
Kafka 消费者源码
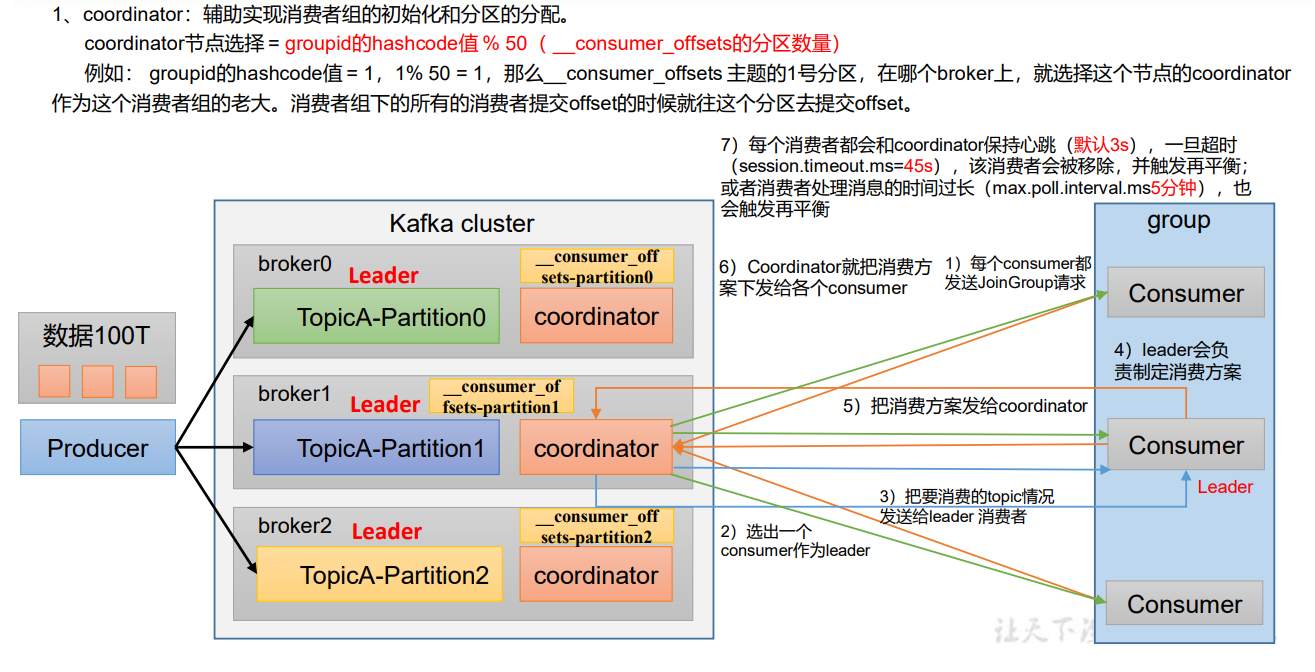
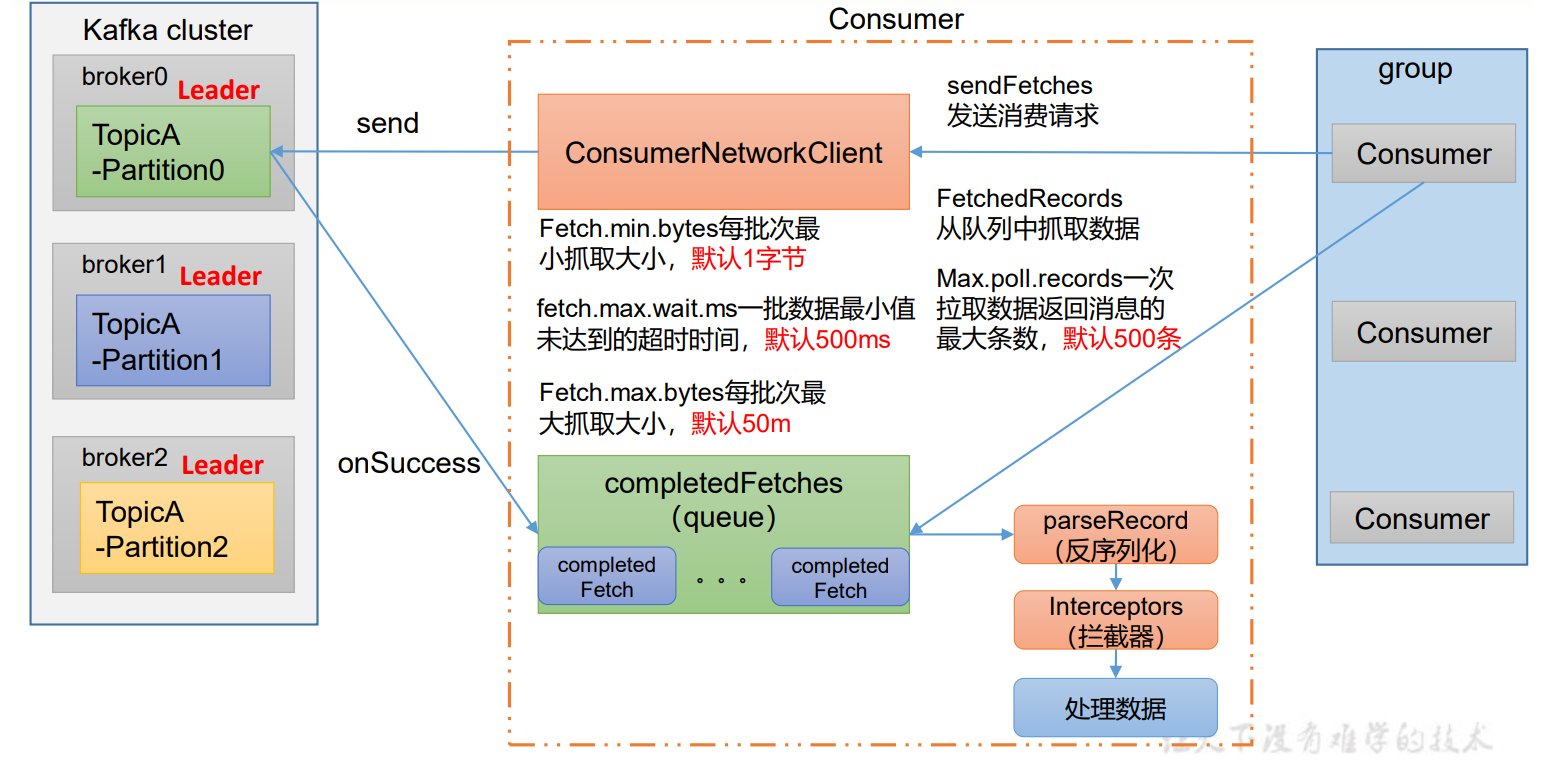
3.1 初始化
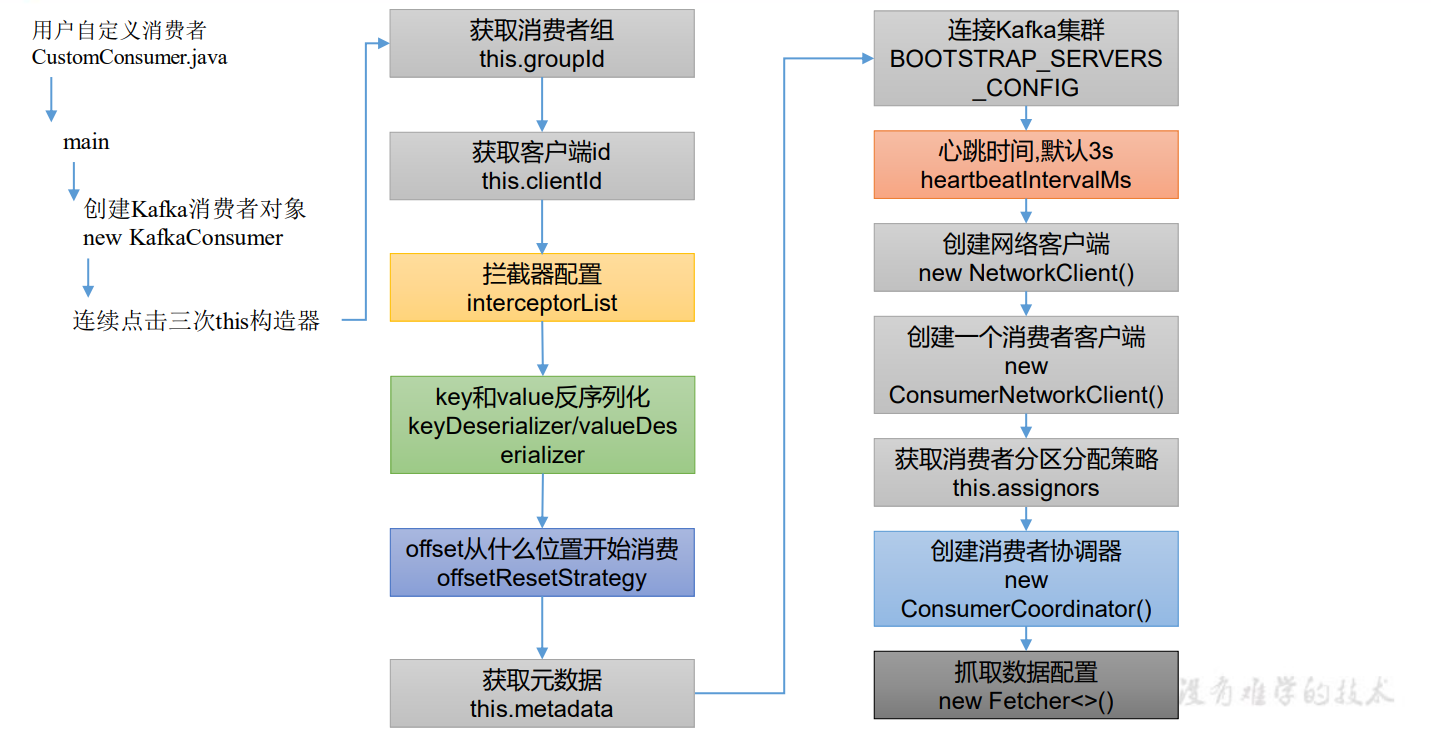
3.1.1 程序入口
1)从用户自己编写的 main 方法开始阅读
package com.atguigu.kafka.consumer;
import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.Collections;
import java.util.Properties;
public class CustomConsumer {
public static void main(String[] args) {
// 1.创建消费者的配置对象
Properties properties = new Properties();
// 2.给消费者配置对象添加参数
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092");
// 配置序列化 必须
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
// 配置消费者组(组名任意起名) 必须
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test");
try (KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(properties)) {
kafkaConsumer.subscribe(Collections.singletonList("first"));
while (true) {
// 设置 1s 中消费一批数据
ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(Duration.ofSeconds(1));
// 打印消费到的数据
consumerRecords.forEach(System.out::println);
}
}
}
}
3.1.2 消费者初始化
点击 main()方法中的 KafkaConsumer ()。
org.apache.kafka.clients.consumer.KafkaConsumer#KafkaConsumer(org.apache.kafka.clients.consumer.ConsumerConfig, org.apache.kafka.common.serialization.Deserializer
@SuppressWarnings("unchecked")
KafkaConsumer(ConsumerConfig config, Deserializer<K> keyDeserializer, Deserializer<V> valueDeserializer) {
try {
// 消费者组平衡
GroupRebalanceConfig groupRebalanceConfig = new GroupRebalanceConfig(config,
GroupRebalanceConfig.ProtocolType.CONSUMER);
// 获取消费者组id
this.groupId = Optional.ofNullable(groupRebalanceConfig.groupId);
// 客户端id
this.clientId = config.getString(CommonClientConfigs.CLIENT_ID_CONFIG);
LogContext logContext;
// If group.instance.id is set, we will append it to the log context.
if (groupRebalanceConfig.groupInstanceId.isPresent()) {
logContext = new LogContext("[Consumer instanceId=" + groupRebalanceConfig.groupInstanceId.get() +
", clientId=" + clientId + ", groupId=" + groupId.orElse("null") + "] ");
} else {
logContext = new LogContext("[Consumer clientId=" + clientId + ", groupId=" + groupId.orElse("null") + "] ");
}
this.log = logContext.logger(getClass());
boolean enableAutoCommit = config.maybeOverrideEnableAutoCommit();
groupId.ifPresent(groupIdStr -> {
if (groupIdStr.isEmpty()) {
log.warn("Support for using the empty group id by consumers is deprecated and will be removed in the next major release.");
}
});
log.debug("Initializing the Kafka consumer");
// 客户端请求服务端等待时间 默认是30s
this.requestTimeoutMs = config.getInt(ConsumerConfig.REQUEST_TIMEOUT_MS_CONFIG);
this.defaultApiTimeoutMs = config.getInt(ConsumerConfig.DEFAULT_API_TIMEOUT_MS_CONFIG);
this.time = Time.SYSTEM;
this.metrics = buildMetrics(config, time, clientId);
// 重试时间间隔 默认是100ms
this.retryBackoffMs = config.getLong(ConsumerConfig.RETRY_BACKOFF_MS_CONFIG);
// 拦截器
List<ConsumerInterceptor<K, V>> interceptorList = (List) config.getConfiguredInstances(
ConsumerConfig.INTERCEPTOR_CLASSES_CONFIG,
ConsumerInterceptor.class,
Collections.singletonMap(ConsumerConfig.CLIENT_ID_CONFIG, clientId));
this.interceptors = new ConsumerInterceptors<>(interceptorList);
// key和value的反序列化
if (keyDeserializer == null) {
this.keyDeserializer = config.getConfiguredInstance(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, Deserializer.class);
this.keyDeserializer.configure(config.originals(Collections.singletonMap(ConsumerConfig.CLIENT_ID_CONFIG, clientId)), true);
} else {
config.ignore(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG);
this.keyDeserializer = keyDeserializer;
}
if (valueDeserializer == null) {
this.valueDeserializer = config.getConfiguredInstance(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, Deserializer.class);
this.valueDeserializer.configure(config.originals(Collections.singletonMap(ConsumerConfig.CLIENT_ID_CONFIG, clientId)), false);
} else {
config.ignore(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG);
this.valueDeserializer = valueDeserializer;
}
// offset从什么位置开始消费 默认latest
OffsetResetStrategy offsetResetStrategy = OffsetResetStrategy.valueOf(config.getString(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG).toUpperCase(Locale.ROOT));
this.subscriptions = new SubscriptionState(logContext, offsetResetStrategy);
ClusterResourceListeners clusterResourceListeners = configureClusterResourceListeners(keyDeserializer,
valueDeserializer, metrics.reporters(), interceptorList);
// 元数据
// 配置是否可以消费系统主题数据
// 配置是否允许自动创建主题
this.metadata = new ConsumerMetadata(retryBackoffMs,
config.getLong(ConsumerConfig.METADATA_MAX_AGE_CONFIG),
!config.getBoolean(ConsumerConfig.EXCLUDE_INTERNAL_TOPICS_CONFIG),
config.getBoolean(ConsumerConfig.ALLOW_AUTO_CREATE_TOPICS_CONFIG),
subscriptions, logContext, clusterResourceListeners);
// 连接Kafka集群
List<InetSocketAddress> addresses = ClientUtils.parseAndValidateAddresses(
config.getList(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG), config.getString(ConsumerConfig.CLIENT_DNS_LOOKUP_CONFIG));
this.metadata.bootstrap(addresses);
String metricGrpPrefix = "consumer";
FetcherMetricsRegistry metricsRegistry = new FetcherMetricsRegistry(Collections.singleton(CLIENT_ID_METRIC_TAG), metricGrpPrefix);
ChannelBuilder channelBuilder = ClientUtils.createChannelBuilder(config, time, logContext);
this.isolationLevel = IsolationLevel.valueOf(
config.getString(ConsumerConfig.ISOLATION_LEVEL_CONFIG).toUpperCase(Locale.ROOT));
Sensor throttleTimeSensor = Fetcher.throttleTimeSensor(metrics, metricsRegistry);
// 心跳时间 默认 3s
int heartbeatIntervalMs = config.getInt(ConsumerConfig.HEARTBEAT_INTERVAL_MS_CONFIG);
ApiVersions apiVersions = new ApiVersions();
// 创建客户端对象
// 连接重试时间 默认50ms
// 最大连接重试时间 默认1s
// 发送缓存 默认128kb
// 接收缓存 默认64kb
NetworkClient netClient = new NetworkClient(
new Selector(config.getLong(ConsumerConfig.CONNECTIONS_MAX_IDLE_MS_CONFIG), metrics, time, metricGrpPrefix, channelBuilder, logContext),
this.metadata,
clientId,
100, // a fixed large enough value will suffice for max in-flight requests
config.getLong(ConsumerConfig.RECONNECT_BACKOFF_MS_CONFIG),
config.getLong(ConsumerConfig.RECONNECT_BACKOFF_MAX_MS_CONFIG),
config.getInt(ConsumerConfig.SEND_BUFFER_CONFIG),
config.getInt(ConsumerConfig.RECEIVE_BUFFER_CONFIG),
config.getInt(ConsumerConfig.REQUEST_TIMEOUT_MS_CONFIG),
config.getLong(ConsumerConfig.SOCKET_CONNECTION_SETUP_TIMEOUT_MS_CONFIG),
config.getLong(ConsumerConfig.SOCKET_CONNECTION_SETUP_TIMEOUT_MAX_MS_CONFIG),
time,
true,
apiVersions,
throttleTimeSensor,
logContext);
// 消费者客户端
this.client = new ConsumerNetworkClient(
logContext,
netClient,
metadata,
time,
retryBackoffMs,
config.getInt(ConsumerConfig.REQUEST_TIMEOUT_MS_CONFIG),
heartbeatIntervalMs); //Will avoid blocking an extended period of time to prevent heartbeat thread starvation
// 获取消费者分区分配策略
this.assignors = ConsumerPartitionAssignor.getAssignorInstances(
config.getList(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG),
config.originals(Collections.singletonMap(ConsumerConfig.CLIENT_ID_CONFIG, clientId))
);
// no coordinator will be constructed for the default (null) group id
// 为消费者组准备的
// AUTO_COMMIT_INTERVAL_MS_CONFIG 自动提交offset时间 默认5s
this.coordinator = !groupId.isPresent() ? null :
new ConsumerCoordinator(groupRebalanceConfig,
logContext,
this.client,
assignors,
this.metadata,
this.subscriptions,
metrics,
metricGrpPrefix,
this.time,
enableAutoCommit,
config.getInt(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG),
this.interceptors,
config.getBoolean(ConsumerConfig.THROW_ON_FETCH_STABLE_OFFSET_UNSUPPORTED));
// 抓取数据配置
// 一次抓取最小值,默认1个字节
// 一次抓取最大值,默认50m
// 一次抓取最大等待时间,默认500ms
// 每个分区抓取的最大字节数,默认1m
// 一次poll拉取数据返回消息的最大条数,默认是500条。
// key和value的反序列化
this.fetcher = new Fetcher<>(
logContext,
this.client,
config.getInt(ConsumerConfig.FETCH_MIN_BYTES_CONFIG),
config.getInt(ConsumerConfig.FETCH_MAX_BYTES_CONFIG),
config.getInt(ConsumerConfig.FETCH_MAX_WAIT_MS_CONFIG),
config.getInt(ConsumerConfig.MAX_PARTITION_FETCH_BYTES_CONFIG),
config.getInt(ConsumerConfig.MAX_POLL_RECORDS_CONFIG),
config.getBoolean(ConsumerConfig.CHECK_CRCS_CONFIG),
config.getString(ConsumerConfig.CLIENT_RACK_CONFIG),
this.keyDeserializer,
this.valueDeserializer,
this.metadata,
this.subscriptions,
metrics,
metricsRegistry,
this.time,
this.retryBackoffMs,
this.requestTimeoutMs,
isolationLevel,
apiVersions);
this.kafkaConsumerMetrics = new KafkaConsumerMetrics(metrics, metricGrpPrefix);
config.logUnused();
AppInfoParser.registerAppInfo(JMX_PREFIX, clientId, metrics, time.milliseconds());
log.debug("Kafka consumer initialized");
} catch (Throwable t) {
// call close methods if internal objects are already constructed; this is to prevent resource leak. see KAFKA-2121
// we do not need to call `close` at all when `log` is null, which means no internal objects were initialized.
if (this.log != null) {
close(0, true);
}
// now propagate the exception
throw new KafkaException("Failed to construct kafka consumer", t);
}
}
3.2 消费者订阅主题

点击自己编写的 CustomConsumer.java 中的 subscribe ()方法。
kafkaConsumer.subscribe(Collections.singletonList("first"));
org.apache.kafka.clients.consumer.KafkaConsumer#subscribe(java.util.Collection<java.lang.String>, org.apache.kafka.clients.consumer.ConsumerRebalanceListener)
/**
* Subscribe to the given list of topics to get dynamically
* assigned partitions. <b>Topic subscriptions are not incremental. This list will replace the current
* assignment (if there is one).</b> Note that it is not possible to combine topic subscription with group management
* with manual partition assignment through {@link #assign(Collection)}.
*
* If the given list of topics is empty, it is treated the same as {@link #unsubscribe()}.
*
* <p>
* As part of group management, the consumer will keep track of the list of consumers that belong to a particular
* group and will trigger a rebalance operation if any one of the following events are triggered:
* <ul>
* <li>Number of partitions change for any of the subscribed topics
* <li>A subscribed topic is created or deleted
* <li>An existing member of the consumer group is shutdown or fails
* <li>A new member is added to the consumer group
* </ul>
* <p>
* When any of these events are triggered, the provided listener will be invoked first to indicate that
* the consumer's assignment has been revoked, and then again when the new assignment has been received.
* Note that rebalances will only occur during an active call to {@link #poll(Duration)}, so callbacks will
* also only be invoked during that time.
*
* The provided listener will immediately override any listener set in a previous call to subscribe.
* It is guaranteed, however, that the partitions revoked/assigned through this interface are from topics
* subscribed in this call. See {@link ConsumerRebalanceListener} for more details.
*
* @param topics The list of topics to subscribe to
* @param listener Non-null listener instance to get notifications on partition assignment/revocation for the
* subscribed topics
* @throws IllegalArgumentException If topics is null or contains null or empty elements, or if listener is null
* @throws IllegalStateException If {@code subscribe()} is called previously with pattern, or assign is called
* previously (without a subsequent call to {@link #unsubscribe()}), or if not
* configured at-least one partition assignment strategy
*/
@Override
public void subscribe(Collection<String> topics, ConsumerRebalanceListener listener) {
acquireAndEnsureOpen();
try {
maybeThrowInvalidGroupIdException();
// 要订阅的主题如果为null,直接抛异常
if (topics == null)
throw new IllegalArgumentException("Topic collection to subscribe to cannot be null");
// 要订阅的主题如果为空
if (topics.isEmpty()) {
// treat subscribing to empty topic list as the same as unsubscribing
this.unsubscribe();
} else {
// 正常的处理操作
for (String topic : topics) {
// 如果为空,抛异常
if (Utils.isBlank(topic))
throw new IllegalArgumentException("Topic collection to subscribe to cannot contain null or empty topic");
}
throwIfNoAssignorsConfigured();
// 清空订阅异常主题的缓存数据
fetcher.clearBufferedDataForUnassignedTopics(topics);
log.info("Subscribed to topic(s): {}", Utils.join(topics, ", "));
// 判断是否需要更改订阅主题,如果需要更改主题,则更新元数据信息
if (this.subscriptions.subscribe(new HashSet<>(topics), listener))
metadata.requestUpdateForNewTopics();
}
} finally {
release();
}
}
org.apache.kafka.clients.consumer.internals.SubscriptionState#subscribe(java.util.Set<java.lang.String>, org.apache.kafka.clients.consumer.ConsumerRebalanceListener)
public synchronized boolean subscribe(Set<String> topics, ConsumerRebalanceListener listener) {
// 注册负载均衡监听器(例如消费者组中,其他消费者退出触发再平衡)
registerRebalanceListener(listener);
// 按照设置的主题开始订阅,自动分配分区
setSubscriptionType(SubscriptionType.AUTO_TOPICS);
// 修改订阅主题信息
return changeSubscription(topics);
}
org.apache.kafka.clients.consumer.internals.SubscriptionState#changeSubscription
private boolean changeSubscription(Set<String> topicsToSubscribe) {
// 如果订阅的主题和以前订阅的一致,就不需要修改订阅信息。如果不一致,就需要修改。
if (subscription.equals(topicsToSubscribe))
return false;
subscription = topicsToSubscribe;
return true;
}
org.apache.kafka.clients.Metadata#requestUpdateForNewTopics
public synchronized int requestUpdateForNewTopics() {
// 如果订阅的和以前不一致,需要更新元数据信息
// Override the timestamp of last refresh to let immediate update.
this.lastRefreshMs = 0;
this.needPartialUpdate = true;
this.requestVersion++;
return this.updateVersion;
}
3.3 消费者拉取和处理数据
3.3.1 消费总体流程
点击自己编写的 CustomConsumer.java 中的 poll ()方法。
// 设置 1s 中消费一批数据
ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(Duration.ofSeconds(1));
org.apache.kafka.clients.consumer.KafkaConsumer#poll(java.time.Duration)
@Override
public ConsumerRecords<K, V> poll(final Duration timeout) {
return poll(time.timer(timeout), true);
}
org.apache.kafka.clients.consumer.KafkaConsumer#poll(org.apache.kafka.common.utils.Timer, boolean)
/**
* @throws KafkaException if the rebalance callback throws exception
*/
private ConsumerRecords<K, V> poll(final Timer timer, final boolean includeMetadataInTimeout) {
acquireAndEnsureOpen();
try {
this.kafkaConsumerMetrics.recordPollStart(timer.currentTimeMs());
if (this.subscriptions.hasNoSubscriptionOrUserAssignment()) {
throw new IllegalStateException("Consumer is not subscribed to any topics or assigned any partitions");
}
do {
client.maybeTriggerWakeup();
if (includeMetadataInTimeout) {
// try to update assignment metadata BUT do not need to block on the timer for join group
// 1. 消费者 or 消费者组初始化
updateAssignmentMetadataIfNeeded(timer, false);
} else {
while (!updateAssignmentMetadataIfNeeded(time.timer(Long.MAX_VALUE), true)) {
log.warn("Still waiting for metadata");
}
}
// 2. 抓取数据
final Map<TopicPartition, List<ConsumerRecord<K, V>>> records = pollForFetches(timer);
if (!records.isEmpty()) {
// before returning the fetched records, we can send off the next round of fetches
// and avoid block waiting for their responses to enable pipelining while the user
// is handling the fetched records.
//
// NOTE: since the consumed position has already been updated, we must not allow
// wakeups or any other errors to be triggered prior to returning the fetched records.
if (fetcher.sendFetches() > 0 || client.hasPendingRequests()) {
client.transmitSends();
}
// 3. 拦截器处理数据
return this.interceptors.onConsume(new ConsumerRecords<>(records));
}
} while (timer.notExpired());
return ConsumerRecords.empty();
} finally {
release();
this.kafkaConsumerMetrics.recordPollEnd(timer.currentTimeMs());
}
}
3.3.2 消费者/消费者组初始化
org.apache.kafka.clients.consumer.KafkaConsumer#updateAssignmentMetadataIfNeeded(org.apache.kafka.common.utils.Timer, boolean)
boolean updateAssignmentMetadataIfNeeded(final Timer timer, final boolean waitForJoinGroup) {
if (coordinator != null && !coordinator.poll(timer, waitForJoinGroup)) {
return false;
}
return updateFetchPositions(timer);
}
org.apache.kafka.clients.consumer.internals.ConsumerCoordinator#poll(org.apache.kafka.common.utils.Timer, boolean)
/**
* Poll for coordinator events. This ensures that the coordinator is known and that the consumer
* has joined the group (if it is using group management). This also handles periodic offset commits
* if they are enabled.
* <p>
* Returns early if the timeout expires or if waiting on rejoin is not required
*
* @param timer Timer bounding how long this method can block
* @param waitForJoinGroup Boolean flag indicating if we should wait until re-join group completes
* @throws KafkaException if the rebalance callback throws an exception
* @return true iff the operation succeeded
*/
public boolean poll(Timer timer, boolean waitForJoinGroup) {
// 获取最新元数据
maybeUpdateSubscriptionMetadata();
invokeCompletedOffsetCommitCallbacks();
if (subscriptions.hasAutoAssignedPartitions()) {
if (protocol == null) {
throw new IllegalStateException("User configured " + ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG +
" to empty while trying to subscribe for group protocol to auto assign partitions");
}
// Always update the heartbeat last poll time so that the heartbeat thread does not leave the
// group proactively due to application inactivity even if (say) the coordinator cannot be found.
// 3s心跳
pollHeartbeat(timer.currentTimeMs());
// 判断coordinator是否准备好了
if (coordinatorUnknown() && !ensureCoordinatorReady(timer)) {
return false;
}
// 判断是否需要加入消费者组
if (rejoinNeededOrPending()) {
// due to a race condition between the initial metadata fetch and the initial rebalance,
// we need to ensure that the metadata is fresh before joining initially. This ensures
// that we have matched the pattern against the cluster's topics at least once before joining.
if (subscriptions.hasPatternSubscription()) {
// For consumer group that uses pattern-based subscription, after a topic is created,
// any consumer that discovers the topic after metadata refresh can trigger rebalance
// across the entire consumer group. Multiple rebalances can be triggered after one topic
// creation if consumers refresh metadata at vastly different times. We can significantly
// reduce the number of rebalances caused by single topic creation by asking consumer to
// refresh metadata before re-joining the group as long as the refresh backoff time has
// passed.
if (this.metadata.timeToAllowUpdate(timer.currentTimeMs()) == 0) {
this.metadata.requestUpdate();
}
if (!client.ensureFreshMetadata(timer)) {
return false;
}
maybeUpdateSubscriptionMetadata();
}
// if not wait for join group, we would just use a timer of 0
if (!ensureActiveGroup(waitForJoinGroup ? timer : time.timer(0L))) {
// since we may use a different timer in the callee, we'd still need
// to update the original timer's current time after the call
timer.update(time.milliseconds());
return false;
}
}
} else {
// For manually assigned partitions, if there are no ready nodes, await metadata.
// If connections to all nodes fail, wakeups triggered while attempting to send fetch
// requests result in polls returning immediately, causing a tight loop of polls. Without
// the wakeup, poll() with no channels would block for the timeout, delaying re-connection.
// awaitMetadataUpdate() initiates new connections with configured backoff and avoids the busy loop.
// When group management is used, metadata wait is already performed for this scenario as
// coordinator is unknown, hence this check is not required.
if (metadata.updateRequested() && !client.hasReadyNodes(timer.currentTimeMs())) {
client.awaitMetadataUpdate(timer);
}
}
// 是否自动提交 offset
maybeAutoCommitOffsetsAsync(timer.currentTimeMs());
return true;
}
org.apache.kafka.clients.consumer.internals.AbstractCoordinator#ensureCoordinatorReady
/**
* Visible for testing.
*
* Ensure that the coordinator is ready to receive requests.
*
* @param timer Timer bounding how long this method can block
* @return true If coordinator discovery and initial connection succeeded, false otherwise
*/
protected synchronized boolean ensureCoordinatorReady(final Timer timer) {
// 如果找到 coordinator,直接返回
if (!coordinatorUnknown())
return true;
// 如果没有找到,循环给服务器端发送请求,直到找到 coordinator
do {
if (fatalFindCoordinatorException != null) {
final RuntimeException fatalException = fatalFindCoordinatorException;
fatalFindCoordinatorException = null;
throw fatalException;
}
// 创建寻找coordinator的请求 并发送
final RequestFuture<Void> future = lookupCoordinator();
// 获取服务端返回的结果
client.poll(future, timer);
if (!future.isDone()) {
// ran out of time
break;
}
RuntimeException fatalException = null;
if (future.failed()) {
if (future.isRetriable()) {
log.debug("Coordinator discovery failed, refreshing metadata", future.exception());
client.awaitMetadataUpdate(timer);
} else {
fatalException = future.exception();
log.info("FindCoordinator request hit fatal exception", fatalException);
}
} else if (coordinator != null && client.isUnavailable(coordinator)) {
// we found the coordinator, but the connection has failed, so mark
// it dead and backoff before retrying discovery
markCoordinatorUnknown("coordinator unavailable");
timer.sleep(rebalanceConfig.retryBackoffMs);
}
clearFindCoordinatorFuture();
if (fatalException != null)
throw fatalException;
} while (coordinatorUnknown() && timer.notExpired());
return !coordinatorUnknown();
}
org.apache.kafka.clients.consumer.internals.AbstractCoordinator#lookupCoordinator
protected synchronized RequestFuture<Void> lookupCoordinator() {
if (findCoordinatorFuture == null) {
// find a node to ask about the coordinator
Node node = this.client.leastLoadedNode();
if (node == null) {
log.debug("No broker available to send FindCoordinator request");
return RequestFuture.noBrokersAvailable();
} else {
// 向服务器端发送查找Coordinator请求
findCoordinatorFuture = sendFindCoordinatorRequest(node);
}
}
return findCoordinatorFuture;
}
org.apache.kafka.clients.consumer.internals.AbstractCoordinator#sendFindCoordinatorRequest
/**
* Discover the current coordinator for the group. Sends a GroupMetadata request to
* one of the brokers. The returned future should be polled to get the result of the request.
* @return A request future which indicates the completion of the metadata request
*/
private RequestFuture<Void> sendFindCoordinatorRequest(Node node) {
// initiate the group metadata request
log.debug("Sending FindCoordinator request to broker {}", node);
// 封装发送请求
FindCoordinatorRequestData data = new FindCoordinatorRequestData()
.setKeyType(CoordinatorType.GROUP.id())
.setKey(this.rebalanceConfig.groupId);
FindCoordinatorRequest.Builder requestBuilder = new FindCoordinatorRequest.Builder(data);
// 消费者向服务器端发送请求
return client.send(node, requestBuilder)
.compose(new FindCoordinatorResponseHandler());
}
3.3.3 拉取数据
1)开始拉取数据
org.apache.kafka.clients.consumer.KafkaConsumer#pollForFetches
/**
* @throws KafkaException if the rebalance callback throws exception
*/
private Map<TopicPartition, List<ConsumerRecord<K, V>>> pollForFetches(Timer timer) {
long pollTimeout = coordinator == null ? timer.remainingMs() :
Math.min(coordinator.timeToNextPoll(timer.currentTimeMs()), timer.remainingMs());
// 第一次拉取不到数据
// if data is available already, return it immediately
final Map<TopicPartition, List<ConsumerRecord<K, V>>> records = fetcher.fetchedRecords();
if (!records.isEmpty()) {
return records;
}
// 发送请求并抓取数据
// send any new fetches (won't resend pending fetches)
fetcher.sendFetches();
// We do not want to be stuck blocking in poll if we are missing some positions
// since the offset lookup may be backing off after a failure
// NOTE: the use of cachedSubscriptionHashAllFetchPositions means we MUST call
// updateAssignmentMetadataIfNeeded before this method.
if (!cachedSubscriptionHashAllFetchPositions && pollTimeout > retryBackoffMs) {
pollTimeout = retryBackoffMs;
}
log.trace("Polling for fetches with timeout {}", pollTimeout);
Timer pollTimer = time.timer(pollTimeout);
client.poll(pollTimer, () -> {
// since a fetch might be completed by the background thread, we need this poll condition
// to ensure that we do not block unnecessarily in poll()
return !fetcher.hasAvailableFetches();
});
timer.update(pollTimer.currentTimeMs());
// 把数据按照分区封装好后,一次处理默认 500 条数据
return fetcher.fetchedRecords();
}
2)发送请求并抓取数据
org.apache.kafka.clients.consumer.internals.Fetcher#sendFetches
/**
* Set-up a fetch request for any node that we have assigned partitions for which doesn't already have
* an in-flight fetch or pending fetch data.
* @return number of fetches sent
*/
public synchronized int sendFetches() {
// Update metrics in case there was an assignment change
sensors.maybeUpdateAssignment(subscriptions);
Map<Node, FetchSessionHandler.FetchRequestData> fetchRequestMap = prepareFetchRequests();
for (Map.Entry<Node, FetchSessionHandler.FetchRequestData> entry : fetchRequestMap.entrySet()) {
final Node fetchTarget = entry.getKey();
final FetchSessionHandler.FetchRequestData data = entry.getValue();
final short maxVersion;
if (!data.canUseTopicIds()) {
maxVersion = (short) 12;
} else {
maxVersion = ApiKeys.FETCH.latestVersion();
}
// 初始化抓取数据的参数:
// 最大等待时间默认 500ms
// 最小抓取一个字节
// 最大抓取 50m 数据
final FetchRequest.Builder request = FetchRequest.Builder
.forConsumer(maxVersion, this.maxWaitMs, this.minBytes, data.toSend())
.isolationLevel(isolationLevel)
.setMaxBytes(this.maxBytes)
.metadata(data.metadata())
.removed(data.toForget())
.replaced(data.toReplace())
.rackId(clientRackId);
if (log.isDebugEnabled()) {
log.debug("Sending {} {} to broker {}", isolationLevel, data.toString(), fetchTarget);
}
RequestFuture<ClientResponse> future = client.send(fetchTarget, request);
// We add the node to the set of nodes with pending fetch requests before adding the
// listener because the future may have been fulfilled on another thread (e.g. during a
// disconnection being handled by the heartbeat thread) which will mean the listener
// will be invoked synchronously.
this.nodesWithPendingFetchRequests.add(entry.getKey().id());
// 监听服务器端返回的数据
future.addListener(new RequestFutureListener<ClientResponse>() {
@Override
public void onSuccess(ClientResponse resp) {
// 成功接收服务器端数据
synchronized (Fetcher.this) {
try {
// 获取服务器端响应数据
FetchResponse response = (FetchResponse) resp.responseBody();
FetchSessionHandler handler = sessionHandler(fetchTarget.id());
if (handler == null) {
log.error("Unable to find FetchSessionHandler for node {}. Ignoring fetch response.",
fetchTarget.id());
return;
}
if (!handler.handleResponse(response, resp.requestHeader().apiVersion())) {
if (response.error() == Errors.FETCH_SESSION_TOPIC_ID_ERROR) {
metadata.requestUpdate();
}
return;
}
Map<TopicPartition, FetchResponseData.PartitionData> responseData = response.responseData(handler.sessionTopicNames(), resp.requestHeader().apiVersion());
Set<TopicPartition> partitions = new HashSet<>(responseData.keySet());
FetchResponseMetricAggregator metricAggregator = new FetchResponseMetricAggregator(sensors, partitions);
for (Map.Entry<TopicPartition, FetchResponseData.PartitionData> entry : responseData.entrySet()) {
TopicPartition partition = entry.getKey();
FetchRequest.PartitionData requestData = data.sessionPartitions().get(partition);
if (requestData == null) {
String message;
if (data.metadata().isFull()) {
message = MessageFormatter.arrayFormat(
"Response for missing full request partition: partition={}; metadata={}",
new Object[]{partition, data.metadata()}).getMessage();
} else {
message = MessageFormatter.arrayFormat(
"Response for missing session request partition: partition={}; metadata={}; toSend={}; toForget={}; toReplace={}",
new Object[]{partition, data.metadata(), data.toSend(), data.toForget(), data.toReplace()}).getMessage();
}
// Received fetch response for missing session partition
throw new IllegalStateException(message);
} else {
long fetchOffset = requestData.fetchOffset;
FetchResponseData.PartitionData partitionData = entry.getValue();
log.debug("Fetch {} at offset {} for partition {} returned fetch data {}",
isolationLevel, fetchOffset, partition, partitionData);
Iterator<? extends RecordBatch> batches = FetchResponse.recordsOrFail(partitionData).batches().iterator();
short responseVersion = resp.requestHeader().apiVersion();
completedFetches.add(new CompletedFetch(partition, partitionData,
metricAggregator, batches, fetchOffset, responseVersion));
}
}
sensors.fetchLatency.record(resp.requestLatencyMs());
} finally {
nodesWithPendingFetchRequests.remove(fetchTarget.id());
}
}
}
@Override
public void onFailure(RuntimeException e) {
synchronized (Fetcher.this) {
try {
FetchSessionHandler handler = sessionHandler(fetchTarget.id());
if (handler != null) {
handler.handleError(e);
}
} finally {
nodesWithPendingFetchRequests.remove(fetchTarget.id());
}
}
}
});
}
return fetchRequestMap.size();
}
3)把数据按照分区封装好后,一次处理最大条数默认 500 条数据
org.apache.kafka.clients.consumer.internals.Fetcher#fetchedRecords
/**
* Return the fetched records, empty the record buffer and update the consumed position.
*
* NOTE: returning empty records guarantees the consumed position are NOT updated.
*
* @return The fetched records per partition
* @throws OffsetOutOfRangeException If there is OffsetOutOfRange error in fetchResponse and
* the defaultResetPolicy is NONE
* @throws TopicAuthorizationException If there is TopicAuthorization error in fetchResponse.
*/
public Map<TopicPartition, List<ConsumerRecord<K, V>>> fetchedRecords() {
Map<TopicPartition, List<ConsumerRecord<K, V>>> fetched = new HashMap<>();
Queue<CompletedFetch> pausedCompletedFetches = new ArrayDeque<>();
// 一次处理的最大条数,默认 500 条
int recordsRemaining = maxPollRecords;
try {
// 循环处理
while (recordsRemaining > 0) {
if (nextInLineFetch == null || nextInLineFetch.isConsumed) {
// 从缓存中获取数据
CompletedFetch records = completedFetches.peek();
// 缓存中数据为 null,直接跳出循环
if (records == null) break;
if (records.notInitialized()) {
try {
nextInLineFetch = initializeCompletedFetch(records);
} catch (Exception e) {
// Remove a completedFetch upon a parse with exception if (1) it contains no records, and
// (2) there are no fetched records with actual content preceding this exception.
// The first condition ensures that the completedFetches is not stuck with the same completedFetch
// in cases such as the TopicAuthorizationException, and the second condition ensures that no
// potential data loss due to an exception in a following record.
FetchResponseData.PartitionData partition = records.partitionData;
if (fetched.isEmpty() && FetchResponse.recordsOrFail(partition).sizeInBytes() == 0) {
completedFetches.poll();
}
throw e;
}
} else {
nextInLineFetch = records;
}
// 从缓存中拉取数据
completedFetches.poll();
} else if (subscriptions.isPaused(nextInLineFetch.partition)) {
// when the partition is paused we add the records back to the completedFetches queue instead of draining
// them so that they can be returned on a subsequent poll if the partition is resumed at that time
log.debug("Skipping fetching records for assigned partition {} because it is paused", nextInLineFetch.partition);
pausedCompletedFetches.add(nextInLineFetch);
nextInLineFetch = null;
} else {
List<ConsumerRecord<K, V>> records = fetchRecords(nextInLineFetch, recordsRemaining);
if (!records.isEmpty()) {
TopicPartition partition = nextInLineFetch.partition;
List<ConsumerRecord<K, V>> currentRecords = fetched.get(partition);
if (currentRecords == null) {
fetched.put(partition, records);
} else {
// this case shouldn't usually happen because we only send one fetch at a time per partition,
// but it might conceivably happen in some rare cases (such as partition leader changes).
// we have to copy to a new list because the old one may be immutable
List<ConsumerRecord<K, V>> newRecords = new ArrayList<>(records.size() + currentRecords.size());
newRecords.addAll(currentRecords);
newRecords.addAll(records);
fetched.put(partition, newRecords);
}
recordsRemaining -= records.size();
}
}
}
} catch (KafkaException e) {
if (fetched.isEmpty())
throw e;
} finally {
// add any polled completed fetches for paused partitions back to the completed fetches queue to be
// re-evaluated in the next poll
completedFetches.addAll(pausedCompletedFetches);
}
return fetched;
}
3.3.4 拦截器处理数据
在 poll()方法中点击 onConsume()方法。
// 从集合中拉取数据处理,首先经过的是拦截器
return this.interceptors.onConsume(new ConsumerRecords<>(records));
/**
* This is called when the records are about to be returned to the user.
* <p>
* This method calls {@link ConsumerInterceptor#onConsume(ConsumerRecords)} for each
* interceptor. Records returned from each interceptor get passed to onConsume() of the next interceptor
* in the chain of interceptors.
* <p>
* This method does not throw exceptions. If any of the interceptors in the chain throws an exception,
* it gets caught and logged, and next interceptor in the chain is called with 'records' returned by the
* previous successful interceptor onConsume call.
*
* @param records records to be consumed by the client.
* @return records that are either modified by interceptors or same as records passed to this method.
*/
public ConsumerRecords<K, V> onConsume(ConsumerRecords<K, V> records) {
ConsumerRecords<K, V> interceptRecords = records;
for (ConsumerInterceptor<K, V> interceptor : this.interceptors) {
try {
interceptRecords = interceptor.onConsume(interceptRecords);
} catch (Exception e) {
// do not propagate interceptor exception, log and continue calling other interceptors
log.warn("Error executing interceptor onConsume callback", e);
}
}
return interceptRecords;
}
3.4 消费者 Offset 提交

3.4.1 手动同步提交 Offset
// 同步提交 offset
kafkaConsumer.commitSync();
org.apache.kafka.clients.consumer.KafkaConsumer#commitSync(java.util.Map<org.apache.kafka.common.TopicPartition,org.apache.kafka.clients.consumer.OffsetAndMetadata>, java.time.Duration)
@Override
public void commitSync(final Map<TopicPartition, OffsetAndMetadata> offsets, final Duration timeout) {
acquireAndEnsureOpen();
long commitStart = time.nanoseconds();
try {
maybeThrowInvalidGroupIdException();
offsets.forEach(this::updateLastSeenEpochIfNewer);
// 同步提交
if (!coordinator.commitOffsetsSync(new HashMap<>(offsets), time.timer(timeout))) {
throw new TimeoutException("Timeout of " + timeout.toMillis() + "ms expired before successfully " +
"committing offsets " + offsets);
}
} finally {
kafkaConsumerMetrics.recordCommitSync(time.nanoseconds() - commitStart);
release();
}
}
org.apache.kafka.clients.consumer.internals.ConsumerCoordinator#commitOffsetsSync
/**
* Commit offsets synchronously. This method will retry until the commit completes successfully
* or an unrecoverable error is encountered.
* @param offsets The offsets to be committed
* @throws org.apache.kafka.common.errors.AuthorizationException if the consumer is not authorized to the group
* or to any of the specified partitions. See the exception for more details
* @throws CommitFailedException if an unrecoverable error occurs before the commit can be completed
* @throws FencedInstanceIdException if a static member gets fenced
* @return If the offset commit was successfully sent and a successful response was received from
* the coordinator
*/
public boolean commitOffsetsSync(Map<TopicPartition, OffsetAndMetadata> offsets, Timer timer) {
invokeCompletedOffsetCommitCallbacks();
if (offsets.isEmpty())
return true;
do {
if (coordinatorUnknown() && !ensureCoordinatorReady(timer)) {
return false;
}
// 发送提交请求
RequestFuture<Void> future = sendOffsetCommitRequest(offsets);
client.poll(future, timer);
// We may have had in-flight offset commits when the synchronous commit began. If so, ensure that
// the corresponding callbacks are invoked prior to returning in order to preserve the order that
// the offset commits were applied.
invokeCompletedOffsetCommitCallbacks();
// 提交成功
if (future.succeeded()) {
if (interceptors != null)
interceptors.onCommit(offsets);
return true;
}
if (future.failed() && !future.isRetriable())
throw future.exception();
timer.sleep(rebalanceConfig.retryBackoffMs);
} while (timer.notExpired());
return false;
}
3.4.2 手动异步提交 Offset
手动异步提交 Offset
// 异步提交 offset
kafkaConsumer.commitAsync();
org.apache.kafka.clients.consumer.KafkaConsumer#commitAsync(java.util.Map<org.apache.kafka.common.TopicPartition,org.apache.kafka.clients.consumer.OffsetAndMetadata>, org.apache.kafka.clients.consumer.OffsetCommitCallback)
@Override
public void commitAsync(final Map<TopicPartition, OffsetAndMetadata> offsets, OffsetCommitCallback callback) {
acquireAndEnsureOpen();
try {
maybeThrowInvalidGroupIdException();
log.debug("Committing offsets: {}", offsets);
offsets.forEach(this::updateLastSeenEpochIfNewer);
// 异步提交
coordinator.commitOffsetsAsync(new HashMap<>(offsets), callback);
} finally {
release();
}
}
org.apache.kafka.clients.consumer.internals.ConsumerCoordinator#commitOffsetsAsync
public void commitOffsetsAsync(final Map<TopicPartition, OffsetAndMetadata> offsets, final OffsetCommitCallback callback) {
invokeCompletedOffsetCommitCallbacks();
if (!coordinatorUnknown()) {
doCommitOffsetsAsync(offsets, callback);
} else {
// we don't know the current coordinator, so try to find it and then send the commit
// or fail (we don't want recursive retries which can cause offset commits to arrive
// out of order). Note that there may be multiple offset commits chained to the same
// coordinator lookup request. This is fine because the listeners will be invoked in
// the same order that they were added. Note also that AbstractCoordinator prevents
// multiple concurrent coordinator lookup requests.
pendingAsyncCommits.incrementAndGet();
// 监听提交 offset 的结果
lookupCoordinator().addListener(new RequestFutureListener<Void>() {
@Override
public void onSuccess(Void value) {
pendingAsyncCommits.decrementAndGet();
doCommitOffsetsAsync(offsets, callback);
client.pollNoWakeup();
}
@Override
public void onFailure(RuntimeException e) {
pendingAsyncCommits.decrementAndGet();
completedOffsetCommits.add(new OffsetCommitCompletion(callback, offsets,
new RetriableCommitFailedException(e)));
}
});
}
// ensure the commit has a chance to be transmitted (without blocking on its completion).
// Note that commits are treated as heartbeats by the coordinator, so there is no need to
// explicitly allow heartbeats through delayed task execution.
client.pollNoWakeup();
}
本文作者:我係死肥宅
本文链接:https://www.cnblogs.com/iamfatotaku/p/16215865.html
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步