
【实战】利用多线程优化查询百万级数据
前言
日常开发中,难免会遇到需要查询到数据库所有记录的业务场景,在索引完善的情况下,当数据量达到百万级别或者以上的时候,全表查询就需要耗费不少的时间,这时候我们可以从以下几个方向着手优化
优化sql
利用多线程查询
分库分表
今天就来讨论一下使用【优化sql】和【多线程】方式提升全表查询效率
⚠️注意,这只是简单测试,用于讲解思路,真实情况会更加的复杂,效率可能会相对受到影响,而且也会受硬件配置的影响,所以不是绝对的
前置准备
-
使用InnoDb作为执行引擎
-
创建测试表,有自增主键id
-
往表中添加测试数据(100W以上),可以选择在程序中导入,也可以选择在数据库里面生成测试数据,具体可以参考:生成测试数据
-
Java程序中使用Mybatis来操作,使用自定义注解+SpringAOP的方式来记录执行耗时,源码后面会给,有兴趣的朋友可以下载下来实践一下
-
总体目录结构
开始测试
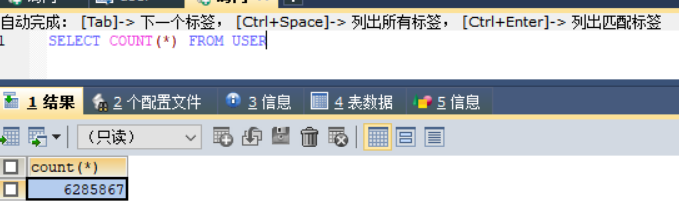
首先确保库中是有数据的,由于实际业务的复杂度,所以这里模拟username的时候也让他复杂一点,不是同一条数据进行了600多万次复制
单线程+基础sql
再下来就是基础的全表查询方式,这里使用postman测试
@GetMapping("/sync")
public String getData() {
List<User> list = userService.queryAllUseSync();
return "查询成功!";
}
@Override
@RecordMethodSpendAnnotation //这个注解标记的方法会被SpringAOP管理起来,计算方法耗时
public List<User> queryAllUseSync() {
//直接就采用Mybatis全查
return userMapper.queryAll();
}
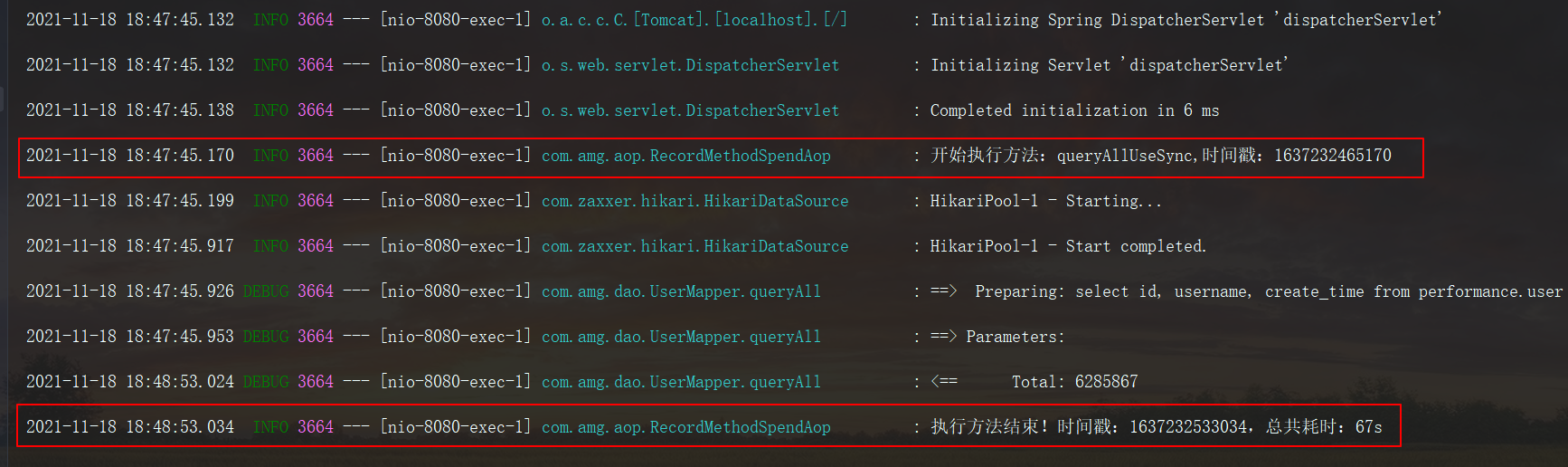
我们来看一下,这个queryAll的sql,可以发现就是一个简单的全表查询
<select id="queryAll" resultMap="UserMap">
select
id, username, create_time
from performance.user
</select>
原因分析
我们直接把sql抓出来EXPLAIN一下,可以发现是没有走索引的,全表600多W的数据,本机耗时(多次测试取平均):67s
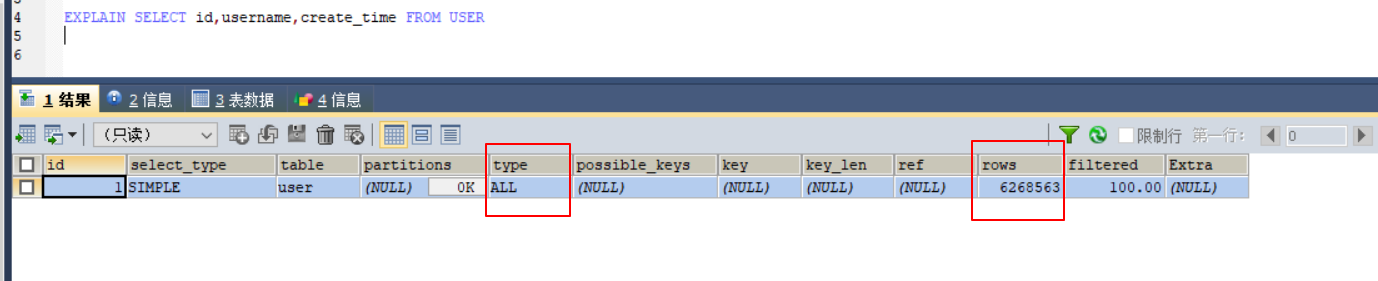
🤔这是耗时着实是太慢了,所以必须得优化一下,那么怎么优化呢?
- 从sql出发,刚刚得sql是没有走索引的,那么首先我们得让sql走索引,id是个自增主键,我们是否可以利用主键进行分段查询
单线程循环+分段sql
我们优化后的sql,其中 ?代表的是分段的起始指 n代表的是分段的末尾,可以看到是有走索引的
select id,username,create_time from user where id > ? and limit n

@Override
@RecordMethodSpendAnnotation
public List<User> queryAllUseSyncAndLimit(int limit) {
List<User> list = new ArrayList<>();
Long count = userMapper.getCount();
//循环次数
long cycles = count / limit;
for (int i = 0; i < cycles; i++) {
long startIdx = i * limit;
long endIdx = (i+1) * limit;
if (endIdx > count)
endIdx = count;
list.addAll(userMapper.queryAllByLimit(startIdx,Math.toIntExact(endIdx)));
}
return list;
}
🤔这个比刚刚那个还要慢太多了!!!,但是但从sql来看,确实是优化过了,那么为什么会慢这么多?而且CPU内存使用率飙升了起来

原因分析
我们使用jconsole看一下,可以发现内存占用量有点离谱,
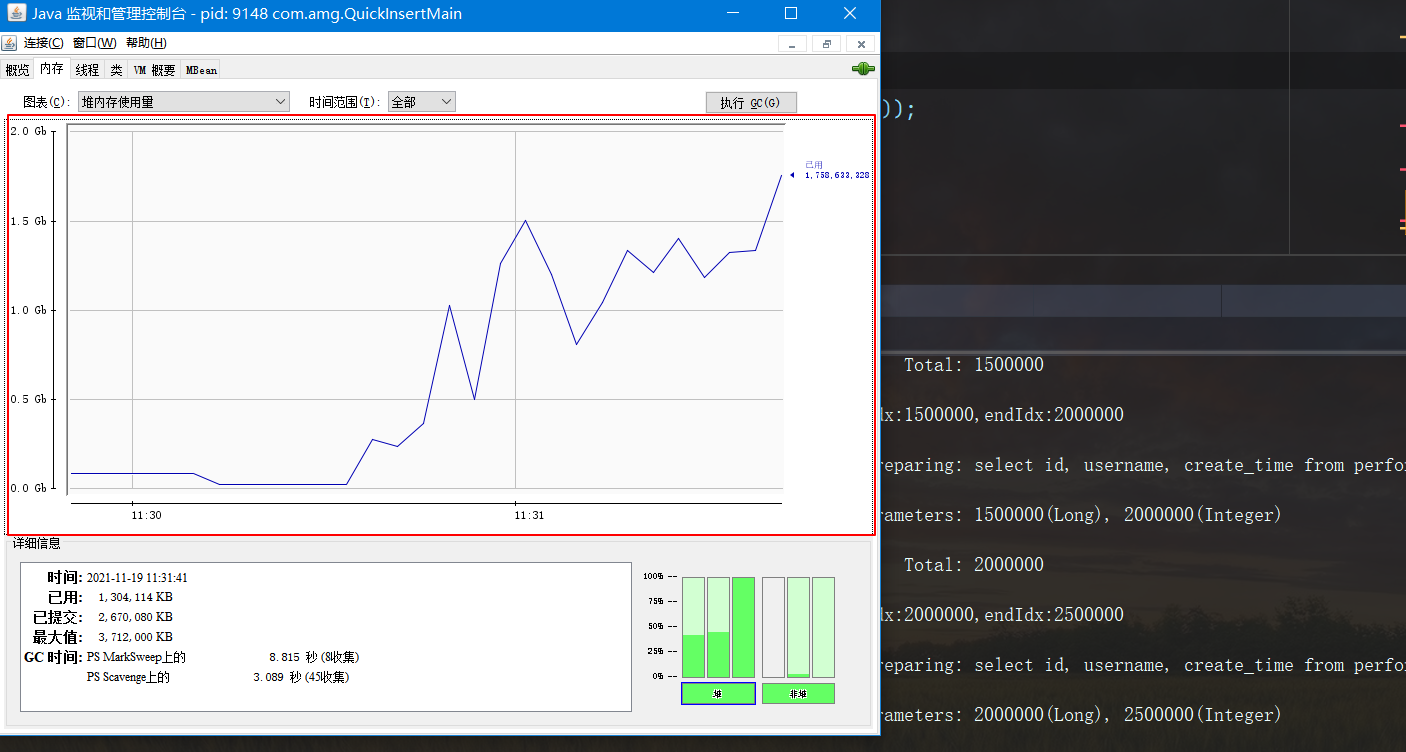
然后再使用jstat -gcutil pid(截取一段时间的)


可以发现垃圾收集非常的频繁,YGC达到45次,FGC达到8次,光gc耗时就达到18秒了,我的电脑是扛不住了,所以我就不继续跑下去了
那么这种方式的问题就不在于sql了,而是程序的问题,私以为采用分页+循环的方式,会提高效率,但是循环是需要耗费CPU资源的,由于请求的对象太大了,内存被积压满,所以程序就得等待有一块合适大小的内存出现,才能进行下去
原本sql拎出来查速度是有提升的,但是现在程序必须得停下来等待内存释放,所以CPU也会飙升,最终导致运行不下去
❌所以这种方式不可取
既然是使用分段查询+组合的形式,那我们也可以采用多线程异步的形式,每个线程跑完数据拿出来之后就remove掉
多线程+分段sql
采用线程池的思想,核心线程设置在5个,最大线程设置在10个,关于线程数的选定网上有很多资料可以查到,这里就不赘述了
这里同时采用Future异步模式,提升效率,关于Future的认识,可以看这篇文章 Java Future模式的使用
@Override
@RecordMethodSpendAnnotation
public List<User> queryAllUseThreadPool(int limit) {
//还是获取到总记录数,本机是600多W测试数据
Long count = userMapper.getCount();
List<FutureTask<List<User>>> resultList = new ArrayList<>();
//分段次数
long cycles = count / limit;
for (int i = 0; i < cycles; i++) {
//每一段的起始坐标
long idx = i * limit;
log.info("idx: {}", idx);
//具体的查询任务
FutureTask<List<User>> futureTask = new FutureTask<>(() -> userMapper.queryAllByLimit(idx,limit));
//把任务丢给线程池调度执行
threadPool.execute(futureTask);
//future异步模式,把任务放进去先,先不取结果
resultList.add(futureTask);
}
List<User> result = new ArrayList<>();
while (resultList.size() > 0) {
Iterator<FutureTask<List<User>>> iterator = resultList.iterator();
while (iterator.hasNext()) {
try {
result.addAll(iterator.next().get());
//获取一个就删除一个任务
iterator.remove();
} catch (InterruptedException | ExecutionException e) {
log.error("多线程查询出现异常:{}", e.getMessage());
}
}
}
//最后一次数据可能不为整,需要额外操作
if (result.size() != count)
result.addAll(userMapper.queryAllByLimit(result.size(),Math.toIntExact(count)));
return result;
}

原因分析
对比于使用单线程+基础sql来看,效率提升了近乎300%,限于本机性能的问题,如果采用正常的性能高点的服务器,效率更好了,我们通过jstat 看一下参数
可以发现YGC次数还是执行了29次,FGC执行了5次,对于本机来说,硬件性能有限,数据量确实是有够大的,花在gc的时间足足有7秒钟,所以如果还要优化的话,这里也是一个着手点

总结
导致查询数据慢的原因有很多种,这里罗列几种供参考
- 代码问题(设计缺陷、sql优化没做好等)
- 硬件资源问题(内存、I/O、CPU等等)
- 数据量太大问题
- 网络阻塞问题
限于本人水平有限,难免会有纰漏,如果有发现文章那里写的不对的,欢迎指出,谢谢!
最后提供一下源码的获取方式,关注微信公众号【码农Amg】,回复关键字:优化sql

