饿死;
3.缺点是整体吞吐效率相对非公平锁要低;
4.等待队列中除第一个线程以外的所有线程都会阻塞,CPU唤醒阻塞线程的开销大。
11. 非公平锁:
1. 多个线程加锁时直接尝试获取锁,获取不到才会到等待队列的队尾等待;
2. 线程有机会不阻塞获得锁,优点是减少唤起线程的开销,提高吞吐率;
3. 缺点是等待队列中的线程可能会饿死或者很久获得锁;
4. ReentrantLock内部类sync,sync继承AQS(AbstractQueuedSynchronizer),sync子类公平锁FairSync和非公平锁NonfairSync两子类,
5. NonfairSync中多一个判断,hasQueuedPredecessors(),主要是判断当前线程是否位于同 步队列中的第一个。如果是则返回true,否则返回false;
12. 可重入锁:(递归锁)ReentrantLock和synchronized
1. 同一个线程在外层方法获取锁的时候,再进入该线程的内层方法会自动获取锁;
2. 前提锁对象得是同一个对象或者class,不会因为之前已经获取过还没释放而阻塞;
3. 父类AQS中维护了一个同步状态status:
1. 果status == 0表示没有其他线程在执行,则把status置为1,当前线程开始执;
2. 果status != 0,判断当前线程是否是获取到这个锁的线程,如果是的话执行status+1,且当前线程可以再次获取锁;
3. 不可重入锁是直接去获取并尝试更 新当前status的值,如果status != 0的话会导致其获取锁失败,当前线程阻塞;
13. 不重入锁:NonReentrantLock;
14. 独享锁:(排他锁)ReentrantReadWriteLock- -WriteLock
1. 是指该锁一次只能被一个线程所持有,其他线 程不能再对A加任何类型的锁。
2. ReentrantLock无论读操作还是写操作,添加的锁都是都是独享锁;
15. 共享锁:ReentrantReadWriteLock- - ReadLock
1. 该锁可被多个线程所持有,获得共享锁的线程只能读数据,不能修改数据;
2.
16. 图解示例:
三十九.JUC工具类原理
一.AtomicInteger
1. AtomicInteger类:原子计数
2. 内部维护一个成员变量value,使用volatile修饰;
3. Get或者set等原子操作依赖javaAPI unsafe类;
4. Unsafe内部是CAS函数实现原子操作;
二. ThreadLocal
1.提供线程的变量副本;
2.内部维护ThreadLocalMap;
3.ThreadLocalMap底层是一个数组,数组中元素类型是Entry类型;
4.Key是this当前线程,value是我们存入的值;
5.remove将当前线程局部变量的值删除,JDK 5.0新增的方法;
当线程结束后,对应该线程的局部变量将自动被垃圾回收;
调用remove可以加快内存回收的速度;
remove之后又调用了get,会重新初始化一次;
三.Semaphore信号量
1.Semaphore可以控制某个资源可被同时访问的个数;
2. 通过 acquire() 获取一个许可,如果没有就等待,而 release() 释放一个许可;
3. Sync使用AQS提供的setState方法来初始化共享变量state,后续通过acquire和release 来获取和规划许可;
四.CountDownLatch
1. 主线程等待监控的子线程运行完毕进行最后处理;
2. 在需要监听其他线程运行状态的线程中使用latch.await();
3. 使计数器数值-1,在其他被监听的线程中调用latch.countDown();
4. 通过维护AQS中volatile修饰的state累加,使用CAS算法保证原子性;
五.CyclicBarrier
1. CyclicBarrier是一个同步辅助类,它允许一组线程相互等待直到所有线程都到达一个公共的屏障点,再被唤醒运行之后的程序;
2. 用于多线程计算数据,最后合并计算结果的场景;
3. 基于ReentrantLock 和 Condition 的组合使用;
4. await方法:获取lock对象,然后拦截数减一,直到拦截数为0,结束await;
5. 原理过程:
1. 线程执行到await()方法,进入内部dowait()方法,获得Lock独占锁;
2. 把当前线程的Node节点加入Condition等待队列,释放锁,进入阻塞;
3. 到最后一个线程会把Condition等待队列中的Node节点按之前顺序都转移到AQS同步队列中,此时所有线程到达屏障点;
4. 然后会执行到AQS的unparkSuccessor(Node node)方法,根据队列以此唤醒线程执行之后程序,顺序先进先出;
四十.CAS算法
1. CAS算法涉及到三个操作数:
1.需要读写的内存值 V
2.进行比较的值 A
3.要写入的新值B
4.当内存值等于比较值,通过原子方式把新值赋值给内存值;
2.ABA问题
1. CAS需要在操作值的时候检查内存值是否发生变化,没有发生变化才会更新内存值。但是如果内存值原来 是A,后来变成了B,然后又变成了A,那么CAS进行检查时会发现值没有发生变化,但是实际上是有变化的;
2.解决思路就是在变量前面添加版本号,每次变量更新的时候都把版本号加一,这样变化过程就从“A-B-A”变成 了“1A-2B-3A”;
3.JDK从1.5开始提供了AtomicStampedReference类来解决ABA问题,具体操作封装在compareAndSet()中。
3.CAS一直自旋开销会很大;解决:虚拟机参数设置自旋次数;适应性自旋;
4.只能保证一个共享变量的原子操作:
1.对一个共享变量执行操作时,CAS能够保证原子操作,但是对多个共享变量操作 时,CAS是无法保证操作的原子性的;、
2.Java从1.5开始JDK提供了AtomicReference类来保证引用对象之间的原子性,可以把多个变量放在一个对象里 来进行CAS操作;
四十一.防止接口重复提交
1. 使用分布式锁,对主键数据加锁,处理完毕则解锁;
2. 前端提交后跳转页面或者置灰按钮;
3. 配置拦截器,使用session或者redis储存token,系统判断是否存在,存在则是重复提交;
4. 接口根据业务主键判断,存在则返回不处理;
四十二. 使一个类不可实例化
5. 不需要实例化,使用了私有构造器;
6. 使用final修饰不可被继承;
四十三.MySql主从复制原理
1. master开启bin-log(二进制日志)功能,日志文件用于记录数据库的读写增删;
2. 需要开启3个线程,master IO线程,slave IO线程, SQL线程;
3. Slave 通过IO线程连接master,并且请求某个bin-log,position(某个位置)之后的内容;
4. MASTER服务器收到slave IO线程发来的日志请求信息,MASTER IO线程去将bin-log内容,position返回给slave IO线程;
5. Slave服务器收到bin-log日志内容,将bin-log日志内容写入relay-log中继日志,创建一个master.info的文件,该文件记录了master ip 用户名 密码 master bin-log名称,bin-log position;
6. Slave端开启SQL线程,实时监控relay-log日志内容是否有更新,解析文件中的SQL语句,在slave数据库中去执行;
四十四.Redis主从复制过程
1. 全量复制:全量复制开销大,2.8之后实现了部分复制;
2. 从节点执行 slaveof 命令会验证权限,建立socket长连接;
3. 第一次复制会全量复制,完成之后,接下来,主节点就会持续的把写命令异步发送给从节点;
4. 这个过程维护长连接,使用心跳机制:
1. 主节点默认每隔 10 秒对从节点发送 ping 命令,可修改配置 repl-ping-slave-period 控制发送频率;
2. 从节点在主线程每隔一秒发送 replconf ack{offset} 命令,给主节点上报自身当前的复制偏移量;
3. 主节点超过60秒未收到信息,判断从节点下线;
4. redis 主从节点部署在相同的机房/同城机房,避免网络延迟带来的网络分区造成的心跳中断;
5. 如果心跳中断,主节点会把数据发送至缓冲区,再次建立链接后主节点只需发送缓冲区数据;否则需要全量复制;
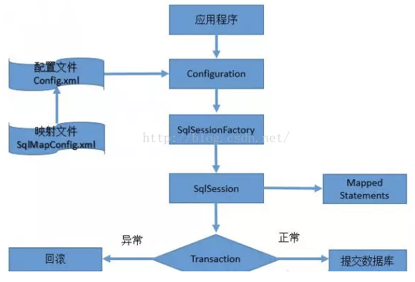
四十五. MyBatis流程及工作原理
1. 工作流程:
posted on 2021-04-21 10:11 West-Cowboy-TY 阅读(187) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号