

Map(1)
一:Map的概念
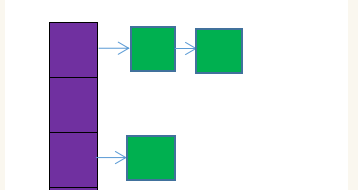
图中,紫色部分即代表哈希表,也称为哈希数组,数组的每个元素都是一个单链表的头节点,链表是用来解决冲突的,如果不同的key映射到了数组的同一位置处,就将其放入单链表中。
①:为什么要进行扩容
由于哈希是一种压缩映射,换句话说就是每一个Entry节点无法对应到一个只属于自己的桶(桶指的是数组中的位置),那么必然会存在多个Entry共用一个桶,拉成一条链表的情况,这种情况叫做哈希冲突。当哈希冲突产生严重的情况,某一个桶后面挂着的链表就会特别长,我们知道查找最怕看见的就是顺序查找,那几乎就是无脑查找。
哈希冲突无法完全避免,因此为了提高HashMap的性能,HashMap不得尽量缓解哈希冲突以缩短每个桶的外挂链表长度。
频繁产生哈希冲突最重要的原因就像是要存储的Entry太多,而桶不够,这和供不应求的矛盾类似。因此,当HashMap中的存储的Entry较多的时候,我们就要考虑增加桶的数量,这样对于后续要存储的Entry来讲,就会大大缓解哈希冲突。
因此就涉及到HashMap的扩容。
②:扩容
默认hashmap中默认的数组大小是多少,默认情况下,数组大小为16,那么当hashmap中元素个数超过16*0.75=12的时候,就把数组的大小扩展为2*16=32,即扩大一倍,然后重新计算每个元素在数组中的位置,而这是一个非常消耗性能的操作,所以如果我们已经预知hashmap中元素的个数,那么预设元素的个数能够有效的提高hashmap的性能。比如说,我们有1000个元素new HashMap(1000), 但是理论上来讲new HashMap(1024)更合适,不过上面annegu已经说过,即使是1000,hashmap也自动会将其设置为1024。 但是new HashMap(1024)还不是更合适的,因为0.75*1000 < 1000, 也就是说为了让0.75 * size > 1000, 我们必须这样new HashMap(2048)才最合适,既考虑了&的问题,也避免了resize的问题。
③:处理hash冲突
hash冲突就是根据key即经过一个函数f(key)得到的结果的作为地址去存放当前的key value键值对(这个是hashmap的存值方式),但是却发现算出来的地址上已经有人先来了。就是说这个地方被抢了啦。这就是所谓的hash冲突啦。
我们用的是链地址法:这种方法的基本思想是数组的每个元素都是一个单链表的头节点,链表是用来解决冲突的,如果不同的key映射到了数组的同一位置处,就将其放入单链表中链地址法适用于经常进行插入和删除的情况。
④:hashmap转为红黑树的俩个条件
一个是链表长度到8,一个是数组长度到64.
当 Hash 冲突严重时,在桶上形成的链表会变的越来越长,这样在查询时的效率就会越来越低;时间复杂度为 O(N)。所以在1.8的时候进行了转为红黑树。
Iterator<Map.Entry<String, Integer>> entryIterator = map.entrySet().iterator();
while (entryIterator.hasNext()) {
Map.Entry<String, Integer> next = entryIterator.next();
System.out.println("key=" + next.getKey() + " value=" + next.getValue()); }
Iterator<String> iterator = map.keySet().iterator();
while (iterator.hasNext()){
String key = iterator.next();
System.out.println("key=" + key + " value=" + map.get(key));
}
上面的俩种遍历方法,建议选用第一种,第一种我们将key和value同时取出来。第二分钟我们通过取出来key值后再进行取value。
大多数情况下,只要不涉及线程安全问题,Map基本都可以使用HashMap,但是hashmap也是无序。HashMap的这一缺点往往会带来困扰,因为有些场景,我们期待一个有序的Map。
这个时候,LinkedHashMap就闪亮登场了,它虽然增加了时间和空间上的开销,但是通过维护一个运行于所有条目的双向链表,LinkedHashMap保证了元素迭代的顺序。该迭代顺序可以是插入顺序或者是访问顺序。
特点总结:
1、LinkedHashMap的结构是数组+链表/红黑树+双向链表。双向链表是用来维护元素的顺序的。HashMap的元素是无序的,LinkedHashMap的元素是有序的。LinkedHashMap的存取数据的方式还是跟HashMap一致。
2、和HashMap的不同之处有:遍历方式不一样(扩容是用到遍历),HashMap根据按数组顺序来遍历,如果遇到链表,则依次遍历链表中的元素,完了之后继续遍历数组的元素。而LinkedHashMap是按双向列表来遍历的,所以LinkedHashMap遍历的性能比HashMap高一点,因为HashMap中有空元素。
3、LinkedHashMap中双向链表的顺序是按元素添加的顺序的,新添加的元素被加到双向链表的末尾。
4、LinkedHashMap和HashMap都是线程不安全的。
LinkedHashMap,总的来说,LinkedHashMap底层是使用HashMap+LinkedList实现的。用HashMap维护数据,用LinkedList来维护数据插入的顺序。
LinkedHashMap操作数据结构(比如put一个数据),和HashMap操作数据的方法完全一样,无非就是细节上有一些的不同罢了。
四:TreeMap
TreeMap 是一个有序的key-value集合,它是通过红黑树实现的。红黑树规则特点:
- 节点分为红色或者黑色;
- 根节点必为黑色;
- 叶子节点都为黑色,且为null;
- 连接红色节点的两个子节点都为黑色(红黑树不会出现相邻的红色节点);
- 从任意节点出发,到其每个叶子节点的路径中包含相同数量的黑色节点;
- 新加入到红黑树的节点为红色节点;
我们的TreeMap是可以自动排序的,而 TreeMap中所有的元素都保持着某种固定的顺序,如果你需要得到一个有序的结果你就应该使用TreeMap(HashMap中元素的排列顺序是不固定的)。HashMap 非线程安全 TreeMap 非线程安全 LinkedHashMap非线程安全
- HashMap无序,TreeMap固定的顺序,LinkedHashMap有序的(可以是插入顺序,也可访问顺序)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号