

数据结构--堆
堆是一种图的树形结构,被用于实现“优先队列”(priority queues)
优先队列是一种数据结构,可以自由添加数据,但取出数据时要从最小值开始按顺序取出。在堆的树形结构中,各个顶点被称为“结点”(node),数据就存储在这些结点中。


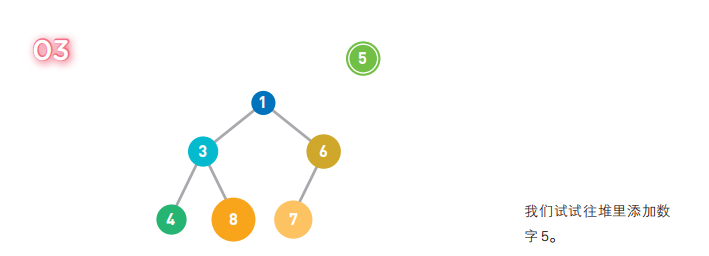
这就是堆的示例。结点内的数字就是存储的数据。堆中的每个结点最多有两个子结点。树的形状取决于数据的个数。另外,结点的排列顺序为从上到下,同一行里则为从左到右。
在堆中存储数据时必须遵守这样一条规则 :子结点必定大于父结点。因此,最小值被存储在顶端的根结点中。往堆中添加数据时,为了遵守这条规则,一般会把新数据放在最下面一行靠左的位置。当最下面一行里没有多余空间时,就再往下另起一行,把数据加在这一行的最左端。





解说
堆中最顶端的数据始终最小,所以无论数据量有多少,取出最小值的时间复杂度都为 O(1)。另外,因为取出数据后需要将最后的数据移到最顶端,然后一边比较它与子结点数据的大小,一边往下移动,所以取出数据需要的运行时间和树的高度成正比。假设数据量为n,根据堆的形状特点可知树的高度为 log2n ,那么重构树的时间复杂度便为 O(logn)。添加数据也一样。在堆的最后添加数据后,数据会一边比较它与父结点数据的大小,一边往上移动,直到满足堆的条件为止,所以添加数据需要的运行时间与树的高度成正比,也是 O(logn)。
应用示例
如果需要频繁地从管理的数据中取出最小值,那么使用堆来操作会非常方便。比如狄克斯特拉算法,每一步都需要从候补顶点中选择距离起点最近的那个顶点。此时,在顶点的选择上就可以用到堆。
不积跬步,无以至千里;不积小流,无以成江海



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!