

canal
官网:https://github.com/alibaba/canal
什么是canal
阿里巴巴B2B公司,因为业务的特性,卖家主要集中在国内,买家主要集中在国外,所以衍生出了杭州和美国异地机房的需求,从2010年开始,阿里系公司开始逐步的尝试基于数据库的日志解析,获取增量变更进行同步,由此衍生出了增量订阅&消费的业务。
canal是用java开发的基于数据库增量日志解析,提供增量数据订阅&消费的中间件。目前,canal主要支持了MySQL的binlog解析,解析完成后才利用canal client 用来处理获得的相关数据。(数据库同步需要阿里的otter中间件,基于canal)。
这里我们可以简单地把canal理解为一个用来同步增量数据的一个工具: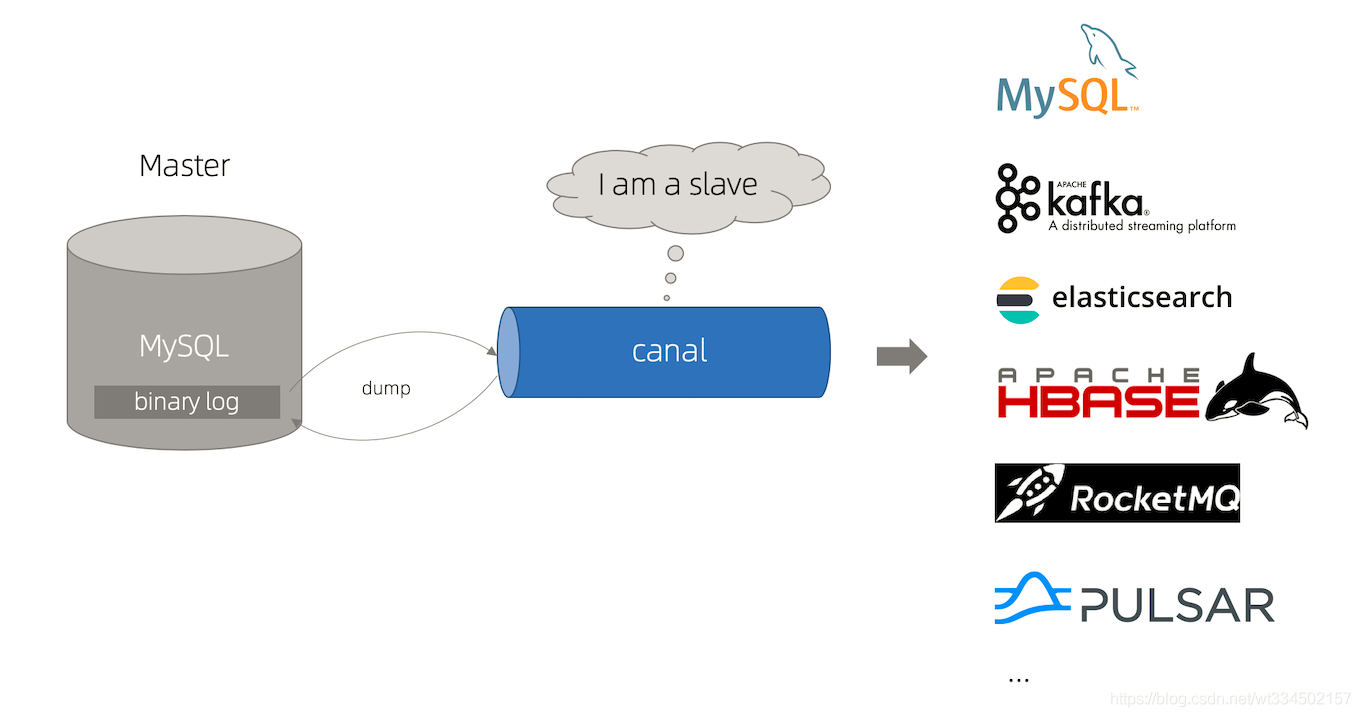
canal通过binlog同步拿到变更数据,再发送到存储目的地,比如MySQL,Kafka,Elastic Search等多源同步。
canal使用场景
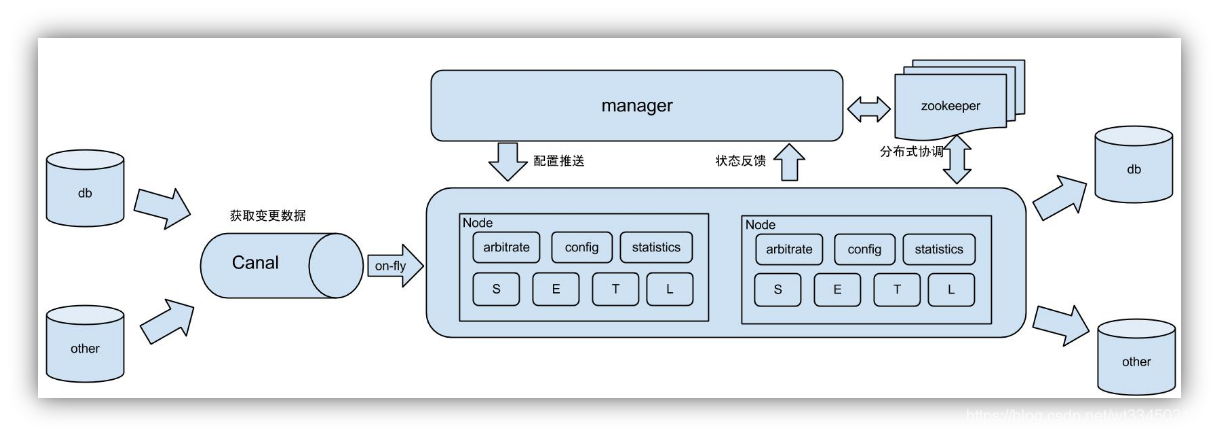
场景1:原始场景, 阿里otter中间件的一部分
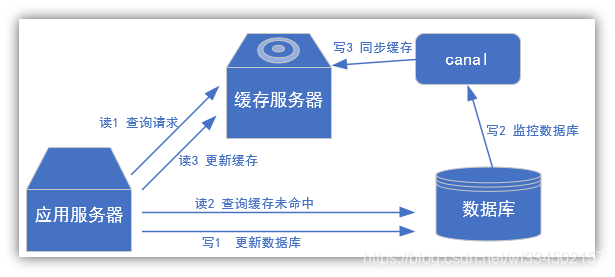
场景2:更新缓存
场景3:抓取业务数据新增变化表,用于制作拉链表。( 拉链表:记录每条信息的生命周期,一旦一条记录的生命周期结束,就要重新开始一条新的记录,并把当前日期放入生效的开始日期 )
场景4:抓取业务表的新增变化数据,用于制作实时统计。
canal运行原理

复制过程分成三步:
Master主库将改变记录,写到二进制日志(binary log)中
Slave从库向mysql master发送dump协议,将master主库的binary log events拷贝到它的中继日志(relay log);
Slave从库读取并重做中继日志中的事件,将改变的数据同步到自己的数据库。
canal的工作原理很简单,就是把自己伪装成slave,假装从master复制数据。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!