
12.朴素贝叶斯-垃圾邮件分类
1. 读邮件数据集文件,提取邮件本身与标签。
列表
numpy数组
import csv
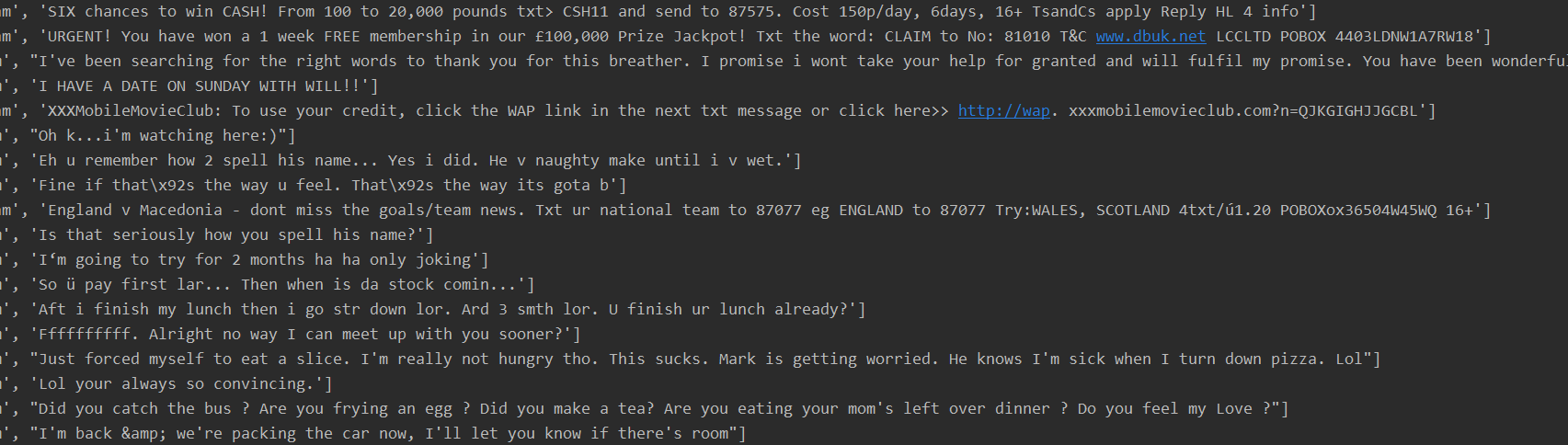
file_path = r"E:\大三下\1机器学习算法基础\14\SMSSpamCollection"
sms = open(file_path, 'r', encoding='utf-8')
data = csv.reader(sms, delimiter="\t")
for r in data:
print(r)
sms.close()
2.邮件预处理
- 邮件分句
- 名子分词
- 去掉过短的单词
- 词性还原
- 连接成字符串
- 传统方法来实现
- nltk库的安装与使用
pip install nltk
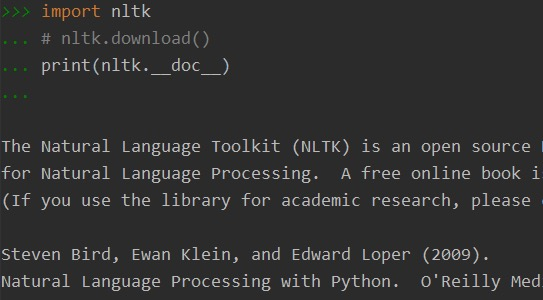
import nltk
nltk.download() # sever地址改成 http://www.nltk.org/nltk_data/
或
https://github.com/nltk/nltk_data下载gh-pages分支,里面的Packages就是我们要的资源。
将Packages文件夹改名为nltk_data。
或
网盘链接:https://pan.baidu.com/s/1iJGCrz4fW3uYpuquB5jbew 提取码:o5ea
放在用户目录。
----------------------------------
安装完成,通过下述命令可查看nltk版本:
import nltk
print nltk.__doc__
2.1 nltk库 分词
nltk.sent_tokenize(text) #对文本按照句子进行分割
nltk.word_tokenize(sent) #对句子进行分词
2.2 punkt 停用词
from nltk.corpus import stopwords
stops=stopwords.words('english')
*如果提示需要下载punkt
nltk.download(‘punkt’)
或 下载punkt.zip
https://pan.baidu.com/s/1OwLB0O8fBWkdLx8VJ-9uNQ 密码:mema
复制到对应的失败的目录C:\Users\Administrator\AppData\Roaming\nltk_data\tokenizers并解压。
2.3 NLTK 词性标注
nltk.pos_tag(tokens)
2.4 Lemmatisation(词性还原)
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
lemmatizer.lemmatize('leaves') #缺省名词
lemmatizer.lemmatize('best',pos='a')
lemmatizer.lemmatize('made',pos='v')
一般先要分词、词性标注,再按词性做词性还原。
2.5 编写预处理函数
def preprocessing(text):
sms_data.append(preprocessing(line[1])) #对每封邮件做预处理
3. 训练集与测试集
4. 词向量
5. 模型
def preprocessing(text):
tokens = []
# 对录入文本按照句子分割;
for sent in nltk.sent_tokenize(text):
# 对句子进行分词;
for word in nltk.word_tokenize(sent):
# 存放到token中
tokens.append(word)
# 去除停用词
stops = stopwords.words("english")
tokens = [token for token in tokens if token not in stops]
# NLTK词性标注
nltk.pos_tag(tokens)
# 词性还原Lemmatisation
# 定义还原对象
lemmatizer = WordNetLemmatizer()
# 还原名词
tokens = [lemmatizer.lemmatize(token, pos='n') for token in tokens]
# 还原动词
tokens = [lemmatizer.lemmatize(token, pos='v') for token in tokens]
# 还原形容词
tokens = [lemmatizer.lemmatize(token, pos='a') for token in tokens]
# 返回处理完成后的文本
return tokens;
# 数据读取
file_path = r"E:\大三下\1机器学习算法基础\14\SMSSpamCollection"
sms = open(file_path, 'r', encoding='utf-8')
sms_data = []
sms_label = []
csv_reader = csv.reader(sms, delimiter='\t')
# 预处理
for line in csv_reader:
sms_label.append(line[0])
sms_data.append(preprocessing(line[1]))
sms.close()
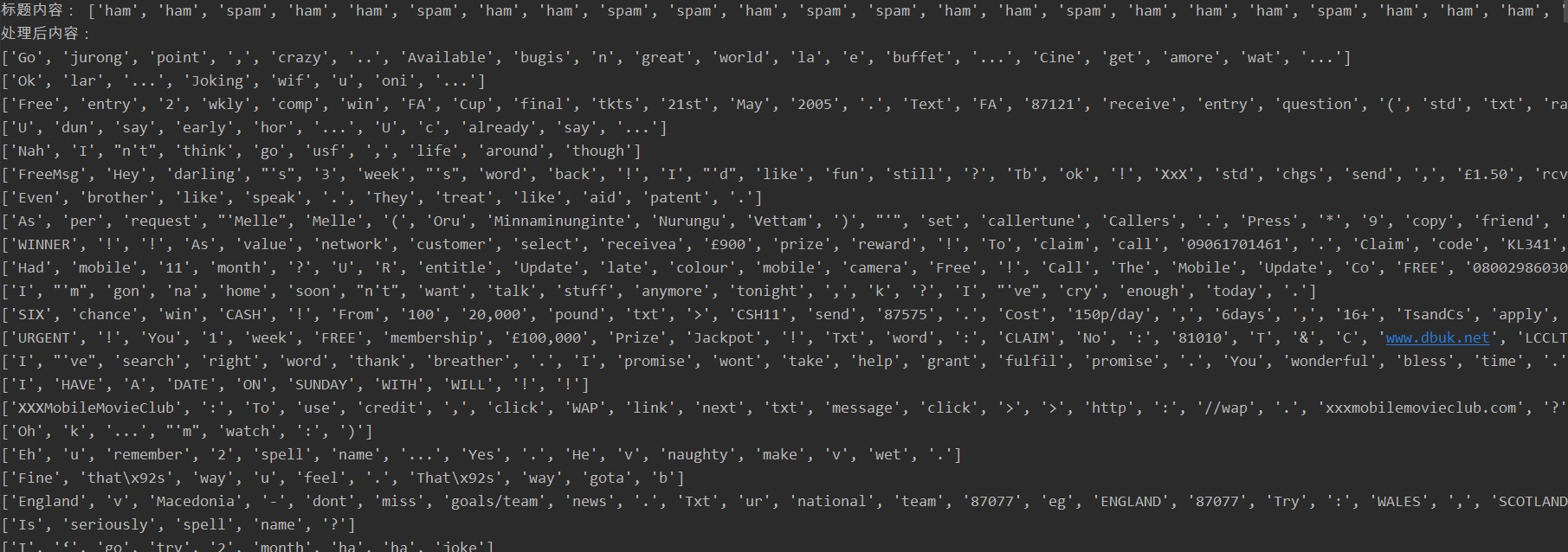
print("标题内容:", sms_label)
print("处理后内容:")
for i in sms_data:
print(i)



【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 自定义通信协议——实现零拷贝文件传输
· Brainfly: 用 C# 类型系统构建 Brainfuck 编译器
· 智能桌面机器人:用.NET IoT库控制舵机并多方法播放表情
· Linux glibc自带哈希表的用例及性能测试
· 深入理解 Mybatis 分库分表执行原理
· DeepSeek 全面指南,95% 的人都不知道的9个技巧(建议收藏)
· 自定义Ollama安装路径
· 本地部署DeepSeek
· 快速入门 DeepSeek-R1 大模型
· DeepSeekV3+Roo Code,智能编码好助手