

Http-01
一:Http是无状态
这次访问了服务器,关闭网页,再次访问服务器,服务器是没有意识到又是你来访问。
但是怎么保持登录状态呢?
有cookie,session, jwt(json web token);这三种让服务器有记忆能了
cookie
客户端请求服务器,如果服务器需要记录该用户状态,就使用response向客户端浏览器颁发一个Cookie。客户端浏览器会把Cookie保存起来。当浏览器再请求该网站时,浏览器把请求的网址连同该Cookie一同提交给服务器。服务器检查该Cookie,以此来辨认用户状态。服务器还可以根据需要修改Cookie的内容。


Session
客户端输入用户名和密码后,到服务器端,服务器生成一个sessionid,和一个会话结束时间等一系列参数;服务器就需要把sessionid和会话结束时间发送给浏览器,这里就用到了cookie,设置cookie里面放的是sessionid和会话结束时间;浏览器拿到cookie后进行保存;浏览器没有保存用户名和密码,而是保存的sessionid也是没有规律的字符串,这个cookie里也就只有这个sessionid最重要,如果别人拿到这个sessionid也是没有意义的,别人也不能通过sessionid来推断出用户的密码,其次服务器在发送cookie之前是会对这个含有sessionid的cookie进行签名,如果别人修改了sessionid,那么服务器是识别不了的; cookie的核心每次发送请求都会自动发送cookie到相应的服务器那里。换句话说,浏览器下次访问,下下次访问都会自动发送这个sessionid给服务器。

JWT(Json Web Token)
如果服务器依旧使用基于Cookie的Session的话,在特定时间有大量用户访问服务器的时候,服务器就会面临需要存储大量Sessionid 在服务器里,但是有多台服务器,一台服务器存储了sessionid,就会面临需要分享sessionid给其它服务器,因为可能出现这太服务器的超载,需要分配一些用户都其它服务器,其它服务器需要通过的sessionid才可以避免用户再次输入用户和密码但是服务器这种分享也不是办法,于是可以让数据库存储sessionid,但是如果数据库奔溃了,又会影响服务器获取sessionid,所以就会出现JWT;
这里的服务器只需要保存JWT的签名密文就可以了,接着把JWT发送给浏览器,可以让浏览器以Cookie或者Stroage的形式存储,假设以Cookie的形式存储下来,这样用户每次发送请求都会把这个JWT发送给服务器,这里的token只不过存储在用户那边而已。
JWT由三部分组成:header.payload.signature : header部分声明要用算法生成, payload部分是一些特定的数据,比如有效期之类的比如特定的数据,
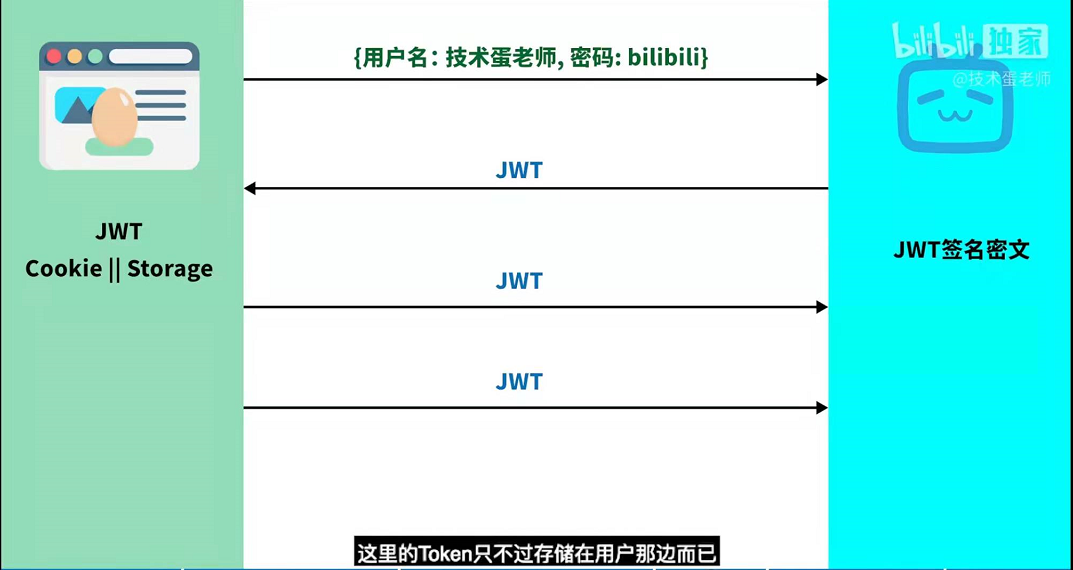
总结:Session是保存在服务器中的,而cookie是一种数据载体,把session放入cookie中送到客户端那边,cookie跟随这http的每个请求发送出去,Token是诞生在服务器,但保存在浏览器这边的;由客户端主导一切,可以放在cookie或者storage里面,持有Token就像持有令牌一样可以允许访问服务器了。
二:Http是无连接的
无连接的含义是限制每次连接只处理一个请求。服务器处理完客户的请求,并收到客户的应答后,即断开连接。采用这种方式可以节省传输时间。
解决方式:就是保持客户端与服务器的连接时间。
早期这么做的原因是 HTTP 协议产生于互联网,因此服务器需要处理同时面向全世界数十万、上百万客户端的网页访问,但每个客户端(即浏览器)与服务器之间交换数据的间歇性较大(即传输具有突发性、瞬时性),并且网页浏览的联想性、发散性导致两次传送的数据关联性很低,大部分通道实际上会很空闲、无端占用资源。因此 HTTP 的设计者有意利用这种特点将协议设计为请求时建连接、请求完释放连接,以尽快将资源释放出来服务其他客户端。
随着时间的推移,网页变得越来越复杂,里面可能嵌入了很多图片,这时候每次访问图片都需要建立一次 TCP 连接就显得很低效。后来,Keep-Alive 被提出用来解决这效率低的问题。
Keep-Alive 功能使客户端到服务器端的连接持续有效,当出现对服务器的后继请求时,Keep-Alive 功能避免了建立或者重新建立连接。市场上的大部分 Web 服务器,包括 iPlanet、IIS 和 Apache,都支持 HTTP Keep-Alive。对于提供静态内容的网站来说,这个功能通常很有用。但是,对于负担较重的网站来说,这里存在另外一个问题:虽然为客户保留打开的连接有一定的好处,但它同样影响了性能,因为在处理暂停期间,本来可以释放的资源仍旧被占用。当Web服务器和应用服务器在同一台机器上运行时,Keep-Alive 功能对资源利用的影响尤其突出。
这样一来,客户端和服务器之间的 HTTP 连接就会被保持,不会断开(超过 Keep-Alive 规定的时间,意外断电等情况除外),当客户端发送另外一个请求时,就使用这条已经建立的连接。
三:Http是媒体独立的
这意味着,只要客户端和服务器知道如何处理的数据内容,任何类型的数据都可以通过HTTP发送。客户端以及服务器指定使用适合的MIME-type内容类型。
四:Http的消息结构
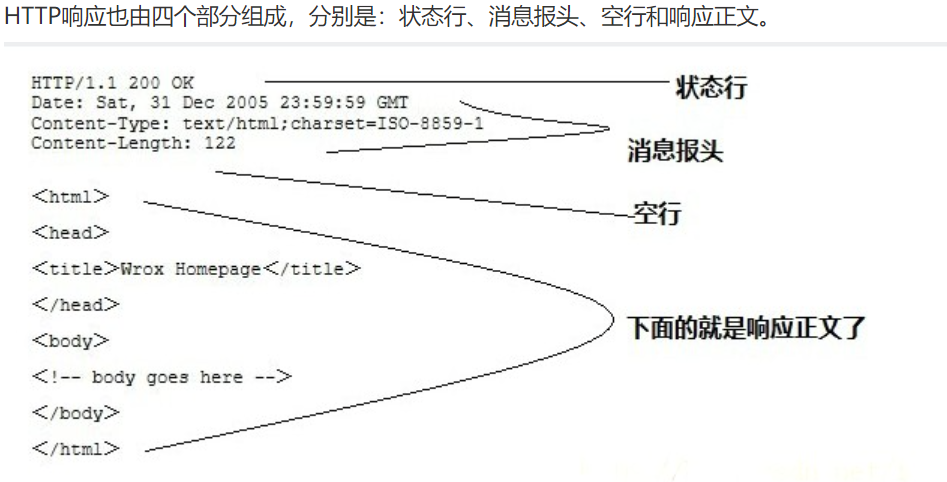
客户端发送一个HTTP请求到服务器的请求消息包括以下格式:请求行(request line)、请求头部(header)、空行和请求数据四个部分组成

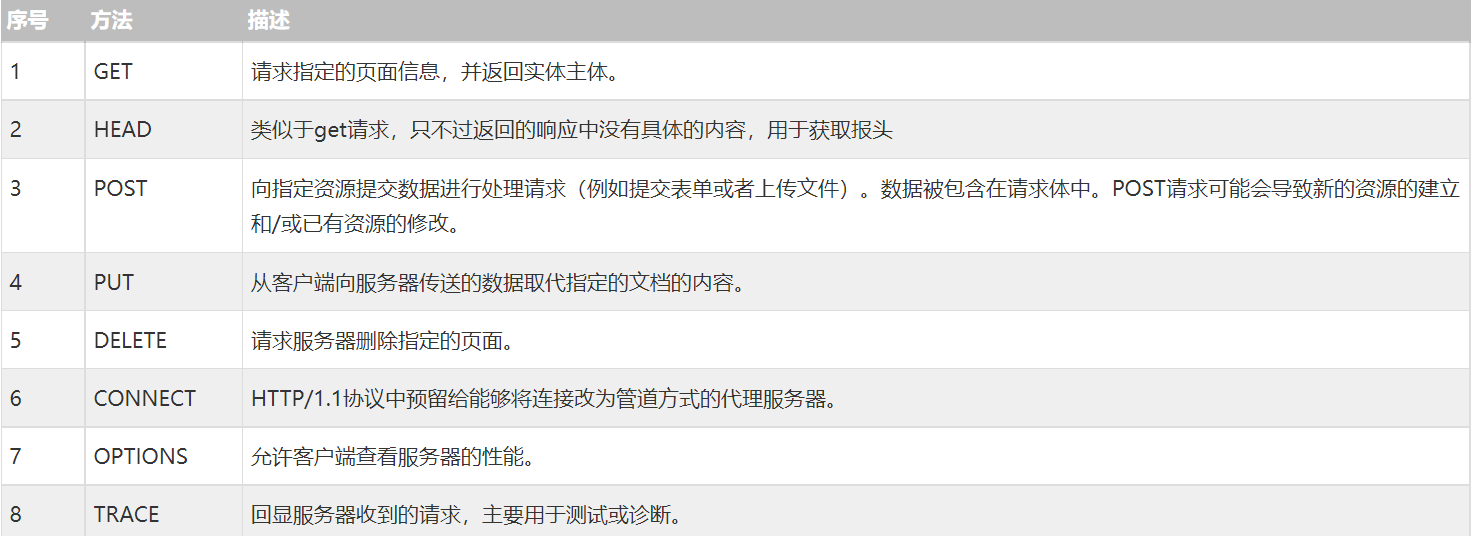
五:Http请求方法
六:Http响应头信息
①Allow:服务器支持哪些请求方法(如GET、POST等)。
②Content-Encoding:文档的编码(Encode)方法。只有在解码之后才可以得到Content-Type头指定的内容类型。利用gzip压 缩文档能够显著地减少HTML文档的下载时间。Java的GZIPOutputStream可以很方便地进行gzip压缩,但只有Unix上的 Netscape和Windows 上的IE 4、IE 5才支持它。因此,Servlet应该通过查看Accept-Encoding头(即request.getHeader("Accept- Encoding"))检查浏览器是否支持gzip,为支持gzip的浏览器返回经gzip压缩的HTML页面,为其他浏览器返回普通页面。
③Content-Length:表示内容长度。只有当浏览器使用持久HTTP连接时才需要这个数据。如果你想要利用持久连接的优势,可以把输出文档写入 ByteArrayOutputStram,完成后查看其大小,然后把该值放入Content-Length头,最后通过 byteArrayStream.writeTo(response.getOutputStream()发送内容。
④Content-Type :表示后面的文档属于什么MIME类型。Servlet默认为text/plain,但通常需要显式地指定为text/html。由于经常要设置Content-Type,因此HttpServletResponse提供了一个专用的方法setContentType。
⑤Date :当前的GMT时间。你可以用setDateHeader来设置这个头以避免转换时间格式的麻烦
⑥Expires : 应该在什么时候认为文档已经过期,从而不再缓存它?
⑦Last-Modified : 文档的最后改动时间。客户可以通过If-Modified-Since请求头提供一个日期,该请求将被视为一个条件 GET,只有改动时间迟于指定时间的文档才会返回,否则返回一个304(Not Modified)状态。Last-Modified也可用setDateHeader方法来设置
⑧Location :表示客户应当到哪里去提取文档。Location通常不是直接设置的,而是通过HttpServletResponse的sendRedirect方法,该方法同时设置状态代码为302
⑨Refresh :表示浏览器应该在多少时间之后刷新文档,以秒计。除了刷新当前文档之外,你还可以通过setHeader("Refresh", "5; URL=http://host/path")让浏览器读取指定的页面。
⑩Set-Cookie :设置和页面关联的Cookie。Servlet不应使用response.setHeader("Set-Cookie", ...),而是应使用HttpServletResponse提供的专用方法addCookie。参见下文有关Cookie设置的讨论。
七:Http状态码
下面是常见的HTTP状态码:
-
200 - 请求成功
-
301 - 资源(网页等)被永久转移到其它URL
-
404 - 请求的资源(网页等)不存在
-
500 - 内部服务器错误

八:HTTP content-type
Content-Type,内容类型,一般是指网页中存在的Content-Type,用于定义网络文件的类型和网页的编码,决定浏览器将以什么形式、什么编码读取这个文件,这就是经常看到一些Asp网页点击的结果却是下载到的一个文件或一张图片的原因。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号