

消息中间件
1 什么是消息中间件?
是利用高效可靠的消息传递机制进行异步的数据传输,并基于数据通信进行分布式系统的集成。通过提供消息队列模型和消息传递机制,可以在分布式环境下扩展进程间的通信。
通俗点就是发送者将消息发送给消息服务器,消息服务器将消感存放在若千队列中,在合适的时候再将消息转发给接收者
2 什么是JMS?
JMS是java的消息服务,JMS的客户端之间可以通过JMS服务进行异步的消息传输。
3 什么是消息模型?
○ Point-to-Point(P2P) --- 点对点
P2P模式图:
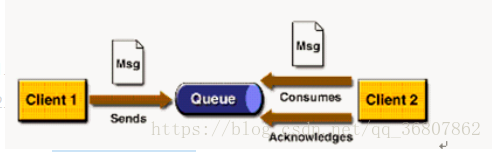
涉及到的概念 :
消息队列(Queue)
发送者(Sender)
接收者(Receiver)
每个消息都被发送到一个特定的队列,接收者从队列中获取消息。队列保留着消息,直到他们被消费或超时。
P2P的特点:
每个消息只有一个消费者(Consumer)(即一旦被消费,消息就不再在消息队列中)
发送者和接收者之间在时间上没有依赖性,也就是说当发送者发送了消息之后,不管接收者有没有正在运行,它不会影响到消息被发送到队列
接收者在成功接收消息之后需向队列应答成功
应用场景:
如果你希望发送的每个消息都应该被成功处理的话,那么你需要P2P模式。A用户与B用户发送消息
○ Publish/Subscribe(Pub/Sub)--- 发布订阅
Pub/Sub模式图 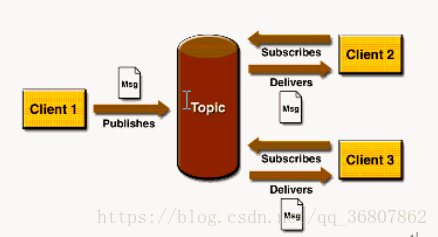
涉及到的概念
发布者(Publisher)
订阅者(Subscriber)
客户端将消息发送到主题。多个发布者将消息发送到Topic,系统将这些消息传递给多个订阅者。
Pub/Sub的特点
每个消息可以有多个消费者
发布者和订阅者之间有时间上的依赖性。针对某个主题(Topic)的订阅者,它必须创建一个订阅者之后,才能消费发布者的消息,而且为了消费消息,订阅者必须保持运行的状态。为了缓和这样严格的时间相关性,JMS允许订阅者创建一个可持久化的订阅。这样,即使订阅者没有被激活(运行),它也能接收到发布者的消息。
如果你希望发送的消息可以不被做任何处理、或者被一个消息者处理、或者可以被多个消费者处理的话,那么可以采用Pub/Sub模型
消息的消费
在JMS中,消息的产生和消息是异步的。对于消费来说,JMS的消息者可以通过两种方式来消费消息。
○ 同步 订阅者或接收者调用receive方法来接收消息,receive方法在能够接收到消息之前(或超时之前)将一直阻塞
○ 异步 订阅者或接收者可以注册为一个消息监听器。当消息到达之后,系统自动调用监听器的onMessage方法。
应用场景:
用户注册、订单修改库存、日志存储
4 MQ产品的分类
RabbitMQ
是使用Erlang编写的一个开源的消息队列,本身支持很多的协议:AMQP,XMPP, SMTP, STOMP,也正是如此,使的它变的非常重量级,更适合于企业级的开发。同时实现了一个经纪人(Broker)构架,这意味着消息在发送给客户端时先在中心队列排队。对路由(Routing),负载均衡(Load balance)或者数据持久化都有很好的支持。
Redis
是一个Key-Value的NoSQL数据库,开发维护很活跃,虽然它是一个Key-Value数据库存储系统,但它本身支持MQ功能,所以完全可以当做一个轻量级的队列服务来使用。对于RabbitMQ和Redis的入队和出队操作,各执行100万次,每10万次记录一次执行时间。测试数据分为128Bytes、512Bytes、1K和10K四个不同大小的数据。实验表明:入队时,当数据比较小时Redis的性能要高于RabbitMQ,而如果数据大小超过了10K,Redis则慢的无法忍受;出队时,无论数据大小,Redis都表现出非常好的性能,而RabbitMQ的出队性能则远低于Redis。
ZeroMQ
号称最快的消息队列系统,尤其针对大吞吐量的需求场景。ZMQ能够实现RabbitMQ不擅长的高级/复杂的队列,但是开发人员需要自己组合多种技术框架,技术上的复杂度是对这MQ能够应用成功的挑战。ZeroMQ具有一个独特的非中间件的模式,你不需要安装和运行一个消息服务器或中间件,因为你的应用程序将扮演了这个服务角色。你只需要简单的引用ZeroMQ程序库,可以使用NuGet安装,然后你就可以愉快的在应用程序之间发送消息了。但是ZeroMQ仅提供非持久性的队列,也就是说如果down机,数据将会丢失。其中,Twitter的Storm中使用ZeroMQ作为数据流的传输。
ActiveMQ
是Apache下的一个子项目。 类似于ZeroMQ,它能够以代理人和点对点的技术实现队列。同时类似于RabbitMQ,它少量代码就可以高效地实现高级应用场景。RabbitMQ、ZeroMQ、ActiveMQ均支持常用的多种语言客户端 C++、Java、.Net,、Python、 Php、 Ruby等。
Jafka/Kafka
Kafka
是Apache下的一个子项目,是一个高性能跨语言分布式Publish/Subscribe消息队列系统,而Jafka是在Kafka之上孵化而来的,即Kafka的一个升级版。具有以下特性:快速持久化,可以在O(1)的系统开销下进行消息持久化;高吞吐,在一台普通的服务器上既可以达到10W/s的吞吐速率;完全的分布式系统,Broker、Producer、Consumer都原生自动支持分布式,自动实现复杂均衡;支持Hadoop数据并行加载,对于像Hadoop的一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。Kafka通过Hadoop的并行加载机制来统一了在线和离线的消息处理,这一点也是本课题所研究系统所看重的。Apache Kafka相对于ActiveMQ是一个非常轻量级的消息系统,除了性能非常好之外,还是一个工作良好的分布式系统。
ActiveMQ、RocketMQ、RabbitMQ、Kafka对比:
| 特性 | ActiveMQ | RabbitMQ | RocketMQ | kafka |
|---|---|---|---|---|
| 开发语言 | java | erlang | java | scala |
| 单机吞吐量 | 万级 | 万级 | 10万级 | 10万级 |
| 时效性 | ms级 | us级 | ms级 | ms级以内 |
| 可用性 | 高(主从架构) | 高(主从架构) | 非常高(分布式架构) | 非常高(分布式架构) |
| 功能特性 | 成熟的产品,在很多公司得到应用;有较多的文档;各种协议支持较好 | 基于erlang开发,所以并发能力很强,性能极其好,延时很低;管理界面较丰富 | MQ功能比较完备,扩展性佳 | 只支持主要的MQ功能,像一些消息查询,消息回溯等功能没有提供,毕竟是为大数据准备的,在大数据领域应用广。 |



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!
2017-05-06 Linux网络管理