
【分布式ID】雪花、TDDL-SEQUENCE、UUID
分布式ID
要保证id不重复,主要从三方面考虑,时间维度、空间维度、原子维度;
时间维度:时间维度不重复,例如今天和明天不能重复,所以时间是可以加入id的一种因子;
空间维度:不同的机器,不同的环境生成的id不同,所以mac地址,机房地址等,都可以作为空间维度的区分;
原子维度:主要是线程的安全性,也就是递增的保证,我们一般称之为 序列 ,例如数据库的自增id,就仅仅是原子维度;
讨论完分布式id后,我们讨论一下非功能性的一些要求:
高可用:可以随时提供服务,不间断;
低延迟:id获取速度要快;
高并发:支持高QPS;
雪花算法
雪花算法生成的ID是一个64 bit的long型的数字且按时间趋势递增。大致由首位无效符(0,1bit)、时间戳差值(41bit)、机器编码(10bit),序列号四部分组成(12bit)。
- 雪花算法是可以保证一定程度上的递增
- 雪花算法基于高并发下,时间的最小精度可以生产最多的序列号个数决定了不重复率
UUID
- 基本自带实现,同样考虑:时间、空间、序列号维度,有多个实现版本。
- 无序,长度太大,对数据库不友好。
TDDL
分布式序列:阿里内部的较多用法,主要是解决一个序列原子性的问题,首先它的序列是维护在数据中的,用一张表表示,每次获取一定个数(如10000)的序列到进程中使用。
为了保证高可用,和高并发,维护序列的必然不能只是一张表,所以可以搞n张表,每一个数据库表,维护一个sequence,所以就有了单个步长和组步长的说法。
序列的获取如下所示:
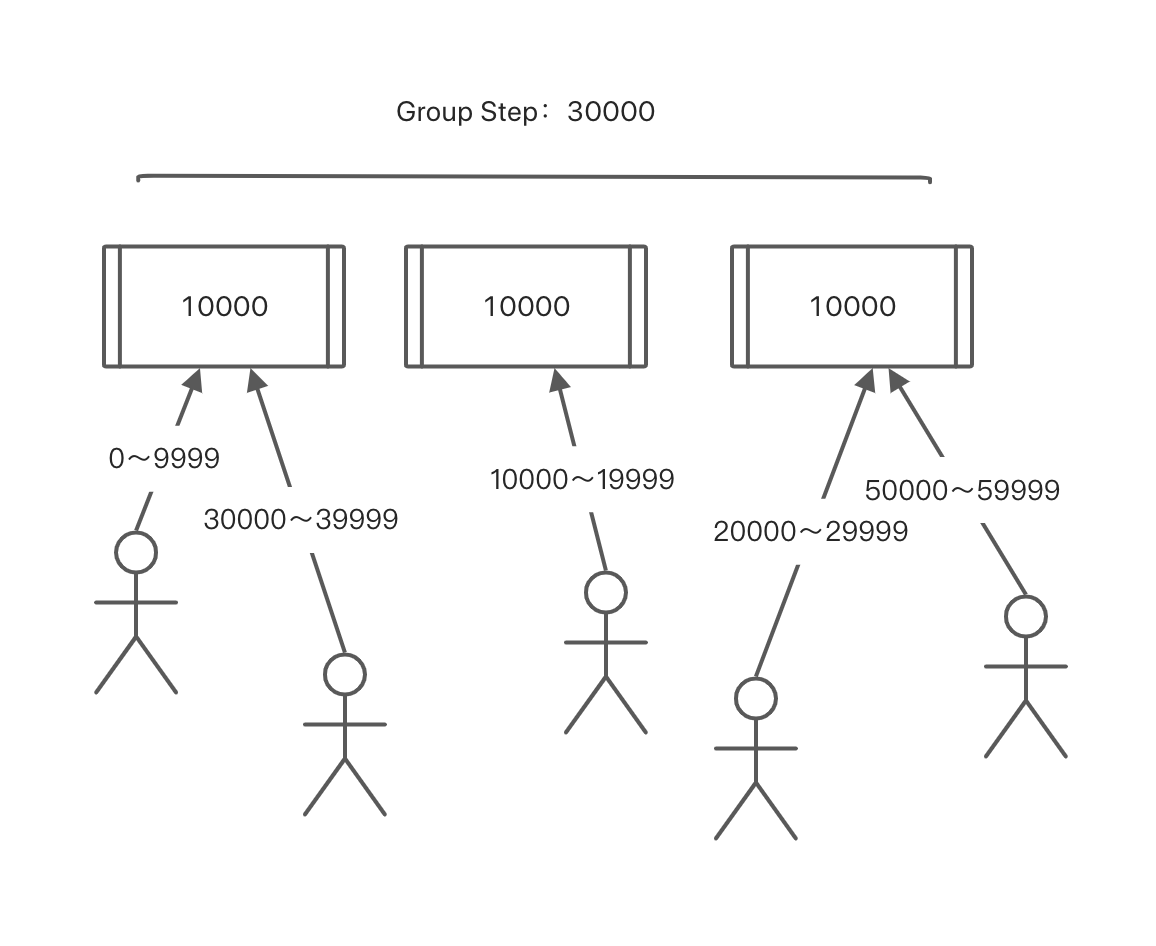
时间维度:既然用了序列,因为序列的位数是有限的,那么必然就会重复,所以同样的,在同一个时刻内,一个序列不能做了一次重复,但一般如果时间精确到某一个维度,现实的重复可能性基本为0。但不管如何,时间维度是必须要加的
- 递增,做数据库主键比较合适
- 高可用,不会单机崩溃出现问题
- 由于获取sequence是一次性获取多个在进场内部使用的,所以很有可能会造成空洞问题
纯序列
Redis:集群高可用,但是部署复杂,维护难;可读性好,容易记住,存储占有空间少。
SQL自增:实现简单,但是性能不高;可读性好,容易记住,存储占有空间少。
--------------------------------
优秀、是一种习惯
、、、、、、、、、、、、、、、

