

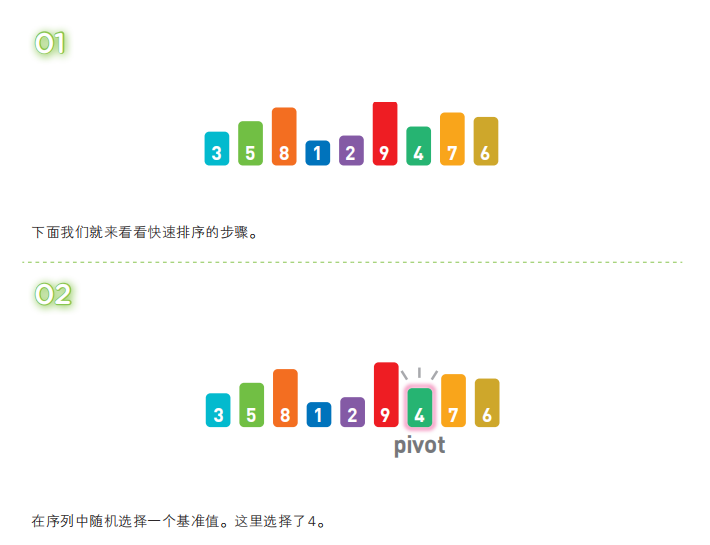
排序--快速排序
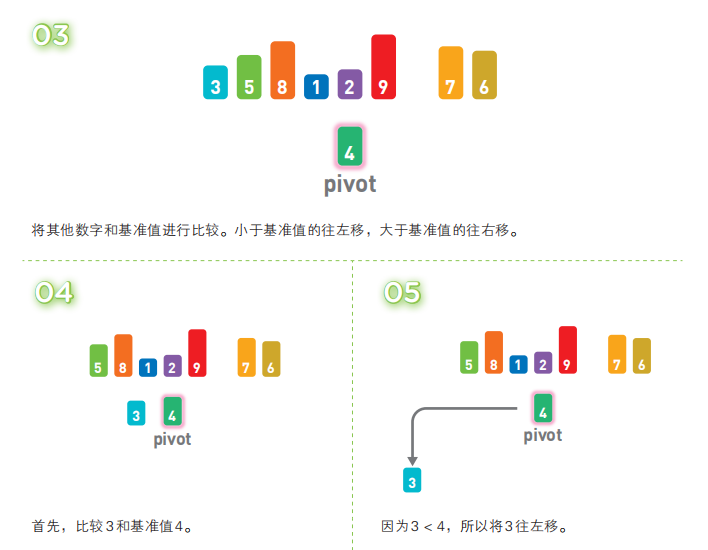
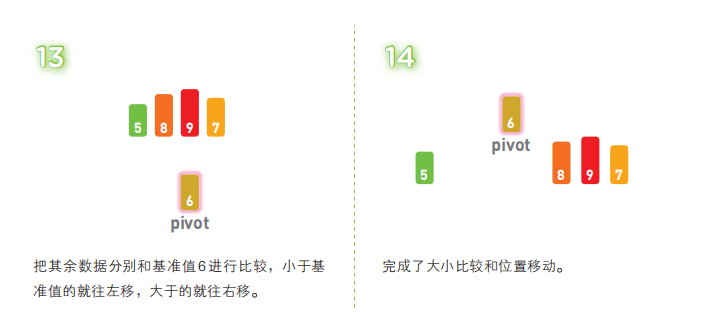
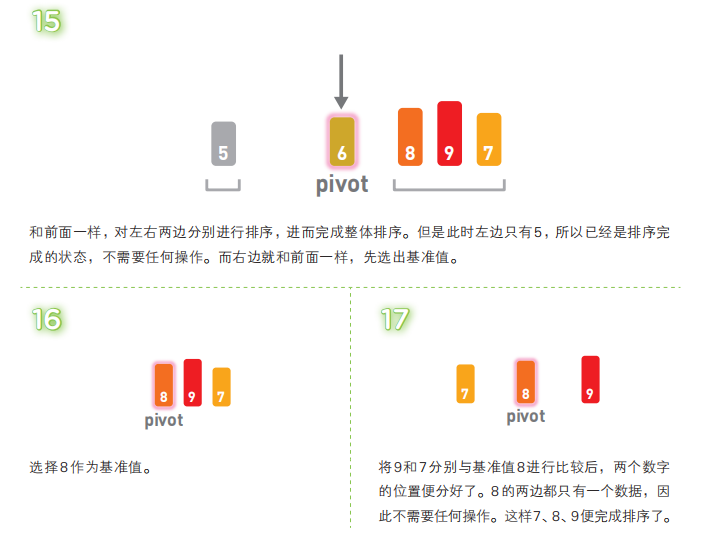
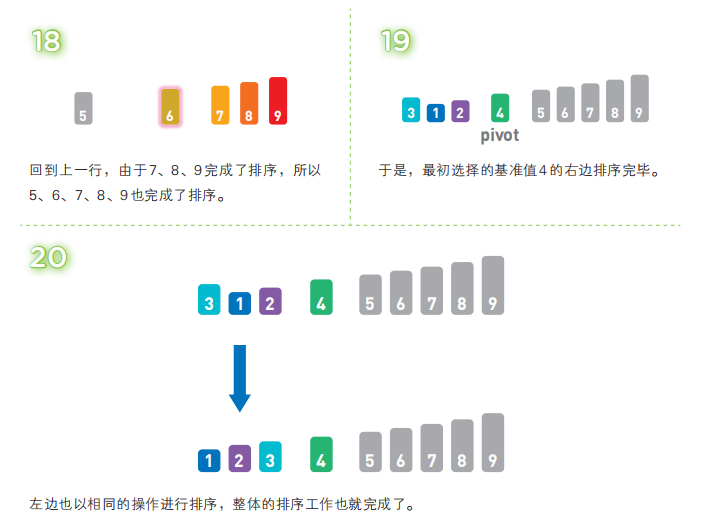
快速排序算法首先会在序列中随机选择一个基准值(pivot),然后将除了基准值以外的数分为“比基准值小的数”和“比基准值大的数”这两个类别,再将其排列成以下形式。
[ 比基准值小的数 ] 基准值 [ 比基准值大的数 ]
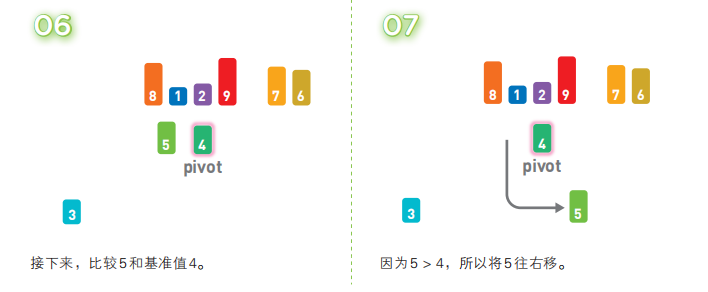
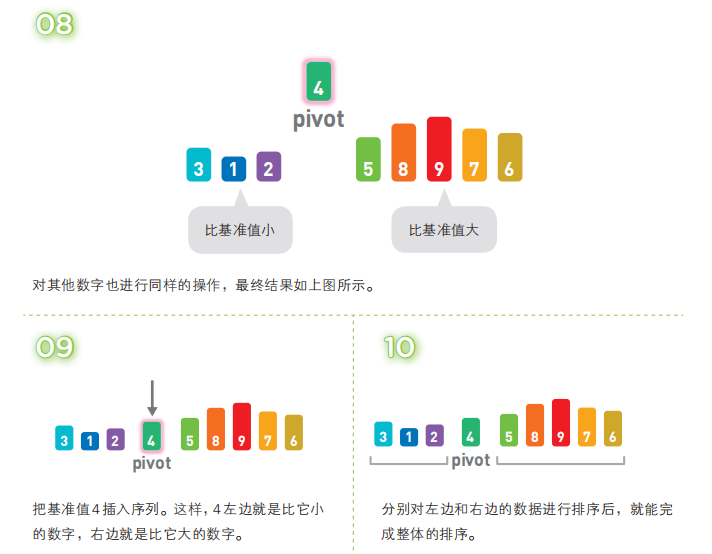
接着,对两个“[ ]”中的数据进行排序之后,整体的排序便完成了。对“[ ]”里面的数据进行排序时同样也会使用快速排序。

解说
分割子序列时需要选择基准值,如果每次选择的基准值都能使得两个子序列的长度为原本的一半,那么快速排序的运行时间和归并排序的一样,都为 O(nlogn)。和归并排序类似,将序列对半分割 log2n 次之后,子序列里便只剩下一个数据,这时子序列的排序也就完成了。因此,如果像下图这样一行行地展现根据基准值分割序列的过程,那么总共会有 log2n 行。
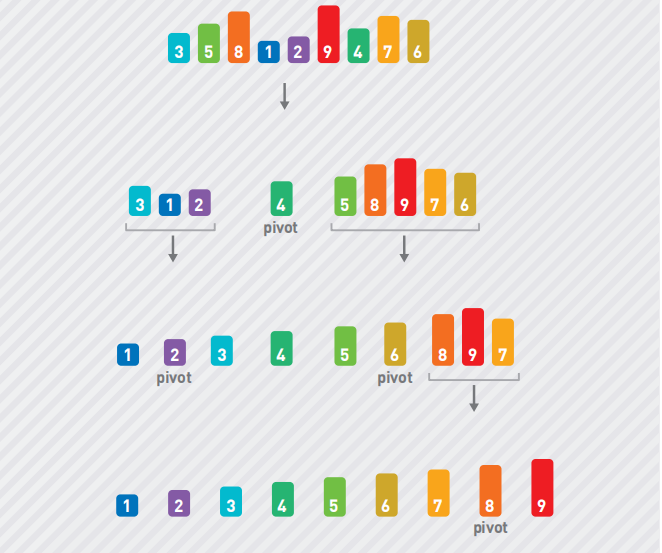
每行中每个数字都需要和基准值比较大小,因此每行所需的运行时间为 O(n)。由此可知,整体的时间复杂度为 O(nlogn)。如果运气不好,每次都选择最小值作为基准值,那么每次都需要把其他数据移到基准值的右边,递归执行 n 行,运行时间也就成了 O(n2)。这就相当于每次都选出最小值并把它移到了最左边,这个操作也就和选择排序一样了。此外,如果数据中的每个数字被选为基准值的概率都相等,那么需要的平均运行时间为 O(nlogn)。
补充说明
快速排序是一种“分治法”。它将原本的问题分成两个子问题(比基准值小的数和比基准值大的数),然后再分别解决这两个问题。子问题,也就是子序列完成排序后,再像一开始说明的那样,把他们合并成一个序列,那么对原始序列的排序也就完成了。不过,解决子问题的时候会再次使用快速排序,甚至在这个快速排序里仍然要使用快速排序。只有在子问题里只剩一个数字的时候,排序才算完成。像这样,在算法内部继续使用该算法的现象被称为“递归”。实际上前一节中讲到的归并排序也可看作是一种递归的分治法。

public static void main(String[] args) { int arr[] = {7, 5, 3, 2, 4}; //插入排序 for (int i = 1; i < arr.length; i++) { //外层循环,从第二个开始比较 for (int j = i; j > 0; j--) { //内存循环,与前面排好序的数据比较,如果后面的数据小于前面的则交换 if (arr[j] < arr[j - 1]) { int temp = arr[j - 1]; arr[j - 1] = arr[j]; arr[j] = temp; } else { //如果不小于,说明插入完毕,退出内层循环 break; } } } }
不积跬步,无以至千里;不积小流,无以成江海



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!