

书写高质量sql的一些建议
It's better to light a candle than to curse the darkness
-
老生常谈的不要使用
select *如果硬要使用select *,那么就请忍受一下以下几种可能会出现的问题
- select * 每次都把所有的字段查询出来,但并不是每个字段都是必要的,会造成额外的传输带宽资源,性能不可取
- 在完成分析之后,MySql会进行优化,也就是选择执行效率最高的(Mysql自己认为的,但并不一定是最优),使用select * 会阻碍优化器选择更优的执行计划,比如走索引查询
- 增加或删除字段的时候代码会出现问题,典型的就是如果添加一个新字段,但是实体映射忘记添加,程序会出错
-
仅查一条数据的时候,使用LIMIT 1
当某个业务你确信只会返回一行数据,就可以使用LIMIT 1来告诉执行引擎找到一行记录后就停止下来,而不是继续往下查下一条满足的记录,性能会好一点
-
使用union all替代union
union all 和 union的区别在于前者不会对数据进行去重,后者会去重,所以如果确信业务中不会存在重复的记录值,使用union all效率会更高
-
where后面尽量不要使用or来连接查询条件
如果硬要使用or,那么就代表你要放弃走索引,选择全表扫描
⭐可以采用union all
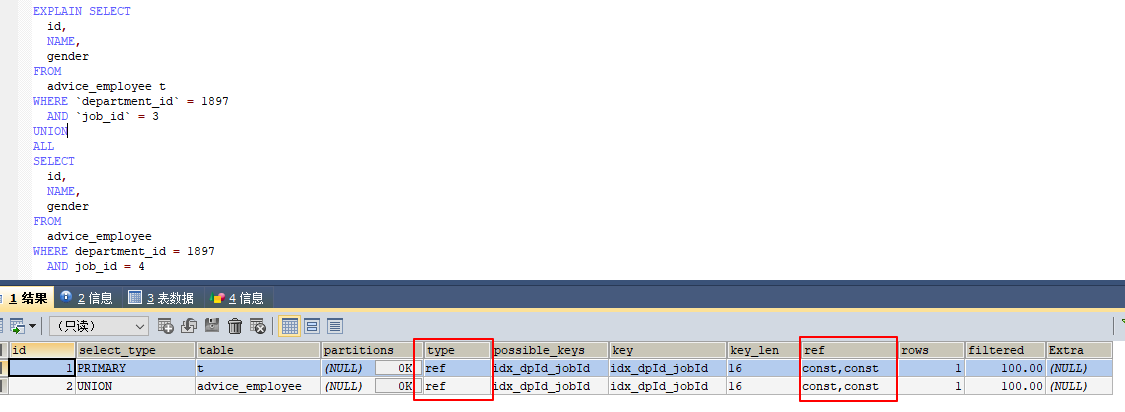
-
⚠️where后面谨慎使用in/not in,like
使用in、not in、like,其实还是会有走索引的时候的
in、not in在数量不多的时候,索引级别会去到range,一旦超出数量,索引也是会失效的,采用全表扫描


like只有一种情况会走索引,那就是确定前缀情况,如下例子就是确定前缀是以abc开头的

⭐可以使用exists来替换in,但是得视乎于场合;如果是一个连续的区间值,可以使用between and来替代in;
如果还是要做模糊索引,可以选择建立fulltext索引,或者直接走其他高效方式,例如ES等
-
关于exists和in的选择
exists是先遍历外表,然后看外表中的记录有没有跟内表中的匹配,适合内表较大,外表较小的情况
in是先遍历内表,然后将内表与外表做一个笛卡尔积,适合内表比较小的情况
-
联合索引需要遵循最左匹配原则
索引可以是一个列字段,也可以是多个列字段组成的联合索引,对于最左匹配原则,要从最左边作为起点开始匹配,而后如果遇到范围查询就会停止匹配,所以如果建立一个索引值为(a,b,c,d),那么where后面的条件必须是以a开头才能确保能走索引,如果其中c是一个范围查询(>, <, between, like),那么后续的d就走不到索引了
-
优先考虑在where 以及 order by 涉及的列上建立索引
索引区分度公式:$count(distinct(col)) / count(*)$,表示字段不重复的比率,比率越高,扫描的记录就会越少,效率自然也就越高
where后面接的是条件查询,order by是做分组,是做索引的好时机
-
索引列要保持干净,一定不能参与计算和使用函数,否则索引会失效
且看例子,索引有效

使用了substring函数操作索引列,索引失效

相似的还有,四则运算也会使得索引失效

-
能使用覆盖索引就使用覆盖索引
得先了解,聚簇索引和非聚簇索引这俩概念
聚簇索引:以主键创建的索引,叶子节点上存放的直接就是数据
非聚簇索引:非主键创建的索引,叶子节点上存的是主键+索引列,查询的时候先取得主键,然后通过主键去查,所以也称为二级索引,而拿到主键回查这个动作叫做回表
而如果查询的列恰好是非聚簇索引的列,那么就不需要回表操作了,因为回表还需要操作一次,效率肯定是比不上不回表的,而该非聚簇索引也被称为覆盖索引
-
join联表查询不要太多
这里面的不要太多,究竟如何定义,阿里巴巴Java开发手册(泰山版)是这么描述的

而从另外一篇博客上面,MySql建议join联表查询最大不要超过7
我个人的理解就是,join联表个数太多肯定是会影响效率的,如果真的有业务需要如此操作,不妨先考察一下是不是业务设计上出现了问题,然后再优化联表查询,实在是需要的,也要像阿里巴巴开发手册说的,做好索引,测试好SQL的性能
-
联表查询要关注表之间的字符集是否一致
字符集不一致的,join的时候索引会失效,之前就发现过开发环境跟生产环境不一致的情况,这个真的得review好
-
如果有需要到一批数据的插入或者更新,请使用批量操作,不要一条一条的操作
最后,欢迎关注微信公众号【码农Amg】,更多精彩干货尽在于此,独乐乐不如众乐乐(多人~学习😄)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步