

【稳定性】【健壮性】【监控】紧急预案,限流,降级,熔断
稳定性:
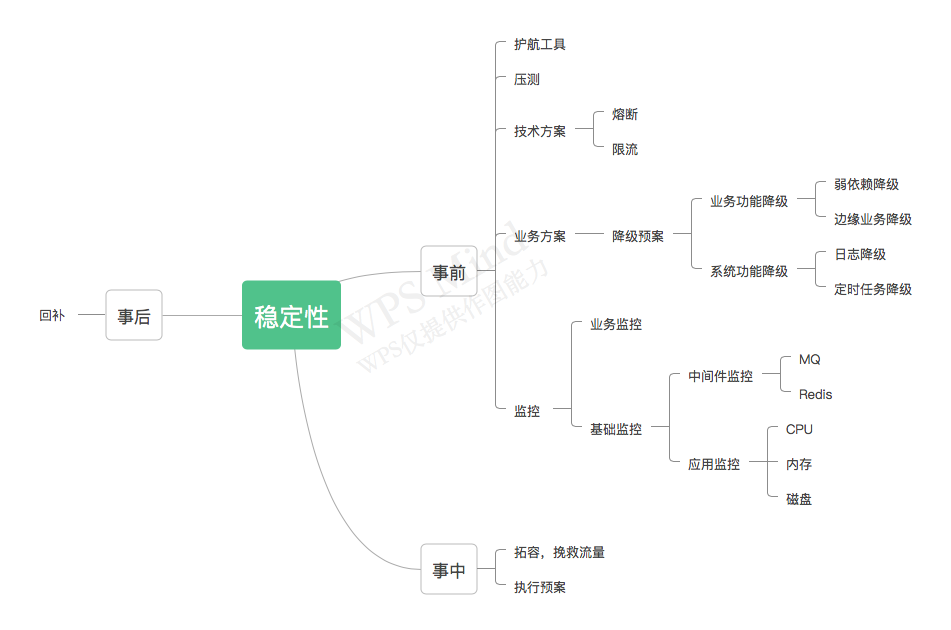
以下属于稳定性考虑的事情:
为什么需要各个维度的指标呢?
因为其实问题出现的话,肯定是有连锁反应的,我们也有根据发现的表象立即分析出问题的根因,并且需要评估其影响,做最合理的应对方案。
事前:
掌控:必须要有对代码的掌控、对技术栈的深入了解,特别对于复杂的业务,在垃圾堆里面找bug或许需要很长时间。好的代码可以快速让你定位问题和想出解决方案
例子:数据库索引自动选择,导致数据库索引走错,业务抖动
护航工具:有一定的护航工具,对业务核心流程和状态有必要的控制权,是系统具有容错性的重要保障。
演练:压测。
限流降级:减少流量进入,是快速恢复的方案之一
- 业务降级:减少某类服务
- 系统降级:减少日志打印、定时任务
监控:最重要的一part;
- 不要成为监控疲劳,要精准
事中:
- 止血(降级、限流)
- 快恢
- 未知:资源问题:磁盘满了、删日志问题
- 拓容,加主机
- 已知:工程问题:回滚、紧急上线
事后:
- 恢复数据
- 复盘
应用维度:
业务单量
- 履约单量、物流订单量、作业单量(按类型分);
- 单据状态分布
- 履约完成率(月、日)
机器指标:
- 服务器RT(响应时长)
- 服务器Load:
- JVM FULL GC监控
业务监控:
- 数据库数据监控
- 日志数据监控(接口报错,消费异常)
数据库指标:
- 磁盘宽带、CPU、内存使用监控;
- 慢SQL监控;
MQ指标:
死信队列
HSF指标:
QPS\TPS
Sentinel:限流中间件
主机指标:
磁盘满:定位大文件:du -sh /home/admin/* |grep G
--------------------------------
优秀、是一种习惯
、、、、、、、、、、、、、、、


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具