

一致性哈希算法
背景
当前后台微服务架构盛极一时,docker技术日趋成熟,二者如同伯牙子期的相遇,天作之合。而服务容器化在任何业务背景下都会遇到动态扩缩容,随着业务的访问量级波动,容器资源的自动化增加和回收可以为运维减少压力。
此外,在扩缩容前后,都需要负载均衡来维持各节点上的负载压力,从而使得扩缩容变得更加“优雅”。负载均衡技术中常用的算法模型就会涉及到一致性哈希算法。
求余哈希算法
服务集群中每个节点都有个“哈希地址”作为唯一标识,其计算公式简写如下:
add = hash(object) mod Nadd=hash(object)modN
当发生扩缩容导致增加或减少一个节点时,剩余节点的地址映射都会发生改变
add = hash(object) mod (N±1)add=hash(object)mod(N±1)
进而导致所有节点的数据需要迁移,代价太大
一致性哈希算法
一致性哈希将哈希值空间设计成“环状”,值域为[0,2^32-1],定义域可以使用节点的IP或主机名来计算。
假设我们有3个节点和4个数据,其地址在哈希值空间的分布如下:
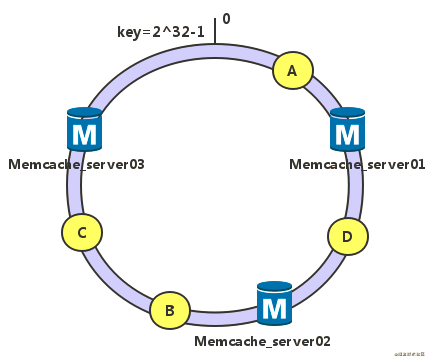
按照一致性哈希算法,每个数据按顺时针方向,绑定到距离它最近的节点,例如数据A绑定01节点,数据D绑定02节点,数据B、C绑定03节点。
假设03节点被缩减掉,数据B和C就需要绑定到01节点,其余数据和节点不需要迁移。
假设增加一个节点04,如下图,按照一致性哈希算法,只需要将数据B重新迁移到节点04即可。

总结
一致性哈希算法,因为其特殊的数据结构和数据绑定算法,使得在节点增加和减少时,可发生的数据迁移量大大减少,数据迁移减少,带来的应用价值就是减少动态扩缩容的时间。
目前市面上“秒级”的扩缩容产品非常少,大部分都在“分钟级”,当扩缩容反应越灵敏,在业务运营大型活动时,发生服务宕机或者雪崩的概率就会大大降低



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!