


Hadoop 学习笔记 (九) hadoop2.2.0 生产环境部署 HDFS HA部署方法
step1:将安装包hadoop-2.2.0.tar.gz存放到某一个目录下,并解压 step2:修改解压后的目录中的文件夹/etc/hadoop下的xml配置文件(如果文件不存在,则自己创建) 包括hadoop-env.sh mapred-site.xml core-site.xml hdfs-site.xml yarn-site.xml step3:格式化并启动hdfs step4:启动yarn
注意事项:
1,主备NameNode有多种配置方法,本课程使用JournalNode方式。为此需要至少准备3个节点作为JournalNode,这三个
节点可与其他服务,比如NodeManager(slave节点上有)公用节点
2,主备两个NameNode应位于不同机器上,这两台机器不要再部署其他服务,即他们分别独享一台机器(注:HDFS2.0中无需再部署
和配置SecondaryName,备NameNode已经替代它完成了相应的功能)(那为什么单机版的中会有secondarynamenode因为单机版的hadoop2.0兼容1.0的模式,可以用)
3,主备NameNode之间有两种切换方式:手动切换和自动切换,其中,自动切换时借助zookeeper实现的,因此,需单独部署一个zookeeper
集群(通常为奇数个节点,至少3个)。本课程使用手动切换方式
接下来介绍:
1 HDFS HA部署方法
2 HDFS HA + Federation部署方法
3 Yarn部署方法
第一种:HDFS HA 部署方法
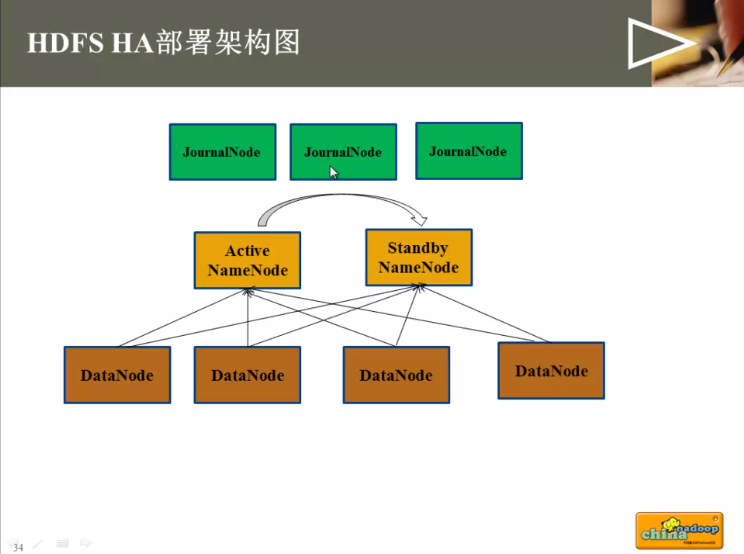
部署家构图:
journalnode需要资源很少,所以可以跟datanode共享。
dfs.namenode.name.dir : NameNode fsiamge存放目录(元数据)---------- 可配置多个,一个可能不太可靠
dfs.namenode.shared.edits.dir : 主备NameNode同步元信息的共享存储系统 -------- 三个journal node地址
dfs.journalnode.edits.dir : Journal Node 数据存放目录
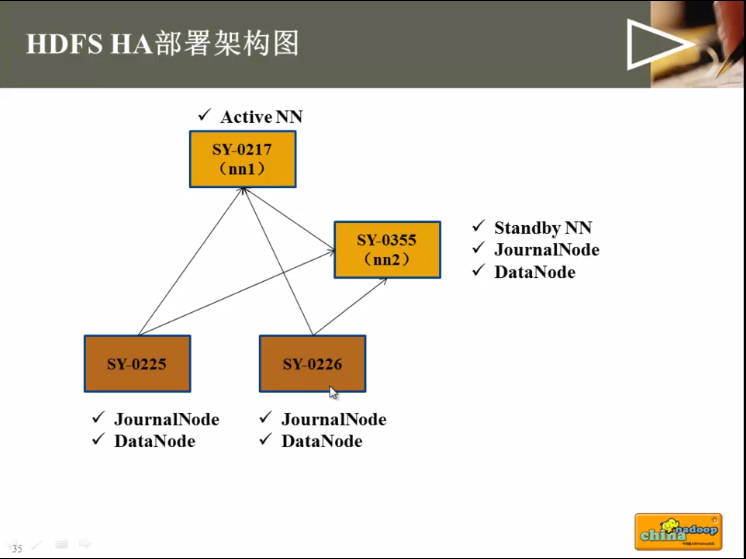
看个实际的例子:


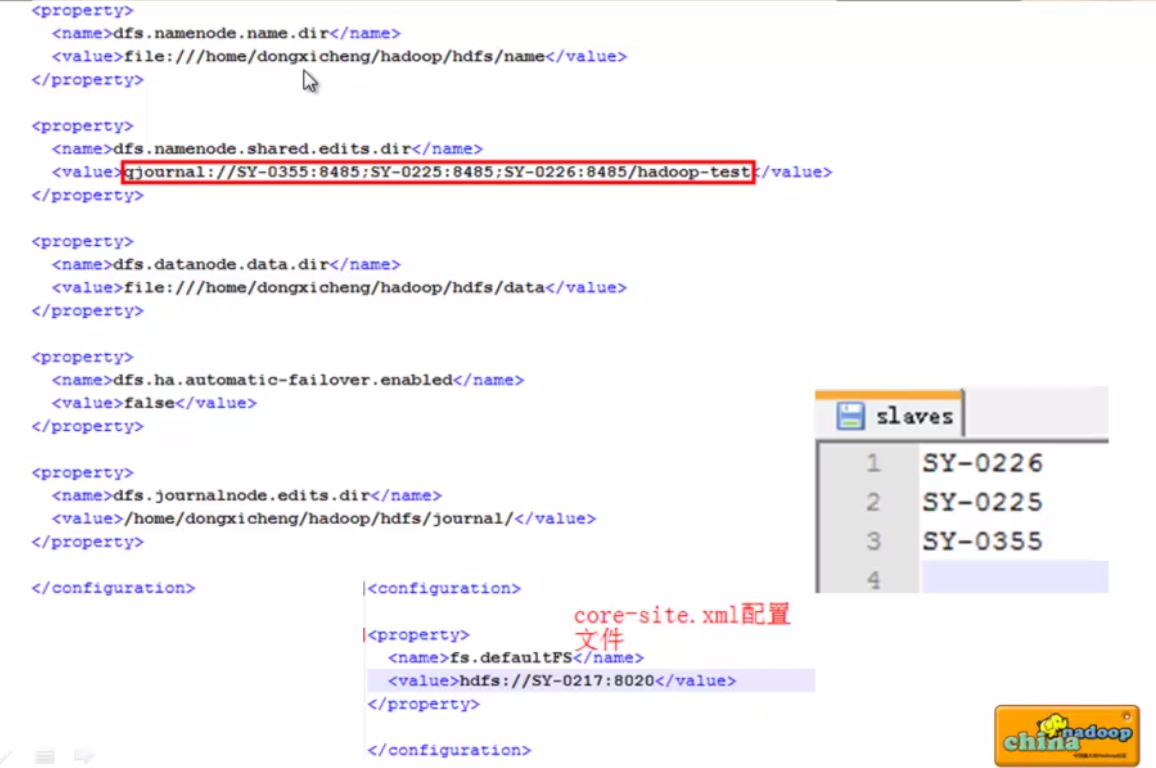
core-site.xml说明:
fs.defaultFS 如果是自动切换这里会是逻辑地址,因为如果自动切换,那这里还要改名字很麻烦,所以自动切换的时候这里会切换成逻辑地址
HDFS-HA 部署流程-启动/关闭HDFSstep1:在各个节点上,启动Journalnode服务
sbin/hadoop-daemon.sh start journal
step2:在[nn1]上,对其进行格式化,并启动
bin/hdfs namenode -format
sbin/hadoop-daemon.sh start namenode
step3:在[nn2]上,同步[nn1]的元数据信息(含格式化过程)
bin/hdfs namenode -bootstrapStandby
step4:在[nn2]上,启动NameNode:
sbin/hadoop-daemon.sh start namenode
经过以上4步,nn1和nn2均处于standby状态
step5:在[nn1]上,将NameNode切换为Active
bin/hdfs haamin -transitionToActive nn1
step6:在[nn1]上,启动所有datanode
sbin/hadoop-daemon[s].sh start datanode
关闭hadoop集群:
在nn1上:sbin/stop-dfs.sh
如何验证:50070(active)50070 standby


