Python 爬虫练习(三) 利用百度进行子域名收集
不多介绍了,千篇一律的正则匹配.....
import requests
import re
head = {'User-Agent': \
'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/43.0.2357.130 Safari/537.36'}
key = 'jcrcw.com' # 这里填主域名
lst = []
match = 'style="text-decoration:none;">(.*?)</b>'
for i in range(1, 20): # 1-19页
url = "https://www.baidu.com/s?wd=inurl:{}&pn={}&oq={}&ie=utf-8".format(key, i, key)
print(url)
# response = requests.get(url,headers=head,cookies = cook).content
response = requests.get(url, headers=head).content
subdomains = re.findall(match, response.decode())
for j in subdomains:
j = j.replace('<b>', '')
if key in j:
if j not in lst:
lst.append(j)
# print(lst)
print(lst)
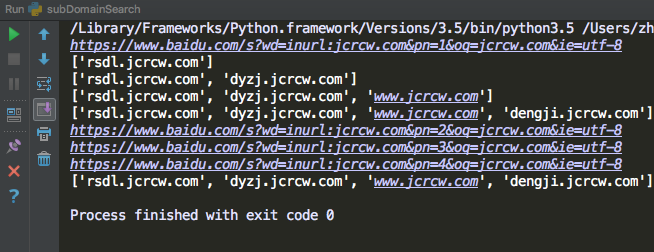
运行结果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号