
顺序栈与链式栈的图解与实现
 # 顺序栈与链式栈的图解与实现
# 顺序栈与链式栈的图解与实现
- 栈是一种特殊的线性表,它与线性表的区别体现在增删操作上
- 栈的特点是先进后出,后进先出,也就是说栈的数据操作只能发生在末端,而不允许在中间节点进行操作

- 如上图所示,对栈的增删操作都只能在末端也就是栈顶操作,
- 栈既然是线性表那么就存在表头和表尾,不过在栈结构中,对其都进行限制改造,表尾用来输入数据也叫做栈顶(
top),相应的 表头就是栈底(bottom),栈顶和栈顶是两个指针用来表示这个栈 - 与线性表类似,栈也是又顺序表示和链式表示,分别称作顺序栈和链栈
栈的基本操作
- 如何通过栈这个后进先出的线性表,来实现增删查呢?
- 初始时,栈内没有数据,即空栈。此时栈顶就是栈底。
- 当存入数据时,最先放入的数据会进入栈底。接着加入的数据都会放入到栈顶的位置。
- 如果要删除数据,也只能通过访问栈顶的数据并删除。对于栈的新增操作,通常也叫作
push或压栈。 - 对于栈的删除操作,通常也叫作
pop或出栈。对于压栈和出栈,我们分别基于顺序栈和链栈来分析
顺序栈
- 顺序栈即就是顺序存储元素的,通常顺序栈我们可以通过数组来实现,将数组的首元素放在栈底,最后一个元素放在栈顶,之后指定一个
top指针指向栈顶元素的位置 - 当栈中只有一个元素是,此时
top=0,一般以top是否为-1来判定是否为空栈,当定义了栈的最大容量时,则栈顶top必须小于最大容量值 - 下面我们通过
Java代码实现一个顺序栈,非常简单如下:
/**
* @url: i-code.online
* @author: 云栖简码
* @time: 2020/12/8 16:48
*/
public class Stack<T> {
private Object[] stack;
private int stackSize;
private int top = -1;
public Stack(int size){
stackSize = size;
stack = new Object[size];
}
public void push(T value){
if (top < stackSize-1){
top++;
stack[top] = value;
return;
}
throw new ArrayIndexOutOfBoundsException(top +"越界");
}
public T pop(){
if (top > -1){
top--;
return (T) stack[top+1];
}
throw new ArrayIndexOutOfBoundsException(top +"越界");
}
public boolean empty(){
return top == -1;
}
}
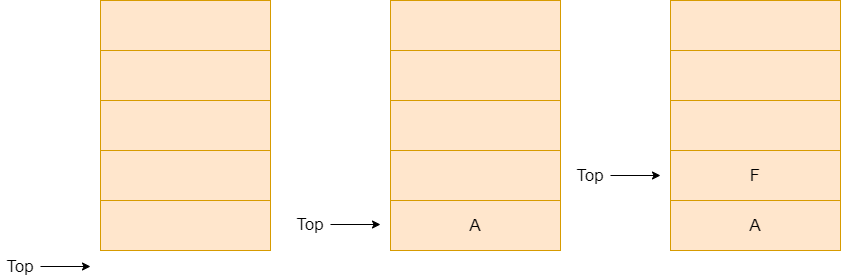
- 当需要新增数据元素,即入栈操作时,就需要将新插入元素放在栈顶,并将栈顶指针增加 1。如下图所示:
![数据结构 (1).png]()
- 删除数据元素,即出栈操作,只需要
top-1就可以了。
对于查找操作,栈没有额外的改变,跟线性表一样,它也需要遍历整个栈来完成基于某些条件的数值查找,上述代码中并未去实现该功能
链栈
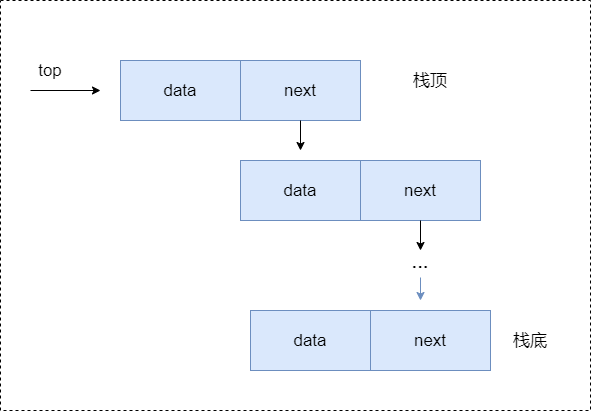
- 关于链式栈,就是用链表的方式对栈的表示。通常,可以把栈顶放在单链表的头部,如下图所示。由于链栈的后进先出,原来的头指针就显得毫无作用了。因此,对于链栈来说,是不需要头指针的。相反,它需要增加指向栈顶的
top指针,这是压栈和出栈操作的重要支持。
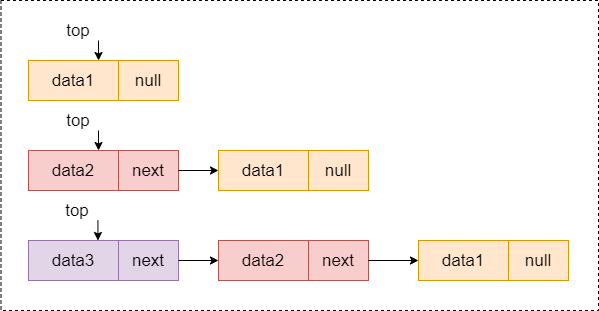
- 对于链表我们添加都是在其后追加,但是对于链栈,新增数据的压栈操作需要额外处理的,就是栈的
top指针。如下图所示,插入新的数据放在头部,则需要让新的结点指向原栈顶,即top指针指向的对象,再让top指针指向新的结点。
- 在链式栈中进行删除操作时,只能在栈顶进行操作。因此,将栈顶的
top指针指向栈顶元素的next指针即可完成删除。对于链式栈来说,新增删除数据元素没有任何循环操作,其时间复杂度均为O(1)。 - 通过代码简单实现栈的操作,如下:
/**
* @url: i-code.online
* @author: 云栖简码
* @time: 2020/12/8 20:57
*/
public class LinkedList<E> {
private Node<E> top = new Node<>(null,null);
public void push(E e){
Node<E> node = new Node<>(e,top.next);
top.next = node;
}
public E pop(){
if (top.next == null){
throw new NoSuchElementException();
}
final Node<E> next = top.next;
top.next = next.next;
return next.item;
}
private static class Node<E>{
E item;
Node<E> next;
public Node(E item, Node<E> next){
this.item = item;
this.next = next;
}
}
}
对于查找操作,相对链表而言,链栈没有额外的改变,它也需要遍历整个栈来完成基于某些条件的数值查找。
- 不管是顺序栈还是链栈,数据的新增、删除、查找与线性表的操作原理极为相似,时间复杂度完全一样,都依赖当前位置的指针来进行数据对象的操作。区别仅仅在于新增和删除的对象,只能是栈顶的数据结点。
栈的案例
- 我们可以通过一个案例来看栈的具体使用,这里选取
leetcode上的案例来练习,如下
有效括号
- 给定一个只包括
'(',')','{','}','[',']'的字符串,判断字符串是否有效。有效字符串需满足:左括号必须与相同类型的右括号匹配,左括号必须以正确的顺序匹配。例如,{ [ ( ) ( ) ] }是合法的,而{ ( [ ) ] }是非法的。 - 这个问题很适合采用栈来处理。原因是,在匹配括号是否合法时,左括号是从左到右依次出现,而右括号则需要按照“后进先出”的顺序依次与左括号匹配。因此,实现方案就是通过栈的进出来完成。
- 具体的实现思路,我们可以遍历字符串从左起,当遇到左括号时进行压榨操作,而到遇到右括号时则继续出栈,判断出栈的括号是否与当前的右括号是一对,如果不是则非法,如果一致则继续遍历直到结束
- 代码如下:
public boolean isValid(String s) {
Stack stack = new Stack();
for(int i =0;i<s.length();i++){
char curr = s.charAt(i);
if (isLeft(curr)) {
stack.push(curr);
}else {
if (stack.empty())
return false;
if (!isPair(curr,(char)stack.pop())){
return false;
}
}
}
if (stack.empty()){
return true;
}else {
return false;
}
}
public boolean isPair(char curr,char expt){
if ((expt == '[' && curr == ']') || (expt == '{' && curr == '}') || (expt == '(' && curr == ')'))
return true;
return false;
}
public boolean isLeft(char c){
if (c == '{' || c == '[' || c == '(')
return true;
return false;
}
总结
- 栈继承了线性表特性,是一个特殊的线性表
- 栈只允许数据从栈顶进出,即栈的特性先进后出
- 不管是顺序栈还是链式栈,它们对于数据的新增操作和删除操作的时间复杂度都是
O(1)。而在查找操作中,栈和线性表一样只能通过全局遍历的方式进行,也就是需要O(n)的时间复杂度 - 当我们面临频繁增删节点,同时数据顺序有后来居上的特点时栈就是个不错的选择。例如,浏览器的前进和后退,括号匹配等问题
推荐阅读
- 《Java并发编程-线程基础》
- 《总算把线程六种状态的转换说清楚了!》
- 《[高频面试]解释线程池的各个参数含义》
- 《知道线程池的四种拒绝策略吗?》
- 《java中常见的六种线程池详解》
- 《基于synchronized的锁的深度解析》💡推荐
- 《JAVA中常见的阻塞队列详解》
- 《优雅关闭线程池的方案》
本文由AnonyStar 发布,可转载但需声明原文出处。
欢迎关注微信公账号 :云栖简码 获取更多优质文章
更多文章关注笔者博客 :云栖简码 i-code.online

 浙公网安备 33010602011771号
浙公网安备 33010602011771号