C语言基础之ASCII编码(3)
什么是字符集和字符编码?
前面我们已经讲到,计算机是以二进制的形式来存储数据的,它只认识 0 和 1 两个数字,我们在屏幕上看到的文 字,在存储之前都被转换成了二进制(0和 1 序列),在显示时也要根据二进制找到对应的字符。
可想而知,特定的文字必然对应着固定的二进制,否则在转换时将发生混乱。那么,怎样将文字与二进制对应起来 呢?这就需要有一套规范,计算机公司和软件开发者都必须遵守,这样的一套规范就称为字符集(Character Set) 或者字符编码(Character Encoding)。
严格来说,字符集和字符编码不是一个概念,字符集定义了文字和二进制的对应关系,为字符分配了唯一的编号, 而字符编码规定了如何将文字的编号存储到计算机中。我们暂时先不讨论这些细节,姑且认为它们是一个概念,本节中我也混用了这两个概念,未做区分。
字符集的功能:字符集定义了文字和二进制的对应关系,为字符分配唯一的编号
字符编码的功能:字符编码规定了如何将文字的编号存储到计算机中
可以将字符集理解成一个很大的表格,它列出了所有字符和二进制的对应关系,计算机显示文字或者存储文字,就 是一个查表的过程。
在计算机逐步发展的过程中,先后出现了几十种甚至上百种字符集,有些还在使用,有些已经淹没在了历史的长河 中,本节我们要讲解的是一种专门针对英文的字符集——ASCII 编码。
ASCII码的由来
计算机是美国人发明的,他们首先要考虑的问题是,如何将二进制和英文字母(也就是拉丁文)对应起来。
当时,各个厂家或者公司都有自己的做法,编码规则并不统一,这给不同计算机之间的数据交换带来不小的麻烦。 但是相对来说,能够得到普遍认可的有 IBM 发明的 EBCDIC 和此处要谈的 ASCII。
我们先说 ASCII。ASCII 是“American Standard Code for Information Interchange”的缩写,翻译过来是“美国信息 交换标准代码”。看这个名字就知道,这套编码是美国人给自己设计的,他们并没有考虑欧洲那些扩展的拉丁字母, 也没有考虑韩语和日语,我大中华几万个汉字更是不可能被重视。
但这也无可厚非,美国人自己发明的计算机,当然要先解决自己的问题
ASCII 的标准版本于 1967 年第一次发布,最后一次更新则是在 1986 年,迄今为止共收录了 128 个字符,包含 了基本的拉丁字母(英文字母)、阿拉伯数字(也就是 1234567890)、标点符号(,.!等)、特殊符号(@#$%^&等) 以及一些具有控制功能的字符(往往不会显示出来)。
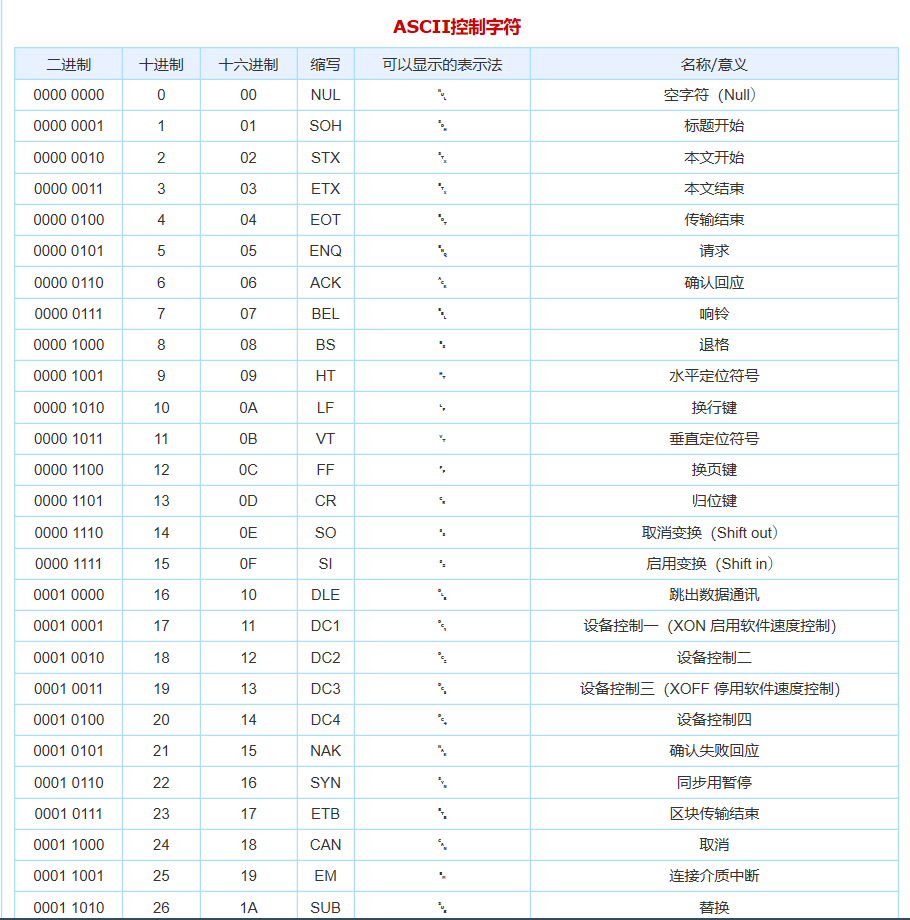
在 ASCII 编码中,大写字母、小写字母和阿拉伯数字都是连续分布的(见下表),这给程序设计带来了很大的方便。 例如要判断一个字符是否是大写字母,就可以判断该字符的 ASCII 编码值是否在 65~90 的范围内。
EBCDIC 编码正好相反,它的英文字母不是连续排列的,中间出现了多次断续,给编程带来了一些困难。现在连 IBM 自己也不使用 EBCDIC 了,转而使用更加优秀的 ASCII。
ASCII 编码已经成了计算机的通用标准,没有人再使用 EBCDIC 编码了,它已经消失在历史的长河中了。
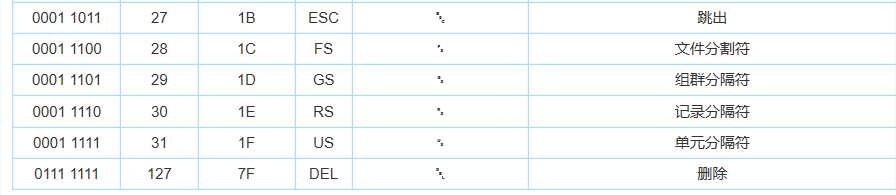
ASCII编码一览表
标准 ASCII 编码共收录了 128 个字符,其中包含了 33 个控制字符(具有某些特殊功能但是无法显示的字符)和 95 个可显示字符。



 浙公网安备 33010602011771号
浙公网安备 33010602011771号