
Linux常用命令总结
总结一下日常开发中常用的Linux命令
忘记命令怎么使用了可以使用man指令来,例如 man ps ;man grep;
基础使用
1、进入目录 命令 --> cd /xxx
# 例子
cd /home/user 进入到home/user目录
2、查看自己所在路径 --> pwd
# 例子 我们在/home/user下执行pwd命令
pwd
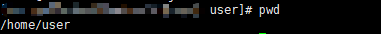
3、我想看看这个文件的内容
直接查看文件内容(cat)
# cat命令
分段查看文件内容(more)
# more命令

敲回车或者空格,可以继续查看往下的内容,按q可以直接退出

从尾部查看文件内容(tail)
# tail命令,默认打印末尾10行
-
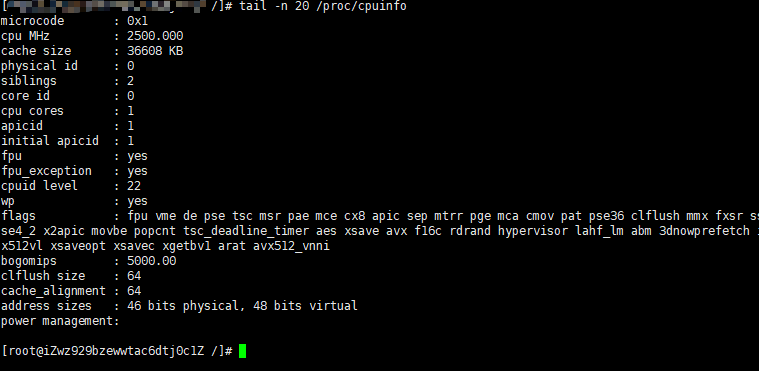
打印末尾指定行数,加上参数-n(假设打印20行)
# tail -n 20 /proc/cpuinfo
-
追加打印,加上参数-f(相当于一直”观察着“日志,当有新的内容写入到文件里面,就会打印出来,例如打debug日志等)
# tail -f /debug.log # 使用ctrl+c的方式退出 -
更多的参数,请查阅man tail
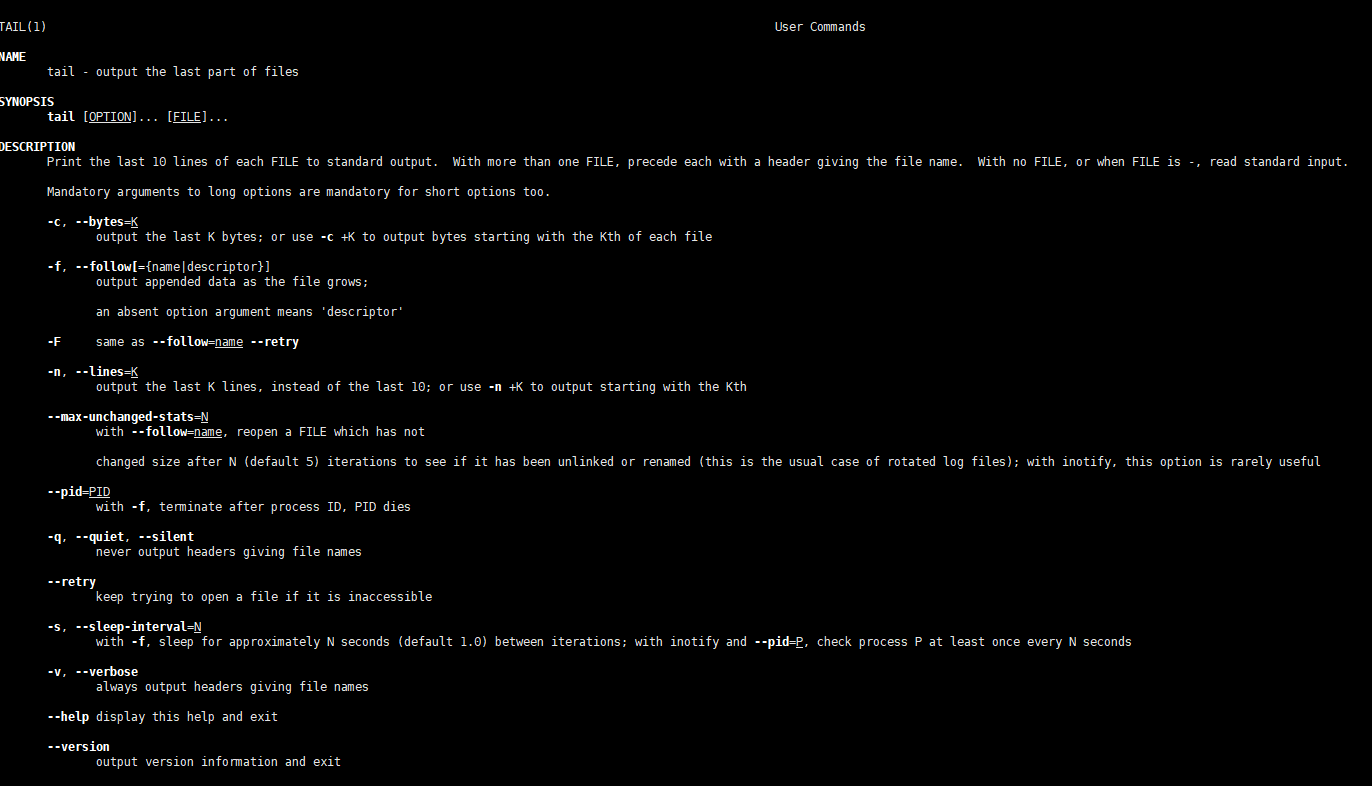
从头开始查看文件内容(head)
# head命令,默认打印文件头前10行
# 例如 head /proc/cpuinfo
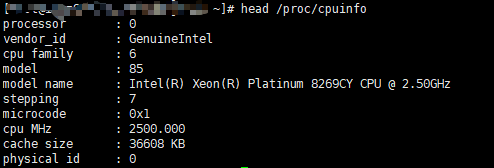
-
打印指定行数,同样是使用-n参数
# head -n 20 /proc/cpuinfo
- 更多的参数用法,还是使用man指令
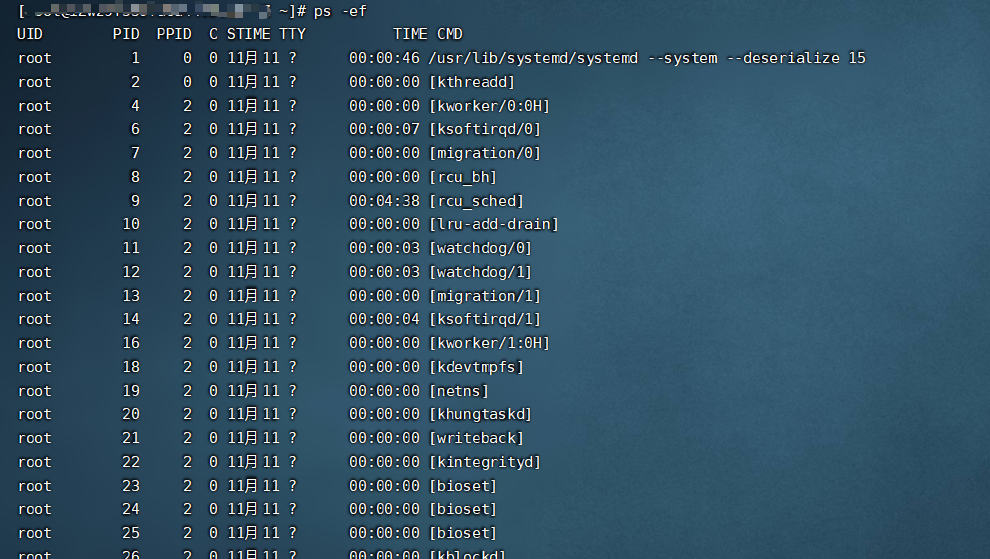
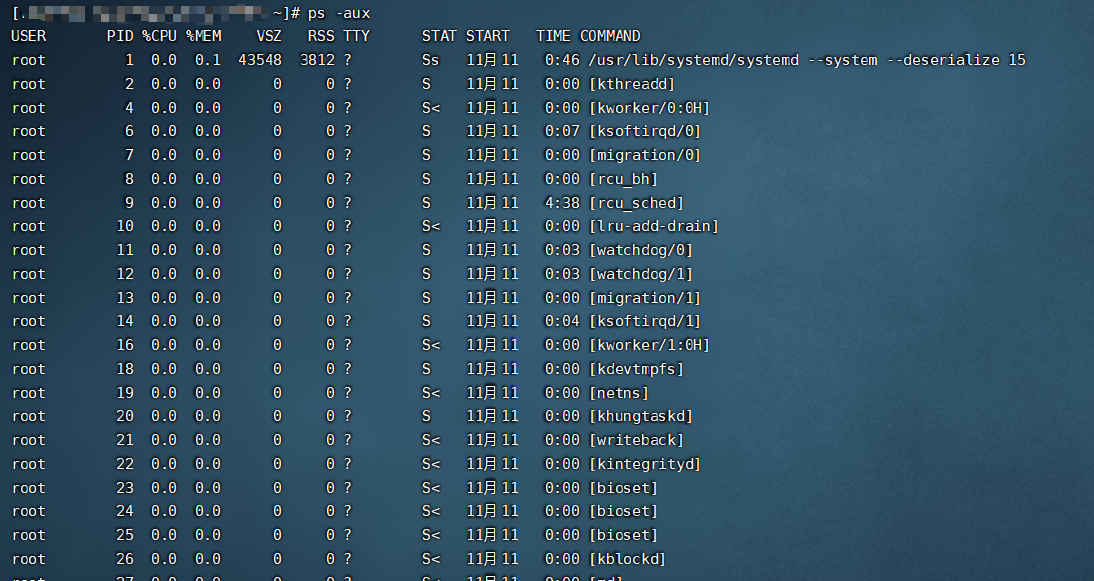
4、查看进程快照信息(ps)
# ps -ef 或者 ps aux
# ps -ef 代表使用标准形式打印所有的进程信息
# ps -aux 代表使用BSD形式打印所有的进程信息
- ps -ef
- ps -aux
-
配合
grep做筛选,我的环境上面有docker,那我只想得到docker的进程信息# ps -ef | grep docker

5、查看当前目录下的内容(ls)
# ls

-
加上参数a,把所有的内容都显示出来,包括隐藏的
# 假设我创建一个文件,以.开头,此时通过ls是看不到的,因为.开头的文件是隐藏文件 # touch .yincang

# ls -a
# 把隐藏的文件也给显示出来了

6、创建文件夹(mkdir)、删除文件夹(rmdir)
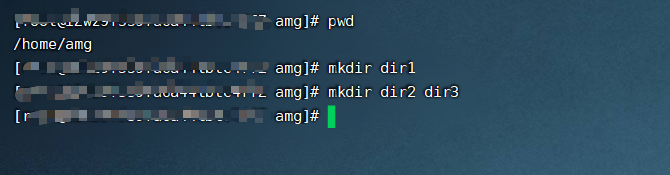
首先我们先进入到/home/amg目录下
-
在该目录下创建dir1、dir2、dir3 三个文件夹,其中dir1单独创建,dir2、dir3组合创建
# mkdir dir1 # mkdir dir2 dir3
-
加上-p参数,递归创建,意思就是,创建的父级文件夹不存在就会先把父级文件夹创建出来,再创建子文件夹
# mkdir -p dir4/subdir1

我们回到/home/amg目录下
-
现在把刚刚创建的dir1、dir2、dir3文件夹删除,这里演示两种方法
-
使用rmdir
# rmdir dir1
-

-
用rm -rf
# rm -rf dir2 dir3

-
现在dir4这个文件夹里面是有内容的,🤔思考一下,我们使用就使用rmdir能否删除掉,使用rm -rf呢?
# rmdir dir4

好吧,我可以提前告诉你 rm -rf是肯定可以的,因为rm本来就是移除文件或者文件夹的
- -r属性代表的是递归删除目录及其内容
- -f属性代表的是force,忽略不存在的文件和参数,强制删除且不提示
如果我要使用 rmdir命令删除不为空的文件夹怎么办?
-
其实也是加上一个参数 -p,其实这里是先删除dir4里面的subdir1,subdir1为空,可以删除成功,而把subdir1删除了之后,dir4自然也为空,那么顺带就把dir4也给删除了
# rmdir -p dir4/subdir1/

- 如果subdir1不为空,就不能使用这种方法了,还是使用rm吧,绝对可以,一键删除yyds
7、创建一个文件(touch、vi/vim)
-
touch命令
本质上touch命令并不是为了创建文件所用的,如果使用man指令去查看,会发现它的概述是change file timestamps,改变文件更新时间,如果文件没有创建出来,我们是可以使用touch的形式创建的,而再次touch这个文件名,会更改他的更新时间
# touch 文件名 # 例如 touch file1

-
vi/vim
使用vi/vim就是编辑一个文件,然后使用wq组合保存,如果编辑的文件是不存在的,就相当于是创建了

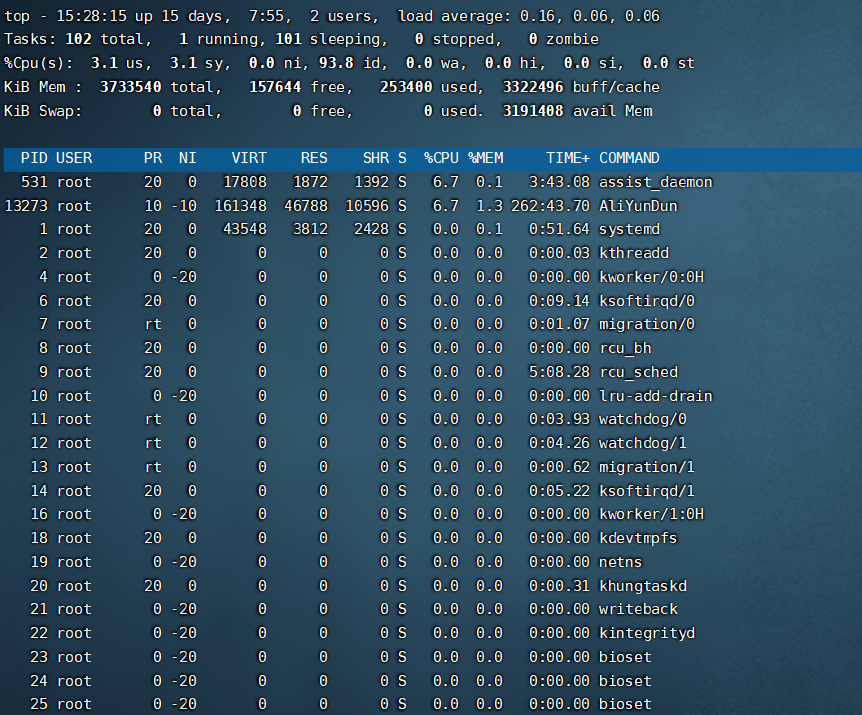
8、实时查看Linux进程信息(top)
# top
实时查看Linux里面的进程信息, 对这些参数做一个简单的解释
-
首先第一行从左到右依次是
- 当前时间
- 系统已经运行的时间
- 当前登录的用户数量
- 相应最近5、10、15分钟的平均负载情况
-
第二行是任务(进程)运行状态,从我测试的云服务器上看,一共有102个任务
-
第三行是CPU使用情况(每秒钟),从左到右依次是
- user使用cpu占比
- system使用进cpu占比
- niced运行已调整优先级的用户使用cpu占比
- 空闲cpu占比
- wait用于等待I/O完成的cpu占比
- 处理软件中断的cpu使用占比
- 用于有虚拟cpu的情况,指示被虚拟机偷掉的cpu占比
-
接下来两行是内存使用情况信息(第四行的物理内存,第五行是虚拟交换内存)
- 从左到右依次代表,单位是kb
- 总内存量
- 空闲内存量
- 已使用内存量
- 缓冲内存量
- 从左到右依次代表,单位是kb
-
接下来就是实时进程信息,第一行相当于是标题头,其描述作用,我们也来看看各个标签的意思
- PID :进程ID,进程的唯一标识符
- USER:进程所有者的实际用户名
- PR:进程的调度优先级,有的值为rt,代表的是这些进程运行在实时态
- NI:进程的NICE值,越小的值优先级越高,所以负值肯定是要比正值优先级要高
- VIRT:进程使用的虚拟内存总量,单位为kb
- RES:进程使用的物理内存总量,单位为kb
- SHR:进程使用的虚拟内存总量,单位为kb
- S:这个是进程的状态(一共有6中状态)
- D:不可中断的休眠
- R:正在运行
- S:休眠
- T:由作业控制信息停止
- t:在跟踪期间被调试器停止
- Z:僵尸状态
- %CPU:自从上次更新时到现在任务所使用的CPU时间百分比
- %MEM:进程使用的可用物理内存百分比
- TIME+:进程启动后到现在所使用的全部CPU时间
- COMMAND:进程所使用的命令
-
按照cpu使用百分比降序展示进程信息
# top模式下,同时按shift + p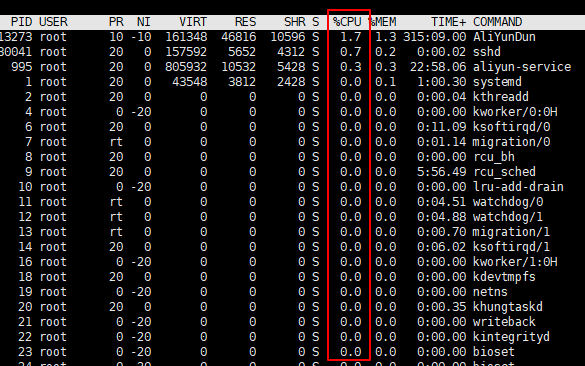
-
按照内存使用率降序展示进程信息
# top模式下,同时按shift + m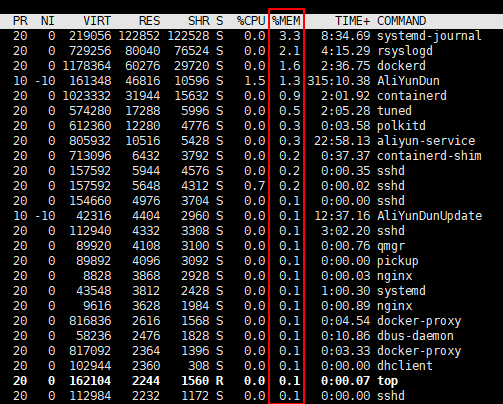
-
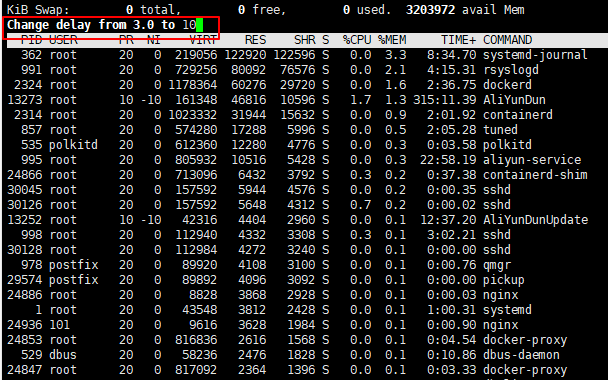
默认是三秒刷新一次进程信息,也可以手动设置刷新时间
# top模式下,按d,即可看到如下红框,填写你想要刷新的频率即可,假设我想10秒刷新一次信息
9、查看文件大小(ll、du)
-
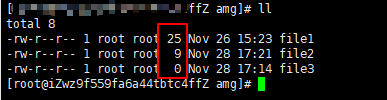
可以使用
ll指令,ll就是ls -l指令的缩写,红框处显示的就是文件的实际大小,单位为字节# ll
-
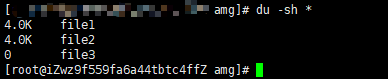
也可以使用
du指令,但是需要注意,du查看的不是文件的大小,而是显示所有文件所占用的【块】的大小,而Linux默认的系统分区的block size 最少为4k,所以即使文件只有1个字节,但是也会占用4k的块大小# du -h * # 列出当前目录下每个文件的占用的块大小,其中h参数代表的用人类更加容易看懂的方式打印,单位为k,m,g
10、查找文件所在目录(locate、find)
-
locate指令需要安装,一共就两步
- yum install mlocate
- updatedb
使用起来也很方便
# locate xxx # /xxx你要查找的文件

-
find指令则不需要安装,使用起来也很简单,配合
grep指令使用# find / | grep xxx

11、统计文件有多少行(wc 、cat)
-
有的时候需要统计文本里面有多少行,可以借助
wc指令完成# wc -l xxx # 其中xxx就是参看的文件,例如 wc -l /proc/cpuinfo

-
也可以使用
cat命令,加上-n参数# cat -n xxx # -n代表输出内容的时候带上行号,这不过这种方式就会把内容给打印出来

进阶使用
上述的都是些简单的操作,不过使用频率相对是比较高的,遇到不会用的就man一下或者--help参看帮助,配合着网上的教程,还是还容易上手的;下面以一个例子来展示一下,指令组合使用的威力
统计nginx配置文件中访问次数最多的10个ip
awk '{print $1}' /var/log/nginx/access.log | sort | uniq -c | sort -nr -k1 | head -n 10
本质上也是多个命令组合在一起使用,达成这个效果,我们来分析一下
-
awk指令,这个就牛逼了,是一个强大的文本分析工具,网上资料很多,这里就不展开说了;本例子简单解释一下就是从access.log日志中取第一个参数($1),因为日志中第一个参数就是我们需要的ip信息
-
sort从字面上就知道了是排序操作
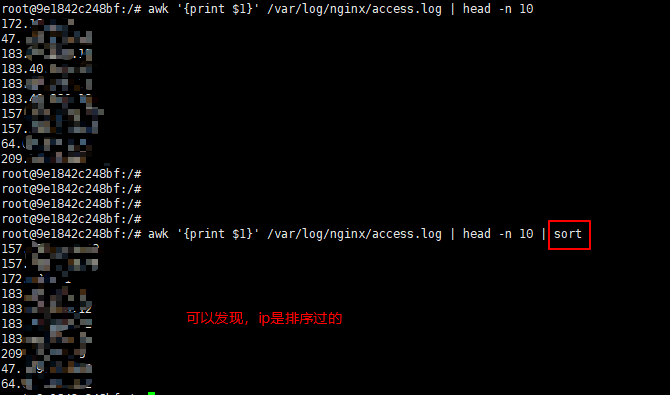
-
uniq -c从字面上的意思就是去重,uniq嘛,唯一,加上
-c参数之后,就会统计行数,也就是说,这里就是去重+统计重复行数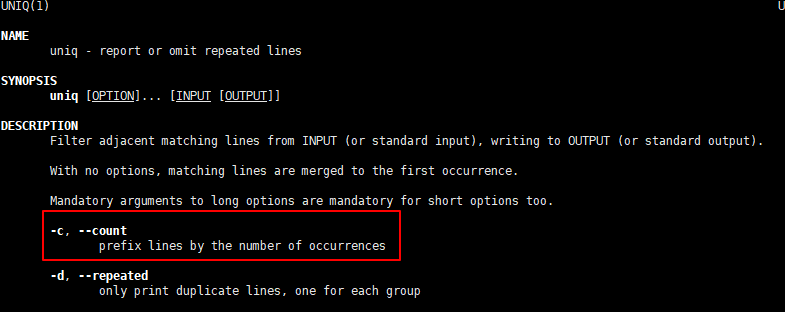
-
sort -nr -k1代表按照重复行出现的次序倒序排列,-k1代表是以第一列为标准排序,因为经过上面uniq -c之后,输出的结果是这样子的


-
head -n 10就是之前讲过的,取前10行
所以组合起来就能完成这个操作了
限于本人水平有限,难免会有些纰漏,如果有发现文章那里写的不对的,欢迎指出,谢谢!

