Alibaba Cloud SchedulerX
Schedulerx2.0是阿里中间件自研的基于Akka架构的新一代分布式任务调度平台,提供定时、任务编排、分布式跑批等功能。Schedulerx2.0可以在控制台配置管理您的定时任务,查询历史执行记录,查看运行日志。还可以通过工作流进行任务编排和数据传递。Schedulerx2.0还提供了简单易用的分布式编程模型,简单几行代码就可以将海量数据分布式到多台机器上执行
官网:https://help.aliyun.com/document_detail/148193.html
多种表达式的定时调度
- Crontab:支持Unix Crontab表达式,详情请参见Cron。不支持秒级别。
- Fixed rate:Crontab必须被60整除,不支持其它数量级时间间隔的任务,如每隔40分钟的定时任务。Fixed rate专门用来做定期轮询,可以弥补Crontab的不足,且表达式简单,详情请参见Fixed rate。不支持秒级别。
- Second delay:适用于对实时性要求比较高的业务,例如执行间隔为10秒的定时调度任务,详情请参见Second delay。支持秒级别。
- 日历:支持多种日历,还可以自定义导入日历。适用于金融业务,如需要在每个交易日执行定时任务。
- 时区:适用于跨国业务,如需要在每个国家所在时区执行定时任务。
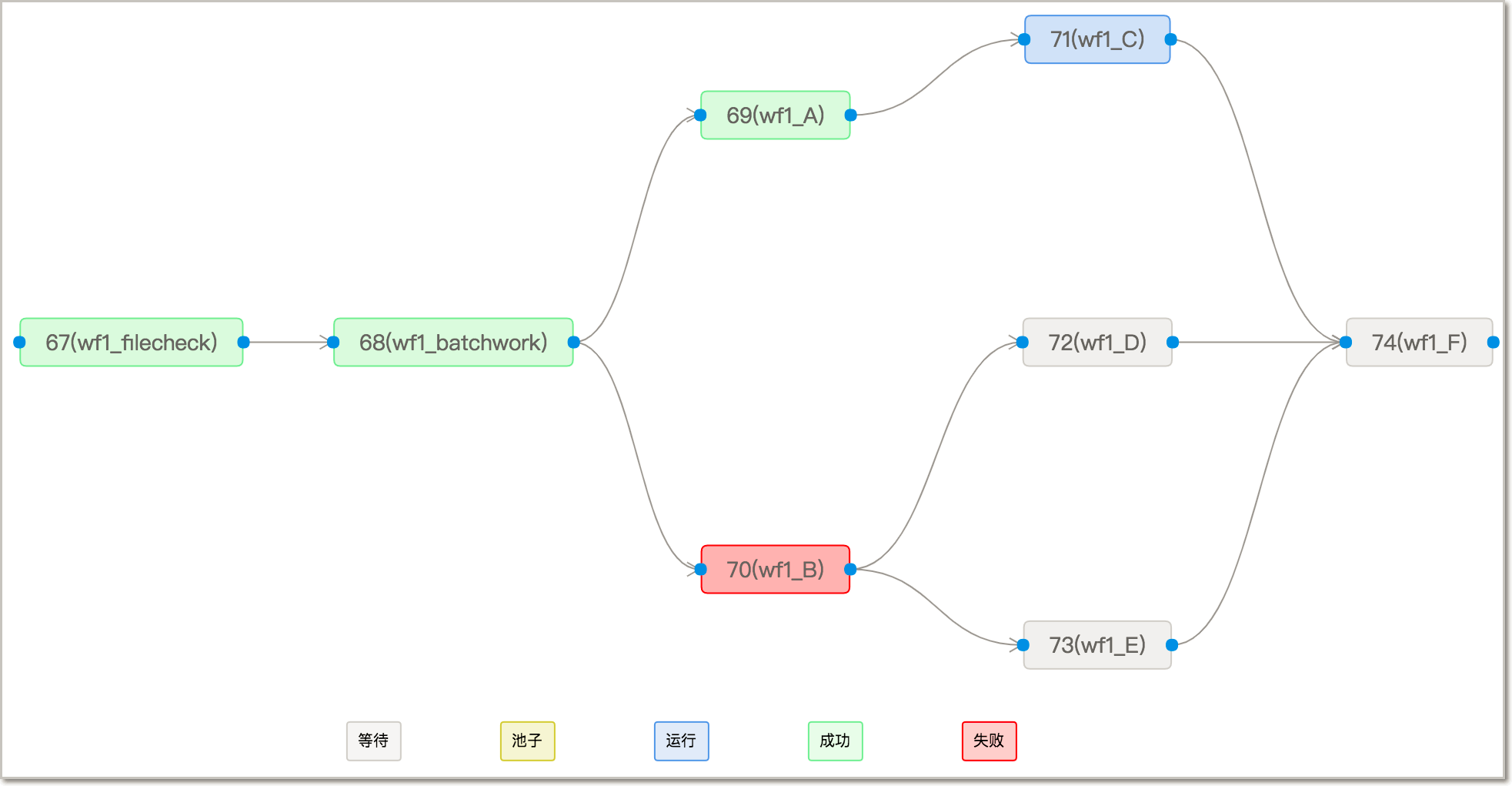
调度任务编排
使用有向无环图DAG(Directed Acyclic Graph)进行任务编排,操作简单,前端直接拖拖拽拽即可。详细的任务状态图能直观的看到下游任务为什么没执行。详情请参见创建工作流。
多种调度任务类型
在定时调度和工作流调度中支持基于多语言的多种任务类型。
- Java:可以在用户进程中执行,也可以通过上传JAR包动态加载。详情请参见Java任务。
- Shell:前端直接写Shell脚本。详情请参见脚本任务。
- Python:前端直接写Python脚本,需要Python环境。详情请参见脚本任务。
- Go:前端直接写Go脚本,需要Go环境。详情请参见脚本任务。
- HTTP(Serverless):支持Serverless的HTTP任务,包含GET和POST两种方法,无需依赖Client,在控制台配置完即可生效使用。详情请参见HTTP任务(Serverless)。
- 自定义:可以自定义任务类型,然后实现一个Plugin即可。
分布式计算
提供简单、易用的分布式编程模型,可以进行大数据跑批。
- 单机:随机挑选一台机器执行。详情请参见单机。
- 广播:所有机器同时执行且等待全部结束。详情请参见广播。
- Map模型:类似于Hadoop MapReduce里的Map。只要实现一个Map方法,简单几行代码就可以将海量数据分布式到多台机器上执行。详情请参见Map模型。
- MapReduce模型:MapReduce模型是Map模型的扩展,废弃了postProcess方法,新增Reduce接口。所有子任务完成后会执行Reduce方法,可以在Reduce方法中返回该任务实例的执行结果,或者回调业务。详情请参见MapReduce模型。
- 分片运行:类似Elastic-Job模型,控制台配置分片参数,可以将分片平均分给多个客户端执行。支持多语言版本。详情请参见多语言版本分片模型。
资源管理和任务优先级
通过应用级别资源管理,可以控制一个应用同时运行的最大任务数量。再通过任务优先级,可以实现类似于yarn的任务优先级队列,超过并发数的任务在队列中等待,高优先级任务会抢占低优先级任务优先调度。
很多场景下都有应用级别资源控制和任务优先级的需求。例如数据平台每天要收集报表,可能会有成千上万的任务在夜间执行。如果没有资源控制,所有任务一起执行会导致应用不可用。运营报表又必须在早上9点前生成,这就需要在资源控制的基础上,高优先级任务优先调度。如果低优先级任务先进入队列,高优先任务也能抢占优先调度。
运维能力
- 数据大盘:控制台提供了执行记录大盘和执行列表,可以看到每个任务的执行历史,并提供操作。
- 查看日志:每次执行的调度任务都可以在详情中查看运行日志。如果任务执行失败,前端直接就能看到错误日志,非常方便。详情请参见查看任务实例详情。
- 原地重跑:任务失败,修改完代码发布后,可以立即重新执行。
- 标记成功:任务失败,如果后台把数据处理修正了,重新执行又需要几个小时,可以直接将任务标记为成功。
- 停止调度任务:实现JobProcessor的
kill()接口,您就可以在前端停止正在运行的任务,甚至子任务。
数据偏移时间
SchedulerX可以处理有数据状态的任务,在创建任务的时候设置调度时间,而实际上处理的数据时间可能和任务执行时间不一致,可以配置时间偏移,调度时间 + 时间偏移即数据时间。例如一个任务是每天00:30运行,但是实际上要处理前一天的数据,就可以向前偏移一个小时。调度时间不变,执行的时候通过context.getDataTime()获得的就是前一天23:30。
重刷数据
既然任务具有了数据时间,就会用到重刷数据。例如一个工作流最终产生一个报表,但是业务发生变更(新增一个字段)或者发现上一个月的数据有错误,那么就需要重刷过去一个月的数据。通过重刷数据功能,可以重刷某些任务/工作流的数据(只支持天级别),每个实例都是不同的数据时间。详情请参见重刷调度任务。
失败自动重试
- 实例失败自动重试:在任务管理的高级配置中,可以配置实例失败重试次数和重试间隔,例如重试3次,每次间隔30秒。如果重试3次仍旧失败,该实例状态才会变为失败,并发送报警。
- 子任务失败自动重试:如果是分布式任务(并行计算/内网网格/网格计算),子任务也支持失败自动重试和重试间隔,同样可以通过任务管理的高级配置进行配置。
报警监控
- 失败报警
- 超时报警
- 无可用机器报警
- 报警方式:短信
名词解释
- AppGroup
- 即应用分组,映射用户的具体应用,关联绑定机器,用来做业务的隔离。
- DAG
- Directed Acyclic Graph,即有向无环图。所谓有向无环图是指任意一条边有方向,且不存在环路的图。
- Job
- 即任务,Job是SchedulerX中调度的最小单位。
- Job instance
- 即任务实例,Job每次调度会产生一个JobInstance。
- Namespace
- 即命名空间,SchedulerX提供的资源隔离服务,不同命名空间之间逻辑上天然隔离。命名空间帮助您将多个环境间的资源完全隔离,并可以使用一个账号进行统一管理。
- Task
- 即子任务,并行计算/内存网格/网格计算,通过Map方法会产生Task。
- Work Flow
- 即工作流,Work Flow是一个DAG(有向无环图),用来做任务编排。
- 调度时间
- JobInstance每次调度的时间叫做调度时间,JobProcessor可以根据
context.getScheduleTime()获取。
- 数据时间
- SchedulerX可以处理有数据状态的任务。创建任务的时候可以填数据偏移。例如一个任务是每天00:30运行,但是实际上要处理上一天的数据,就可以向前偏移一个小时。运行时间不变,执行的时候通过
context.getDataTime()获得的就是23:30(前一天)。
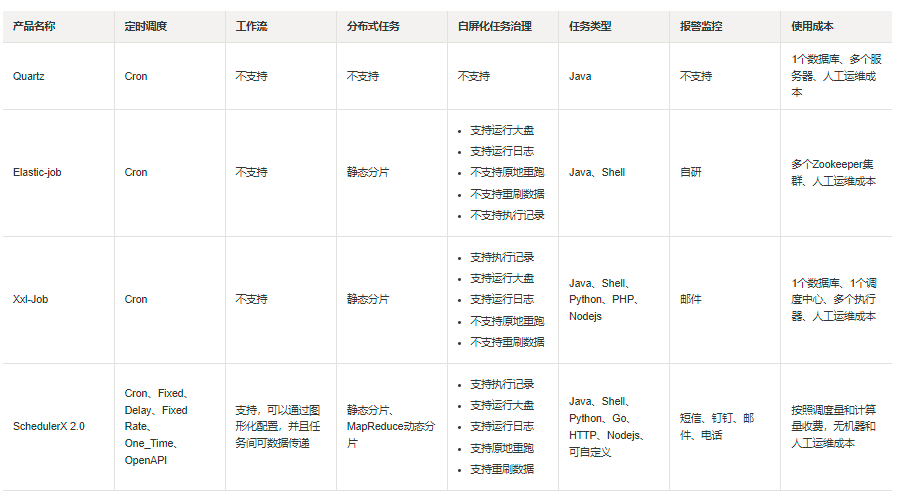
和开源产品对比


 浙公网安备 33010602011771号
浙公网安备 33010602011771号