
ajax资料
转变是从昨天天始的,这一周在公司主要精力都是在用 C++ 写 framework,不得不承认它比较辛苦,细枝末节之处非常之烦,昨天下午呆着呆着就不想干活了,就开始四处游荡,正好看到我们自己也有项目已经成功应用了 Ajax,于是也就想看一看,无奈那帮家伙的开发文档是出奇的少,只好在网上找找资料,自己研究研究吧。
作为一个技术人员,我看到一项新技术,总是喜欢琢磨琢磨它内部是如何实现的。在对 Ajax 有了初步认识以后,自然想看看其内部机制,但是令我失望的是,至少介绍 Ajax 内部实现的文章少之又少,好容易找到一篇,却也只是简单列了列一些 javascript 代码,并且没什么解释,颇为郁闷。想想求人不如求己,况且自己研究的或许印象更深一些。于是找到了一个 AjaxPro,下来琢磨琢磨,只是对于 JavaScript 我实在知之甚少,不明白之处依然很多,不过还是想写出来,抛砖引玉,望高人们不吝指教。
一、使用的例子
本文使用的例子很简单,一个文本框,在其中敲入文字之后,下方就显示该文字并加上一个“(Hello from server)”。源码如下(有删节):
 <%@ Page language="c#" ClassName="KeyPressDemo" Inherits="System.Web.UI.Page" %>
<%@ Page language="c#" ClassName="KeyPressDemo" Inherits="System.Web.UI.Page" %>

2
<script runat="server" language="c#">3
4
private void Page_Load(object sender, EventArgs e)5
 {
{
6
AjaxPro.Utility.RegisterTypeForAjax(typeof(KeyPressDemo));7
 }
}8
9
[AjaxPro.AjaxMethod]10
public string EchoInput(string s)11
{12
return s += " (Hello from server)";13
}14
15
 </script>
</script>16
17
<form id="Form1" method="post" runat="server"></form>18
19
<div class="content">20
<h1>KeyPressDemo Examples</h1>21
<p>Press any key in the textbox and see the echo in the DIV element on the right side.</p>22
<input type="text" id="myinput" onkeyup="doTest1();"/> <div id="mydisplay">---- empty ----</div>23
<p><i>Note, that I do not update the display if a request is running currently.</i></p>24
</div>25
26
<script type="text/javascript" defer="defer">27
28
var timer = null;29
30
function doTest1() {31
if(timer != null) {32
clearTimeout(timer);33
}34
timer = setTimeout(doTest1_next, 100);35
}36
37
function doTest1_next() {38
var ele = document.getElementById("myinput");39
ASP.KeyPressDemo.EchoInput(ele.value, doTest1_callback);40
}41
42
function doTest1_callback(res) {43
var ele = document.getElementById("mydisplay");44
ele.innerHTML = res.value;45
}46
47
</script>选用这个例子,是因为它比较简单,没有相关的 C# 文件。首先看看第17行,咦?怎么这个 form 里啥都没有?既然什么都没有?删掉它行不行?不行,绝对不行!看看网页打开后,这一行被扩展成了什么?
<form name="Form1" method="post" action="keypress.aspx" id="Form1">2
<div>3
<script type="text/javascript" src="/ajaxdemo/ajaxpro/core.ashx"></script>4
<script type="text/javascript" src="/ajaxdemo/ajaxpro/ASP.KeyPressDemo,App_Web_vxhzzzxr.ashx"></script>5
</form>6
请注意这里链入的两个 javascript 文件,它们是 Ajax 得以运行的基础!删掉 form 那一行,它们就不会出现,自然不行了。这两行是如何产生的?那就是页面代码的第4至7行的 PageLoad 函数的功劳了。
好,那这两个 javascript 文件我们能看到不?看上去它们是服务端的,并且事实上是服务端动态生成的。不过稍有些了解浏览器工作原理的人就会知道,到 Local Settings 下的 Temporary Internet Files 目录下去找,肯定是有的,因为浏览器下载页面的时候会把与页面相关的文件都下过来。
二、Ajax ClientScript 的执行总体流程
好,有了源页面代码,又有了两个 ClientScript 文件,我们就可以分析客户端的执行流程了。以下是我画的一张简单的流程图:
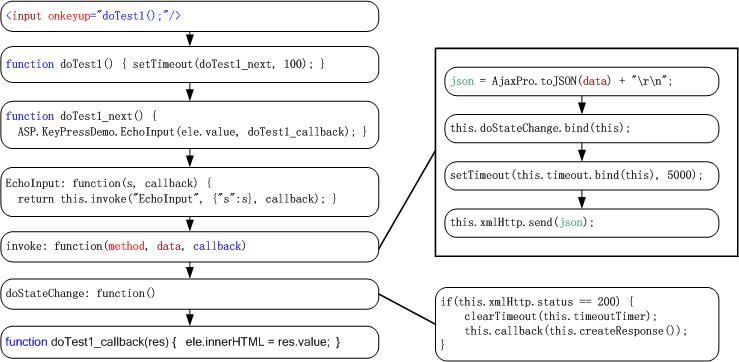
我们一个一个地来分析。
三、HTML页面做了什么?
第一步,当我们在 TextBox 里输入字符后,将会触发 onkeyup 事件。它要执行 doTest1 方法。见页面代码里的第22行。
第二步,doTest1 方法使用 setTimeout 函数,设定了 100 毫秒后,执行 doTest1_next 方法。见页面代码里的第34行。
第三步,doTest1_next 方法调用了 ASP.KeyPressDemo.EchoInput 方法,它带有两个参数,第一个是我们在文本框中输入的值,当然是个字符串类型的了;第二个则是一个 callback 函数,请留心这个函数,它将于整个流程的最后执行。
好,我们知道页面的客户端无外乎就是 HTML 和 JavaScript,虽然 ASP.KeyPressDemo.EchoInput 方法酷似页面里我们自己用 C# 写的函数,但可以肯定的是它绝对是用 JavaScript 实现的。在哪儿呢?嗯,在我们从 Temporary Internet Files 目录下找到的 ASP.KeyPressDemo,App_Web_vxhzzzxr.ashx 里。
四、ASP.KeyPressDemo,App_Web_vxhzzzxr.ashx 的实现
这个文件很小,以下是它的全部源码:
addNamespace("ASP");2
ASP.KeyPressDemo_class = Class.create();3
ASP.KeyPressDemo_class.prototype = (new AjaxPro.Request()).extend({4
EchoInput: function(s, callback) {5
return this.invoke("EchoInput", {"s":s}, callback);6
},7
initialize: function() {8
this.url = "/ajaxdemo/ajaxpro/ASP.KeyPressDemo,App_Web_vxhzzzxr.ashx";9
}10
})11
ASP.KeyPressDemo = new ASP.KeyPressDemo_class();12
啊哈,这下我们知道了,ASP.KeyPressDemo 其实是在这里用 JavaScript 定义的 ASP.KeyPressDemo_class 类的实例,EchoInput 则是它的一个方法。注意一下每3行,我们看到这个类是从 AjaxPro.Request 类继承的。什么什么?继承?有没有搞错?JavaScript 什么时候开始面向对象了而不是基于对象了?先摆下这个疑问,我们继续往下看。
EchoInput 方法的实现很简单,就是调用了一个 Invoke 方法。嗯,这个方法想必是从 AjaxPro.Request 类“继承”下来的。那它定义在哪儿?是了,还有一个 core.ashx 呢,它才是真正客户端实现 Ajax 技术的主角!这个文件太大,我们还是依照函数调用顺序慢慢来拆解罢。
五、Invoke 函数
Invoke 函数是核心所在,前面我画的流程图中已经简单地描述了它的主要流程。不过这个函数太重要了,这里还是列出它的全部源码:
AjaxPro.Request = Class.create();2
AjaxPro.Request.prototype = (new AjaxPro.Base()).extend({3
invoke: function(method, data, callback) {4
var async = typeof callback == "function" && callback != AjaxPro.noOperation;5
var json = AjaxPro.toJSON(data) + "\r\n";6
7
if(AjaxPro.cryptProvider != null)8
json = AjaxPro.cryptProvider.encrypt(json);9
10
this.callback = callback;11
12
if(async) {13
this.xmlHttp.onreadystatechange = this.doStateChange.bind(this);14
if(typeof this.onLoading == "function") this.onLoading(true);15
}16
17
this.xmlHttp.open("POST", this.url, async);18
this.xmlHttp.setRequestHeader("Content-Type", "application/x-www-form-urlencoded");19
this.xmlHttp.setRequestHeader("Content-Length", json.length);20
this.xmlHttp.setRequestHeader("Ajax-method", method);21
22
if(AjaxPro.token != null && AjaxPro.token.length > 0)23
this.xmlHttp.setRequestHeader("Ajax-token", AjaxPro.token);24
25
if(MS.Browser.isIE)26
this.xmlHttp.setRequestHeader("Accept-Encoding", "gzip, deflate");27
else28
this.xmlHttp.setRequestHeader("Connection", "close"); // Mozilla Bug #24665129
30
if(this.onTimeout != null && typeof this.onTimeout == "function")31
this.timeoutTimer = setTimeout(this.timeout.bind(this), this.timeoutPeriod);32
33
this.xmlHttp.send(json);34
35
json = null;36
data = null;37
delete json;38
delete data;39
40
if(!async) {41
return this.createResponse();42
}43
44
return true; 45
}46
});47
嗯,相当复杂啊。我们慢慢地看。
AjaxPro.Request 类当然不是只有 Invoke 一个函数,这里省去了其它函数。嗯,我们看到,AjaxPro.Request 也是从 AjaxPro.Base “继承”下来的。
第4行的 async,字面上理解就是指异步,这一行什么意思?嗯,如果传进来的 callback 类型是函数,并且不是无操作,那就认为是异步的。
第5行的 json,它可是相当重要啊。这里调用了 AjaxPro.toJSON 方法把传进来的数据进行了某种编码,本例中这个数据当然就是从 doTest1_next 一路传进来的 TextBox 里我们输入的字符串值了,这个函数的实现,本文也不再列出,可以参见 core.ashx 文件。
接下来第7到8行,如果提供了加密,那么就对 json 进行加密。这个好理解。
第12到15行,如果是异步的,那么这里将 doStateChange 函数绑定到 onreadystatechange 事件上去。嗯,这里的绑定其实也是在 core.ashx 文件里声明的一个方法,本文不再阐述它的实现了,大家有兴趣,可以自己去看。绑定完成后,当服务端完成操作后,doStateChange 函数会被调用,这时可以进行更改页面的工作。此外,这里还检测了一下 onLoading 事件。
第17行到第33行可谓核心代码,我们知道 Ajax 就是使用的 XMLHttpRequest 来完成无刷新页面的。这里我们可看到 this.xmlHttp 被用来进行了请求封装。其中值得我们注意的,Content-Length 使用的 json.length,Ajax-method 则使用的就是传进来的 AjaxMethod 方法名称,本例中为 EchoInput。第30、31行设置了超时处理,当然了,页面不能死等嘛。第33行则将 json 发送到服务端。
接下来的第41行,我们看到如果不是异步操作的话,此处将直接调用 createResponse 函数获得响应。那如果是异步操作呢?记得我们设置了 doStateChange 吧?异步的返回处理就是它的事了。createResponse 函数后面再介绍。
六、解释“继承”
前面我们好几次看到貌似继承。当然它们都仅仅是貌似而已。看看以下 core.ashx 中的代码就明白了:
Object.extend = function(destination, source) {2
for(property in source) {3
destination[property] = source[property];4
}5
return destination;6
}7
哈哈,所谓的“继承”,其实只是个属性拷贝而已。
七、this.xmlHttp 从何而来?
前面我们看到了 this.xmlHttp 大显神威。那么它是哪儿来的?看看 AjaxPro.Request 类的 initialize 函数吧(有删节):
initialize: function(url) {2
this.xmlHttp = new XMLHttpRequest();3
}4
是了,xmlHttp 只是 XMLHttpRequest 的一个实例。那么 XMLHttpRequest 的定义呢?
var lastclsid = null;2
if(!window.XMLHttpRequest) {3
4
function getXmlHttp(clsid) {5
var xmlHttp = null;6
try {7
xmlHttp = new ActiveXObject(clsid);8
lastclsid = clsid;9
return xmlHttp;10
} catch(ex) {}11
}12
13
window.XMLHttpRequest = function() {14
if(lastclsid != null) {15
return getXmlHttp(lastclsid);16
}17
18
var xmlHttp = null;19
var clsids = ["Msxml2.XMLHTTP.6.0","Msxml2.XMLHTTP.5.0","Msxml2.XMLHTTP.4.0","Msxml2.XMLHTTP.3.0","Msxml2.XMLHTTP.2.6","Microsoft.XMLHTTP.1.0","Microsoft.XMLHTTP.1","Microsoft.XMLHTTP"];20
21
for(var i=0; i<clsids.length && xmlHttp == null; i++) {22
xmlHttp = getXmlHttp(clsids[i]);23
}24
25
if(xmlHttp == null) {26
return new IFrameXmlHttp();27
}28
29
return xmlHttp;30
}31
}32
哦,原来是在这里真正创建的。说到底还是一个 ActiveXObject 啊。关于这个本文也不再多提。不过代码中还需要注意的一点是,
如果把第19行列出的一大堆clsids 都处理过了还没有得到对象怎么办?注意到第26行 new 了一个 IFrameXmlHttp。
IFrameHttp 是在 core.ashx 中定义的,它基本上完全模拟了 ActiveXObject 对象的功能。想研究研究的,自己看源码吧。篇幅所限,这里不多讲啦。
八、doStateChange 函数
嗯,前面已经提过,异步的话 doStateChange 函数将会在服务端返回后执行,看看它的源码呢:
doStateChange: function() {2
if(this.onStateChanged != null && typeof this.onStateChanged == "function")3
try{ this.onStateChanged(this.xmlHttp.readyState); }catch(e){}4
5
if(this.xmlHttp.readyState != 4)6
return;7
8
if(this.xmlHttp.status == 200) {9
if(this.timeoutTimer != null) clearTimeout(this.timeoutTimer);10
if(typeof this.onLoading == "function") this.onLoading(false);11
12
this.xmlHttp.onreadystatechange = AjaxPro.noOperation;13
14
this.callback(this.createResponse());15
this.callback = null;16
17
this.xmlHttp.abort();18
}19
},20
如果 status 是 200,也就是 OK,那么清除掉超时处理函数,处理 onLoading 事件,最后使用 callback 调用 createResponse 函数。还记得如果不是异步的话,createResponse 将会直接调用而不是通过 doStateChange 吧。
九、createResponse 函数
createResponse: function() {2
var r = new Object();3
r.error = null;4
r.value = null;5
6
var responseText = new String(this.xmlHttp.responseText);7
8
if(AjaxPro.cryptProvider != null && typeof AjaxPro.cryptProvider == "function")9
responseText = AjaxPro.cryptProvider.decrypt(responseText);10
11
eval("r.value = " + responseText + ";");12
13
if(r.error != null && this.onError != null && typeof this.onError == "function")14
try{ this.onError(r.error); }catch(e){}15
16
responseText = null;17
18
return r;19
} 如果前面的 json 也就是 Request 是加过密的,这里就需要对 responseText 进行解密。完了之后得到 r.value,r 将会被返回并提供给 callback 函数。本例中将最终传回 doTest1_callback,r 被传入它的 res 参数。最后更新文本框下的字符串,整个 Ajax ClientScript 的流程就差不多是完成了。
十、简单总结一下
呼,长出一口气。总算可以告一段落了,AjaxPro 服务端的拆解过段时间再说吧。
在分析 ClientScript 端的时候真是大有感触,JavaScript 其实远比人们想象的强大和管用。其实我同大多数人一样,起初也对它很不感冒,但是之前曾有两件事让我改变了观念。其一是阅读了黄忠成的《深入剖析 ASP.NET 组件设计》,才发现原来许多强大炫目的 ASP.NET 的控件,其实都是用的 JavaScript 实现。其二是在研究国外某文档浏览器实现的时候,发现人家使用 JavaScript 在 IE 下相当完美地实现了强大灵活有如桌面程序的界面和功能,真是吃惊不小。当时就发现了自己对 JavaScript 的了解实在是严重汗颜,惭愧无地。无奈平时没有多少时间去学习提高自己,只能偶尔抽抽空余时间了解了解,充充电吧。
相信 JavaScript 之类的脚本必将在未来的 Web 应用中大展身手。
一、 简介
AJAX,一个异步JavaScript和XML的缩略词,是最近出来的技术词语。异步意味着你可以经由超文本传输协议(HTTP)向一个服务器发出请求并且在等待该响应时继续处理另外的数据。这就意味着,例如,你可以调用一个服务器端脚本来从一个数据库中以XML方式检索数据,把数据发送到存储在一个数据库的服务器脚本,或者简单地装载一个XML文件以填充你的Web站点而不需刷新该页面。然而,在这项新技术提供巨大能力的同时,它也引起了在"Back"按钮问题上的很多争论。本文将帮助你确定在真实世界中何时使用AJAX是最佳选择。
首先,我假定你对缩略词JavaScript和XML部分有一个基本了解。尽管你能通过AJAX请求任何类型的文本文件,但是我在此主要集中讨论XML。我将解释怎样在真实世界中使用AJAX以及怎样在一个工程中评估它的价值。在你读完本文后,你将会明白什么是AJAX,在什么情况下,为什么以及怎样使用这项技术。你将要学习,在保持给用户提供直观体验的同时怎样创建对象,发出请求以及定制响应。
我已创建了一个适合于本文的示例工程(你可以下载源代码)。这个示例实现了一个简单的请求-它装载一个包含页面内容的XML文件并且分析数据以把它显示在一个HTML页面中。
二、 常规属性和方法
表1和2提供了一个属性和方法的概述-它们为 Windows Internet Explorer 5,Mozilla,Netscape 7,Safari 1.2,和 Opera 等浏览器所支持。
表1属性
| 属性 | 描述 |
| onreadystatechange | 当请求对象变化时该事件处理器激活。 |
| readyState | 返回指示对象的当前状态的值。 |
| responseText | 来自服务器的响应串的版本。 |
| responseXML | 来自服务器的响应的DOM兼容的文档对象。 |
| status | 来自服务器的响应的状态码。 |
| statusText | 以一个字符串形式返回的状态消息。 |
表2方法
| 方法 | 描述 |
| Abort() | 取消当前HTTP请求。 |
| getAllResponseHeaders() | 检索所有的HTTP头值。 |
| getResponseHeader("headerLabel") | 从响应体中检索一个HTTP头部的值。 |
| open("method","URL"[,asyncFlag[,"userName"[,"password"]]]) | 初始化一个MSXML2.XMLHTTP请求,并从该请求指定方法,URL和认证信息。 |
| send(content) | 发送一个HTTP请求到服务器并接收响应。 |
| setRequestHeader("label", "value") | 指定一个HTTP头的名字。 |
三、 从哪里开始
首先,你需要创建XML文件-后面我们对之进行请求并作为页面内容进行分析。你正在请求的文件必须与目标工程驻留在相同的服务器上。
下一步,创建发出请求的HTML文件。当页面通过使用页面主体中的onload方法进行加载时,该请求发生。接着,该文件需要一个有ID的div标签,这样当我们准备好要显示内容时就可以对之进行 定位 。当你做完所有这些,你的页面的主体看上去如下:
| <body onload="makeRequest('xml/content.xml');"> <div id="copy"></div> </body> |
四、 创建请求对象
为了创建请求对象,你必须检查是否浏览器使用XMLHttpRequest或ActiveXObject。这两个对象之间的主要区别在于使用它们的浏览器。Windows IE 5 及以上版本使用ActiveX对象;而Mozilla,Netscape 7,Opera和Safari 1.2及以上版本使用XMLHttpRequest对象。另外一个区别是你创建对象的方式:Opera,Mozilla,Netscape和Safari允许你简单地调用该对象的构造器,但是Windows IE需要把对象的名字传递到ActiveX构造器中。下面是怎样创建代码来决定要使用哪个对象和怎样创建它的示例:
| if(window.XMLHttpRequest) { request = new XMLHttpRequest();} else if(window.ActiveXObject) { request = new ActiveXObject("MSXML2.XMLHTTP");} |
五、 发出请求
现在既然你已经创建了你的请求对象,那么你已经为向服务器发出请求作了准备。创建一个到事件处理器的参考以听取onreadystatechange事件。然后,该事件处理器方法将在状态发生变化时作出响应。一旦我们完成请求,我们就开始创建这个方法。打开连接以GET或POST一个定制的URL-在此是一个content.xml,并且设置一个布尔定义-是否你想要进行异步调用。
现在到了发出请求的时间了。在这个示例中,我使用了null,因为我们使用的是GET;为了使用POST,你需要使用下面这个方法发出一个查询串:
| request.onreadystatechange = onResponse; request.open("GET". url, true); request.send(null); |
六、 定制加载和错误处理消息
你为onreadystatechange方法创建的事件处理器正是集中进行加载和处理错误的场所。现在到了考虑用户并针对他们与之交互的内容的状态提供反馈的时候了。在这个实例中,我针对所有的装载状态代码提供反馈,并且也对最经常发生的错误处理状态代码提供一些基本的反馈。为了显示请求对象的当前状态,readyState属性包括显示在下表中的一些值。
| 值 | 描述 |
| 0 | 未初始化,对象没有用数据进行初始化。 |
| 1 | 装载中,对象正在装载它的数据。 |
| 2 | 装载结束,对象完成了它的数据的装载。 |
| 3 | 可交互,用户能与对象交互了,尽管它还没有装载结束。 |
| 4 | 完成,对象已经完全被初始化。 |
W3C中有很长的一串有关HTTP状态代码的定义。我选择了两个状态代码:
·200:请求成功了。
·404:服务器没有找到与所请求的文件相匹配的任何东西。
最后,我检查任何另外的状况代码-它们将生成一个错误并提供一个一般错误信息。下面是一个代码示例-你可以用之来处理这些情况。注意,我在定位我们前面在HTML文件的主体中创建的div ID并且对它应用装载和/或错误信息-通过innerHTML方法-这个方法用于设置在div对象的开始和结束标签之间的HTML:
| if(obj.readyState == 0) { document.getElementById('copy').innerHTML = "Sending Request...";} if(obj.readyState == 1) { document.getElementById('copy').innerHTML = "Loading Response...";} if(obj.readyState == 2) { document.getElementById('copy').innerHTML = "Response Loaded...";} if(obj.readyState == 3) { document.getElementById('copy').innerHTML = "Response Ready...";} if(obj.readyState == 4){ if(obj.status == 200){ return true; } else if(obj.status == 404) { // 添加一个定制消息或把用户重定向到另外一个页面 document.getElementById('copy').innerHTML = "File not found"; } else {document.getElementById('copy').innerHTML = "There was a problem retrieving the XML."; } } |
当状况代码为200时,这意味着请求成功。下面开始进行响应了。
七、 分析响应
当你准备好分析来自请求对象的响应时,真正的工作开始了。现在你可以用你请求的数据开始工作。仅为测试目的,在开发期间,可以使用responseText和responseXML属性来显示来自响应的原始数据。为了存取XML响应中的结点,首先使用你创建的请求对象,定位到responseXML属性以检索(你可能已经猜测出来)来自响应的XML。定位到documentElement-它检索一个到XML响应的根结点的参考。
| var response = request.responseXML.documentElement; |
现在既然你有了到响应的根结点的参考,那么你可以使用getElementsByTagName()以结点名字来检索childNodes。下面一行用一个头部的nodeName来定位一个childNode:
| response.getElementsByTagName('header')[0].firstChild.data; |
使用firstChild.data可以允许你存取该元素中的文本:
| response.getElementsByTagName('header')[0].firstChild.data; |
下面是怎样创建这些代码的完整的例子:
| var response = request.responseXML.documentElement; var header = response.getElementsByTagName('header')[0].firstChild.data; document.getElementById('copy').innerHTML = header; |
八、 需求分析
现在既然你知道怎样使用AJAX的基础知识,那么下一步就是决定是否在一工程使用它。须记住的最重要的事情是,在你还没有刷新页面时你无法使用"Back"按钮。为此,可以先专注于你的工程中的一小部分-它能够从使用这种类型的交互中受益。例如,你可以创建一个表单-它在用户每次输入一个输入字段或一个字母时查询一个脚本以便进行实时校验。你可以创建一个拖放页面-在释放一项时,它能够把数据发送到一个脚本中并把该页面的状态保存到一个数据库中。使用AJAX的理由毫无疑问是存在的;并且这种使用无论对开发者还是用户都会带来益处;这全依赖于具体的条件和执行情况。
还有其它方法可用来解决"Back"按钮的问题,例如使用Google Gmail-它现在能够为你的操作提供一种撤消功能而不刷新该页面。以后还会出现许多更具创造性的例子-它们将通过提供给开发者创建独特实时的体验的手段给用户带来更大的好处。
九、 结论
尽管AJAX允许我们构建新的和改进的方式来与一个WEB页面进行交互;但是作为开发者,我们需要牢记产品是不考虑技术的;它关心的是用户以及其如何与用户进行交互。没有了用户群,我们构建的工程毫无用处。基于这个标准,我们就能评估应该使用什么技术以及何时使用它们来创建对相应用户有用的应用软件。
作者: Jonathan Fenocchi
时间:2005.10.25
译者:Sheneyan
英文原文:
http://webreference.com/programming/javascript/jf/column12/index.html
在这个关于AJAX系列的第三部分中,我们将学习如何使用AJAX与服务端进行写作以及这些技术如何产生强大的web应用程序。如果你对学习如何构建类似GMail或者Google Maps的web程序感兴趣的话,这是一篇基础的入门(虽然那两个东东会比我们在这篇文章中提及的内容复杂的多)。在这篇文章中,我使用PHP作为服务端语言,但AJAX能够和任何服务端语言进行很好的兼容,所以你尽可以选择你所钟爱的任何语言!
我们还是从我们上一篇文章的代码(喏,就在上面)开始我们的学习,你可以去阅读它来作为参考。
这里就是这个HTML页面(带js):
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01//EN"
"http://www.w3.org/TR/html4/strict.dtd">
<html lang="zh-cn" dir="ltr">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=iso-8859-1">
<title>如何使用ajax开发web应用程序--示例</title>
<script type="text/javascript"><!--
function ajaxRead(file){
var xmlObj = null;
if(window.XMLHttpRequest){
xmlObj = new XMLHttpRequest();
} else if(window.ActiveXObject){
xmlObj = new ActiveXObject("Microsoft.XMLHTTP");
} else {
return;
}
xmlObj.onreadystatechange = function(){
if(xmlObj.readyState == 4){
processXML(xmlObj.responseXML);
}
}
xmlObj.open ('GET', file, true);
xmlObj.send ('');
}
function processXML(obj){
var dataArray = obj.getElementsByTagName('pets')[0].childNodes;
var dataArrayLen = dataArray.length;
var insertData = '<table><tr><th>'
+ 'Pets</th><th>Tasks</th></tr>';
for (var i=0; i<dataArrayLen; i++){
if(dataArray[i].tagName){
insertData += '<tr><td>' + dataArray[i].tagName + '</td>'
+ '<td>' + dataArray[i].getAttribute('tasks') + '</td></tr>';
}
}
insertData += '</table>';
document.getElementById ('dataArea').innerHTML = insertData;
}
//--></script>
<style type="text/css"><!--
table, tr, th, td {
border: solid 1px #000;
border-collapse: collapse;
padding: 5px;
}
--></style>
</head>
<body>
<h1>使用Ajax开发web应用程序</h1>
<p>这个页面演示了AJAX技术如何通过动态读取一个远程文件来更新一个网页的内容--不需要任何网页的重新加载。注意:这个例子对于禁止js的用户来说没有效果。</p>
<p>这个页面将演示如从取回并处理成组的XML数据。被取回的数据将会以表格形式输出到底下。
<a href="#" onclick="ajaxRead('data_3.php'); return false">查看演示</a>.</p>
<div id="dataArea"></div>
</body>
</html>
(sheneyan注:示例见 example_3.html )
注意:这里唯一的变化就是我们将我们的ajaxRead()中的“data_2.xml”改成了“data_3.php”。这是因为我们将使用php来输出XML(如果你在你的浏览器里打开这个PHP文件,它会以一个XML文件的形式展现出来--我们只是要在这个文件中进行操作而不只是一个简单的XML)。这个PHP文件的输出类似:
<?xml version="1.0" encoding="UTF-8"?>
<data>
<pets>
<猫 tasks="喂食, 饮水, 抓跳蚤" />
<狗 tasks="喂食, 饮水, 带出去遛遛" />
<鱼 tasks="喂食, 检查氧气,水的纯度,其它" />
</pets>
</data>
(Sheneyan注:示例就不提供了,参考底下说明即可。)
这只是输出结果,我们准备从一个mysql数据库中获取这些信息。从现在起,我们可以直接在我们的数据库中修改数据而不是手动修改XML文件。用AJAX通过PHP来取得数据,并将它获取到一个页面上--所有这些,仍然不需要重新加载网页。
第一步是连接到mysql去获取数据。这篇文章的重点在javascript,所以我不会解释下面的代码如何工作,你需要自己去了解如何连接mysql数据库。
<?php
$user = "admin";
$pass = "adminpass";
$host = "localhost";
$conn = mysql_connect($host, $user, $pass) or die("Unable to connect to MySQL.");
$db = mysql_select_db("pets",$conn) or die("Could not select the database.");
mysql_close($db);
?>
只要你连接了数据库,你可以通过底下的查询来获取信息:
<?php
$user = "admin";
$pass = "adminpass";
$host = "localhost";
$conn = mysql_connect($host, $user, $pass) or die("Unable to connect to MySQL.");
$db = mysql_select_db("pets",$conn) or die("Could not select the database.");
$result = mysql_query("SELECT * FROM `pets`");
if(mysql_num_rows ($result) == 0){
die ('Error: no data found in the database.');
}
while ($row = mysql_fetch_assoc($result)){
echo 'Pet: '.$row['pet'].', tasks: '.$row['tasks'].'. ';
}
mysql_close($db);
?>
这段代码给了你需要的信息,但它输出并不正确。我们需要修改这PHP代码来分隔数据为XML,而不是纯文本。为了实现这个目标我们得作几个修改。
<?php
header('Content-Type: text/xml');//编号1
echo '<?xml version="1.0" encoding="UTF-8"?>';//编号2
echo "\n<data>\n<pets>\n";//编号3
$user = "admin";
$pass = "adminpass";
$host = "localhost";
$conn = mysql_connect($host, $user, $pass) or die("无法连接mysql.");
$db = mysql_select_db("pets",$conn) or die("无法选择数据库.");
$result = mysql_query("SELECT * FROM `pets`");
if(mysql_num_rows ($result) == 0){
die ('Error: 数据库没有数据.');
}
while ($row = mysql_fetch_assoc($result)){
echo '<'.$row['pet'].' tasks="'.$row['tasks'].'" />'."\n";//编号4
}
echo "</pets>\n</data>";//编号5
mysql_close($db);
?>
让我们从上面开始,一次一行的来分析它是如何输出XML的.我给每一行都加了注释标记以便于更好的对应理解(原文是I've color-coded each line to make it easier to understand,我懒得上色,就改成用编号了)
编号1:这部分代码发送一个http头来让用户客户端明白这个php文件输出的是一个XML。这就是为什么你在你的浏览器里看这个文档的时候它以一个XML文件的形式展现,即使你的文件有一个“.php”后缀。
编号2:这部分的代码输出了XML声明。这是我之前展示给你看的XML的第一行。
编号3:这部分的代码输出的最开始的两个标签:我们的根标签,<data>和我们用来放置所有宠物的<pets>标签。
编号4:这部分的代码最困难的。这里包含了一个循环用来遍历你数据库里所有的数据。每次循环,它会输出一个新的节点,这个节点用每一种动物作为标签名以及一个"任务"属性。例如,如果你数据库中的第一只宠物是“猫”而且它相应的任务字段是“喂食, 饮水, 抓跳蚤”,那php将输出在XML文档中输出 <猫 tasks="喂食, 饮水, 抓跳蚤" /> 。这个“\n” 部分只是在结尾插入一个新行,保证这个XML代码不至于都在同一行。
编号5:这部分的代码结束了 我们开始时打开的</pets> 和 </data> 节点。因为XML必须是格式良好的(well-formed),所以我们必须认真对待这部分以确认我们的程序能够正确运行。
现在我们已经让PHP输出XML了,我们现在所要作的就是登录我们的mysql数据库,并进行我们所需要的修改,来更新这个XML。很酷,不是吗?我们仍然能够使用上一篇文章中的js脚本来获取代码,因为XML输出和之前的完全一样。
结论
你可以再进一步的扩展,使用XML来保存和获取数据。换句话说,你能够使用php来写你的XML文件,然后让javascript来读。用ajax,你也能够定时的检查xml文件是否已经更改而且,如果XML已经更新,也可以更新本页面。
关于作者
Jonathan Fenocchi(mail:jona#slightlyremarkable.com #换成@)是一个网络开发者,主攻web设计,客户端脚本,php脚本。
他的网站位于:http://www.slightlyremarkable.com
作者: Jonathan Fenocchi
时间:2005.10.26
译者:Sheneyan
英文原文:
http://www.webreference.com/programming/javascript/jf/column13/
在上一篇文章中,我们讨论了如何通过javascript从一个远程XML文件中取得数据。在这篇文章中,我们将学会怎样对数据作更复杂的处理。作为一个示例,我们会准备一组XML数据,将数据分割成独立的片断并以不同的方式展示这些片断(取决于它们是如何被标识的)。
这篇文章是建立在上一篇文章中构造的示例代码的基础之上,所以如果你不能理解我们现在的代码,你可以回过头去读第一篇文章(sheneyan注:就在上面)。
开始~
让我们开始我们的第一步:构造XML。我们准备写一个XML文档,它组织了一系列准备让javascript处理的数据,所以我们将一起组织一些节点和子节点(或者,元素和子元素)。在这个例子里,我们将使用一些家庭宠物的名字:
<?xml version="1.0" encoding="UTF-8"?>
<data>
<pets>
<pet>猫</pet>
<pet>狗</pet>
<pet>鱼</pet>
</pets>
</data>
在上面,我们有这个XML声明(标明这个文档是一个XML 1.0 文档,使用UTF-8编码),一个根元素(<data>)将下面所有的元素组合在一起,一个<pets>元素组织了所有的宠物,然后一个<pet>节点对应一只宠物。为了指定每一只宠物是什么类型的动物,我们在<pet>元素中设置了文本节点:猫,狗,鱼。
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01//EN"
"http://www.w3.org/TR/html4/strict.dtd">
<html lang="zh" dir="ltr">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=gb2312">
<title>使用Ajax开发Web应用程序 - 示例</title>
<script type="text/javascript"><!--
function ajaxRead(file){
var xmlObj = null;
if(window.XMLHttpRequest){
xmlObj = new XMLHttpRequest();
} else if(window.ActiveXObject){
xmlObj = new ActiveXObject("Microsoft.XMLHTTP");
} else {
return;
}
xmlObj.onreadystatechange = function(){
if(xmlObj.readyState == 4){
processXML(xmlObj.responseXML);
}
}
xmlObj.open ('GET', file, true);
xmlObj.send ('');
}
function processXML(obj){
var dataArray = obj.getElementsByTagName('pet');
var dataArrayLen = dataArray.length;
var insertData = '<table style="width:150px; border: solid 1px #000"><tr><th>'
+ 'Pets</th></tr>';
for (var i=0; i<dataArrayLen; i++){
insertData += '<tr><td>' + dataArray[i].firstChild.data + '</td></tr>';
}
insertData += '</table>';
document.getElementById ('dataArea').innerHTML = insertData;
}
//--></script>
</head>
<body>
<h1>使用Ajax开发web应用程序</h1>
<p>这个页面演示了AJAX技术如何通过动态读取一个远程文件来更新一个网页的内容--不需要任何网页的重新加载。注意:这个例子对于禁止js的用户来说没有效果。</p>
<p>这个页面将演示如从取回并处理成组的XML数据。被取回的数据将会以表格形式输出到底下。
<a href="#" onclick="ajaxRead('data_2.xml'); return false">查看演示</a>.</p>
<div id="dataArea"></div>
</body>
</html>
(Sheneyan注:完整代码示例见 example_2.html ,XML文件见:data_2.xml)
你会注意到我们和上次一样以同样的方式(通过一个超链接)调用了这个函数,而且我们将数据放入一个DIV(这次这个东东叫做“dataArea”)。这个ajaxRead()函数和上次很接近,除了一点不同:onreadystatechange函数。让我们先看一下这个函数:
xmlObj.onreadystatechange = function(){
if(xmlObj.readyState == 4){
processXML(xmlObj.responseXML);
}
}
我们取消了updateObj函数并用一个叫做processXML()的新函数来代替它。这个函数将得到XML文档本身(也就是被ajaxRead函数取回的)并处理它。(这“XML文档本身”我指的是参数“xmlObj.responseXML”)
现在让我们分析一下这个函数processXML。下面是它的代码:
function processXML(obj){
var dataArray = obj.getElementsByTagName('pet');
var dataArrayLen = dataArray.length;
var insertData = '<table style="width:150px; border: solid 1px #000"><tr><th>'
+ 'Pets</th></tr>';
for (var i=0; i<dataArrayLen; i++){
insertData += '<tr><td>' + dataArray[i].firstChild.data + '</td></tr>';
}
insertData += '</table>';
document.getElementById ('dataArea').innerHTML = insertData;
}
首先,我们定义了一些变量。“dataArray”作为所有<pet>节点的数组(不是节点数据,只是节点)。“dataArrayLen”是这个数组的长度,用于我们的循环。“insertData”则是一个表格的开头的HTML。
我们的第二步则是遍历所有的<pet>元素(通过变量“dataArray”)并将数据添加到变量insertData中。这里我们会创建一个表格行,插入一个表格数据节点(td)进去,再将每一个<pet>元素的文本包含进这个表格数据节点,并将这些都添加进变量“insertData”。因此,每循环一次,变量insertData将添加一行包含三个宠物中之一名称的新数据。
新数据行添加完后,我们插入一个“</table>”结束标签到变量“insertData”。这完成了这个表格,然后我只剩这最后一步来达成我们的目标:我们需要将这个表格放到页面上。幸运的是,我们得感谢innerHTML属性,这很简单。我们通过函数document.getElementById()取得DIV“dataArea”并将变量“insertData”中的HTML插进去。嗯,这个表格冒出来了!
我们继续之前……
我得指出两点:
首先,你会注意到我们并没有使用节点<pets>。这事因为我们只有一个数据组(<pets>)以及后来所有的元素(每一个<pet>元素);这些子节点包含了不同的数据但它们有相同的名字。在这个例子中,这个节点能够被忽略。然而,将所有的元素<pet>放进<pets>元素还是比较好,而不是让这些<pet>元素自己散放(但仍然在data元素里面)。
另外一种方式是给每一个宠物放一个指定的标签,比如:
<?xml version="1.0" encoding="UTF-8"?>
<data>
<pets>
<猫 />
<狗 />
<鱼 />
</pets>
</data>
然后我们能够遍历元素<pets>里的节点。这个processXML函数看起来就像这样:
function processXML(obj){
var dataArray = obj.getElementsByTagName('pets')[0].childNodes;
var dataArrayLen = dataArray.length;
var insertData = '<table style="width:150px; border: solid 1px #000"><tr><th>'
+ 'Pets</th></tr>';
for (var i=0; i<dataArrayLen; i++){
if(dataArray[i].tagName){
insertData += '<tr><td>' + dataArray[i].tagName + '</td></tr>';
}
}
insertData += '</table>';
document.getElementById ('dataArea').innerHTML = insertData;
}
(Sheneyan注:修改后的示例见:example_2_1.html ,XML文件见:data_2_1.xml)
这里所作的修改就是我们指向了<pets>组元素(这个“[0]”意味这是第一个,即使它就是唯一的那一个)以及它的子节点(元素<猫 />,<狗 />,<鱼 />)。因为文本元素分割了这几个元素(空格被认为是一个节点),我们需要确定只有那些有标签名的节点(嗯,也就是只有标签)通过。然后我们输出每一个标签的名字。因为每一个标签名是一个宠物,我们不需要取得每一个节点的数据-节点名本身已经足够。去看一下它是怎么工作的吧。
还有另外一种方式来完成我们上面的工作,就是给每一个<pet>节点设置一个属性值。你的XML文档看起来就像这样:
<?xml version="1.0" encoding="UTF-8"?>
<data>
<pets>
<pet type="猫" />
<pet type="狗" />
<pet type="鱼" />
</pets>
</data>
你只需要稍微修改一下你的processXML函数,它变成这样子了:
function processXML(obj){
var dataArray = obj.getElementsByTagName('pet');
var dataArrayLen = dataArray.length;
var insertData = '<table style="width:150px; border: solid 1px #000"><tr><th>'
+ 'Pets</th></tr>';
for (var i=0; i<dataArrayLen; i++){
insertData += '<tr><td>' + dataArray[i].getAttribute('type') + '</td></tr>';
}
insertData += '</table>';
document.getElementById ('dataArea').innerHTML = insertData;
}
(Sheneyan注:修改后的示例见:example_2_2.html ,XML文件见:data_2_2.xml)
关键的不同在于我们通过dataArray[i].getAttribute('type')取得值,它返回了当前<pet>节点的“type”属性的值。
继续...
现在我们已经知道了一些从一个单独的XML数据组中取回数据的有效方法,让我们看看如何从多个组中取回数据。和只是列出一个pets所拥有的内容不同,我们假设我们有一个针对我们宠物的日课表。因为它们都有不同的需要,每一只宠物都得仔细的照顾。面对这种情况,动物的看管员需要一个每日依据。现在来让我们将这些放入一个良好格式的XML:
<?xml version="1.0" encoding="UTF-8"?>
<data>
<pets>
<pet>Cat
<task>Feed</task>
<task>Water</task>
<task>Comb out fleas</task>
</pet>
<pet>Dog
<task>Feed</task>
<task>Water</task>
<task>Put outside</task>
</pet>
<pet>Fish
<task>Feed</task>
<task>Check oxygen, water purity, etc.</task>
</pet>
</pets>
</data>
也许这个看起来很奇怪,但这就是我们正在创建的子组(sub-group)。每一个<pet>元素都是一个组<pets>的子组,而每一个<task>则是每一个<pet>组的子元素。
在我继续之前,你也许希望将你的表格用一些css美化一下,比如:
<style type="text/css"><!--
table, tr, th, td {
border: solid 1px #000;
border-collapse: collapse;
padding: 5px;
}
--></style>
这让这个表格更容易读取。现在让我们去研究函数processXML:
function processXML(obj){
var dataArray = obj.getElementsByTagName('pet');
var dataArrayLen = dataArray.length;
var subAry, subAryLen;
var insertData = '<table><tr><th>'
+ 'Pets</th><th>Tasks</th></tr>';
for (var i=0; i<dataArrayLen; i++){
insertData += '<tr><td>' + dataArray[i].firstChild.data + '</td>';
subAry = dataArray[i].getElementsByTagName('task');
subAryLen = subAry.length;
insertData += '<td>';
for(var j=0; j<subAryLen; j++){
insertData += subAry[j].firstChild.data;
if( subAryLen != j+1 ) { insertData += ', '; }
}
insertData += '</td></tr>';
}
insertData += '</table>';
document.getElementById ('dataArea').innerHTML = insertData;
}
(Sheneyan注:修改后的示例见:example_2_3.html ,XML文件见:data_2_3.xml)
新增加的内容,首先是两个新变量的声明:“subAry”和“subAryLen”。它们和之前的变量“dataArray”和“dataArrayLen”类似,除了它们指向不同的数组(特别是它们将指向那些“task”元素-当“dataArray”和“dataArrayLen”指向“pet”元素的时候)。
我们也改变了变量“insertData”的初始值-我们增加了一个表格头(<th>)给我们的“tasks”字段。
下一步改变在于循环:我们把值赋给subAry和subAryLen变量。变量subAry成为当前<pet>的<task>元素的数组。变量subAryLen成为这个数组的长度,直到这个数组发生变化(当外部循环走到下一个<pet>时)。
我们创建了一个内嵌的循环来处理所有的<task>元素,一次一个。大概来说,我们创建一个新的数据格,放进一个用逗号分隔的任务列表,然后关闭数据表格以及当前行。尤其,这些<task>元素节点数据(任务本身,比如,“喂食”)放置入变量“insertData”里的数据格。
接下来,我们检验当前<pet>是否有其它更多的task。如果还有,我们增加一个逗号(,)到变量insertData来让每一个任务使用一个逗号分隔(“a, b, c”,而不是“a, b, c,”-注意,最后一个逗号在第二个任务那里,所以我们不需要)。这个工作在我们取得subAry数组长度的时候(给循环的“j”变量加1)就完成了。因为这个循环会在下一个循环的时候把变量“j”递增1,“j”会比它这次检验时还多1。因此,如果“j+1”(或者,“当循环再次开始的时候j的值”)等于subAryLen(当前<pet>节点的<task>节点数目),这个循环将停止。如果循环不再运行,我们就不再添加新的逗号来分隔任务。所以如果“j+1”不等于subAryLen,我们直到我们可以安全的加入逗号到“insertData”,为下一个<task>作准备。
一旦内循环结束,我们关闭task数据格以及pet行。外部循环会重新开始创建一个新行以及移动到下一个<pet>。这个处理一直进行到所有的<pet>元素(以及每一个pet的所有<task>元素)都被处理完。
有其他方法吗?
你也许会想:“那javascript变得相当复杂了,但它只会随着XML越来越复杂而跟着变复杂,也许我们能够简化XML,然后,简化javascript”。如果你这么想,很棒,因为你完全正确。我之前展示的不同方法之一,我详细说明的那个也许能够成为最合适的。我们怎么使用属性来对应每一只宠物以及相应任务?XML看起来会变成怎样?
<?xml version="1.0" encoding="UTF-8"?>
<data>
<pets>
<pet type="Cat" tasks="Feed, Water, Comb out fleas" />
<pet type="Dog" tasks="Feed, Water, Put outside" />
<pet type="Fish" tasks="Feed, Check oxygen, water purity, etc." />
</pets>
</data>
哇哦!看起来简单多了。让我们看看我们的processXML函数如何修改:
function processXML(obj){
var dataArray = obj.getElementsByTagName('pet');
var dataArrayLen = dataArray.length;
var insertData = '<table><tr><th>'
+ 'Pets</th><th>Tasks</th></tr>';
for (var i=0; i<dataArrayLen; i++){
insertData += '<tr><td>' + dataArray[i].getAttribute('type') + '</td>'
+ '<td>' + dataArray[i].getAttribute('tasks') + '</td></tr>';
}
insertData += '</table>';
document.getElementById ('dataArea').innerHTML = insertData;
}
(Sheneyan注:修改后的示例见:example_2_4.html,XML文件见:data_2_4.xml)
就像你猜的一样,函数简单多了。因为代码变得简单,它也会变得更有效率。和我们比较老的函数的唯一的不同在于这个变量insertData现在插入更多的HTML,尤其是两个新变量“type”和“tasks”。就如我们较早之前所学的,那些属性是我们从XML文档的<pet>元素中取得的,而且每个pet的属性都有不同的值。对于你自己修改这个XML文件以适应你的进度的变动来说也许是最简单的方法。例如,如果你最终把你的猫身上的跳蚤抓光了,你只要简单从你的猫的每日任务表中把“减少跳蚤数量”删除,然而在之前我们使用的XML中,实现起来也许会觉得糊里糊涂。
最后的XML格式化的方法是将两部分混合。现在,我们将使用属性和不同的标签。让我们看一下示例XML:
<?xml version="1.0" encoding="UTF-8"?>
<data>
<pets>
<猫 tasks="喂食, 饮水, 减少跳蚤数量" />
<狗 tasks="喂食, 饮水, 带出去遛遛" />
<鱼 tasks="喂食, 检查氧气,水的纯度,其它" />
</pets>
</data>
这也许是最便于理解的XML。让我们分析一下我们为了让processXML函数运作起来所作的变更:
function processXML(obj){
var dataArray = obj.getElementsByTagName('pets')[0].childNodes;
var dataArrayLen = dataArray.length;
var insertData = '<table><tr><th>'
+ 'Pets</th><th>Tasks</th></tr>';
for (var i=0; i<dataArrayLen; i++){
if(dataArray[i].tagName){
insertData += '<tr><td>' + dataArray[i].tagName + '</td>'
+ '<td>' + dataArray[i].getAttribute('tasks') + '</td></tr>';
}
}
insertData += '</table>';
document.getElementById ('dataArea').innerHTML = insertData;
}
(Sheneyan注:修改后的示例见:example_2_5.html,XML文件见:data_2_5.xml)
“dataArray”现在指向了<pets>的子节点,将它们作为一个数组对待(换句话说,dataArray现在是在<pets>节点内所有节点的数组)。这事因为每一个标签都不同(<猫 />,<狗 />,<鱼 />),所以我们不能使用这些元素的名称来搜索它们(而之前我们可以使用<pet>,因为所有的元素都是<pet>)。
还是一样,每个节点之间的有空格,所以在我们的处理过程中得排除掉文本节点。我们能够检验标签名是否存在-文本节点是节点但没有标签,而<猫 />,<狗 />,<鱼 />节点都是标签。所以如果一个标签有名字,那我们能够将数据插入变量insertData。我们插入的数据是一个表格并有两个表格数据格。这第一个单元格是标签名,也就是宠物的类型(猫,狗或鱼),而第二个单元格则是指定动物的“tasks”属性值(比如“喂食或饮水”)。
结束语
在这篇文章里,我演示了这个例子的很多变化,你可以随意试验它们来检验哪个更适合你。只要记住一点,XML是“可扩展的”,所以没有“错误的”方法来组合你的数据,虽然经常有一个“最好的”方法。而且,要注意让你的XML保持格式良好。记住很多问题来自于忘记结束一个标签(比如<狗 />而不是<狗>;除非这个节点中有数据,比如下面的<狗>这里有数据哦</狗>)。
我意图使XML和javascript的应用不糊涂而变得明朗。一步步的学习处理更多的数据,你能够将ajax运用于更大的用途。我希望看到ajax更多的应用于企业网站,及其它。所以如果你将这些知识应用于实践,我很高兴了解到你学到了什么(mail:jona#slightlyremarkable.com #换成@)。
关于作者
Jonathan Fenocchi(mail:jona#slightlyremarkable.com #换成@)是一个网络开发者,主攻web设计,客户端脚本,php脚本。
他的网站位于http://www.slightlyremarkable.com
作者: Jonathan Fenocchi
时间:2005.10.25
译者:Sheneyan
英文原文:
http://webreference.com/programming/javascript/jf/column12/index.html
在过去,由于为了获得新数据而不得不重新加载web页面(或者加载其他页面)导致web应用程序发展被限制。虽然有其他方法可用(不加载其他页面),但是这些技术都没有被很好地支持而且有bug成灾的趋向。在过去的几个月里,一个过去并不被广泛支持的技术已经被越来越多的web冲浪者(web surfers??是指浏览器还是浏览者?)所接受,它给了开发者更多的自由开发先进的web应用程序。这些通过javascript来异步取得xml数据的应用程序,被亲切的称为“Ajax应用程序”(Asynchronous Javascript and XML applications)。在这篇文章中,我将会解释如何通过Ajax来取回一个远程的XML文件并更新一个web page,并且随着这个系列的继续,我将讨论更多的方法,使用ajax技术将你的web应用程序提升到一个新的层次.
这第一步就是创建一个带一些数据的XML文件。我们将这个文件命名为data.xml。它是一个简单的XML文件,而在一个真实的程序中,它会复杂许多,但对于我们的例子来说,简单明了是最合适地。
<?xml version="1.0" encoding="UTF-8"?> <root> <data> 这是一些示例数据,它被保存在一个XML文件中,并被JavaScript取回。 </data> </root>
现在让我们创建一个简单的web页面包含一些示例数据。这个页面将是我们的js脚本所在,并且这个页面将会让用户们访问柄看到Ajax脚本的运行。我们把它命名为ajax.html
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01//EN"
"http://www.w3.org/TR/html4/strict.dtd">
<html lang="zh" dir="ltr">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=gb2312">
<title>使用ajax开发web应用程序 - 示例</title>
</head>
<body>
<h1>使用ajax开发web应用程序</h1>
<p>这个页面演示了AJAX技术如何通过动态读取一个远程文件来更新一个网页的内容--不需要任何网页的重新加载。注意:这个例子对于禁止js的用户来说没有效果。</p>
<p id="xmlObj">
这是一些示例数据,它是这个网页的默认数据 <a href="data.xml"
title="查看这个XML数据." onclick="ajaxRead('data.xml'); this.style.display='none'; return false">查看XML数据.</a>
</p>
</body>
</html>
注意,对于那些没有javascript的用户,我们直接链接到data.xml文件。对于那些允许运行javascript的用户,函数“ajaxRead”将被运行,这个链接被隐藏,并不会被转向到那个data.xml文件。函数“ajaxRead”现在还没定义。所以如果你要检验上面的示例代码,你会得到一个javascript错误。让我们继续并定义这个函数(还有其他的),让你能够看到ajax是如何工作的,下面的脚本要放到你的head标签里:
<script type="text/javascript"><!--
function ajaxRead(file){
var xmlObj = null;
if(window.XMLHttpRequest){
xmlObj = new XMLHttpRequest();
} else if(window.ActiveXObject){
xmlObj = new ActiveXObject("Microsoft.XMLHTTP");
} else {
return;
}
xmlObj.onreadystatechange = function(){
if(xmlObj.readyState == 4){
updateObj('xmlObj', xmlObj.responseXML.getElementsByTagName('data')[0].firstChild.data);
}
}
xmlObj.open ('GET', file, true);
xmlObj.send ('');
}
function updateObj(obj, data){
document.getElementById(obj).firstChild.data = data;
}
//--></script>
(Sheneyan注:完整代码示例见 example.html ML文件见:data.xml )
这堆代码有点多,让我们一点点的进行。第一个函数叫做“ajaxRead”-也就是我们在页面的“查看XML数据”链接中调用的函数,我们定义了一个“xmlObj”变量-这将作为客户端(用户正在查看的这个web页面)以及服务端(web站点本身)之间的中间件。我们在一个if/else块中定义这个对象:
if(window.XMLHttpRequest){
xmlObj = new XMLHttpRequest();
} else if(window.ActiveXObject){
xmlObj = new ActiveXObject("Microsoft.XMLHTTP");
} else {
return;
}
这只是一个对不同对象是否可用的测试-某些浏览器实现了不同的XMLHttpRequest对象,所以当我们定义“xmlObj”作为我们的XMLHttpRequest对象时,我们不得不根据浏览器所实现的来定义它。如果没有可用的XMLHttpRequest对象,我们将执行“return”语句结束这个函数以避免脚本错误。在大部分情况下,这个检验将返回一个XMLHttpRequest对象-这部分代码应该能够在绝大部分的浏览器上工作,除了少部分比较老的浏览器的异常情况(它能够工作在ie5.01上,但是在netscape4上会使函数终止)。
接下来是这些代码块:
xmlObj.onreadystatechange = function(){
if(xmlObj.readyState == 4){
updateObj('xmlObj', xmlObj.responseXML.getElementsByTagName('data')[0].firstChild.data);
}
}
每次XMLHttpRequest的状态发生变化,事件“onreadystatechange”就会被触发。通过使用“xmlObj.onreadystatechange = function(){...}”我们能够创建一个函数并让它在这个XMLHttpRequest对象的状态每次发生改变的时候立刻运行。这里总共有五个状态,由0走到4。
0 – 尚未初始化(在这个XMLHttpRequest开始前)
1 – 加载(XMLHttpRequest初始化一结束)
2 – 加载结束(XMLHttpRequest一从服务器上获得一个回应)
3 – 交互(当XMLHttpRequest对象和服务器连接中)
4 – 结束(当XMLHttpRequest被告知它已经完成了所有人物并结束运行)
这第五个状态(数字4)就是我们能够确定数据已经可用的标志,所以我们检验这个xmlObj.readyState是否等于“4”来确定数据是否可用,如果是4,我们运行updateObj函数。这个函数带两个参数:一个当前web页面的元素ID(当前web页面中要更新的元素)以及用于填充这个元素的数据。这个函数的运行方式在稍后将更详细地解释。
我们的web页面的p元素有一个id“xmlData”,这就是我们准备更新的段落。我们正在取得的数据来自于XML文件,但它有点复杂。这里是它如何工作的原理。
xmlObj.responseXML属性是一个DOM对象 - 它很象“document”对象,除了它来自远程的XML文件。换句话说,如果你在data.xml中运行脚本,那xmlObj.responseXML就是一个“document”对象。因为我们知道这些,我们能够通过“getElementsByTagName”方法取得任何XML节点。数据包含在一个命名为“<data>”的XML节点中,所以我们的任务很简单:取得第一个(而且只有这一个)数据节点。因而,xmlObject.responseXML.getElementsByTagName("data")[0]返回XML文件中的第一个<data>节点。
注意:它返回的是XML节点,而不是节点中的数据-这个数据必须通过访问XML节点的属性取得,这就是下一步要说的。
接下来,取得数据只需要简单的指定“firstChild.data”(firstChild指向了那个被<data>节点包含的文本节点,而这个“data”属性则是这个文本节点的实际文本)。
xmlObj.open ('GET', file, true);
xmlObj.send ('');
这是我们的ajaxRead函数的最后一个部分。它说了些什么?嗯,xmlObj的这个“open”方法打开了一个到服务器(通过一个指定的协议,这里指定的是“GET”-你可以使用“USE”或者其他别的协议)的连接,去请求一个文件(在我们的例子里,变量“file”被作为一个参数赋给ajaxRead函数-data.xml),而且javascript可以同步(false)或者异步(true,默认值)的处理请求。由于这是异步的Javascript和XML(AJAX),我们将使用默认的异步方式-在这个例子中,使用同步方式将不起作用。
这是我们函数中的最后一行,它简单的发送一个空字符串回服务器。如果没有这行,xmlObj的readyState永远不会到4,所以你的页面永远不会更新。这个send方法能够用于作其他事情,但今天我只是用来从服务器上取得数据-并不发送它-所以在这篇文章中我不准备介入任何关于send方法的细节。
function updateObj(obj, data){
document.getElementById(obj).firstChild.data = data;
}
现在再稍微解释一下updateObj函数:这个函数使用一个新的值来更新当前页面上任何指定的元素。他的第一个参数,“obj”是当前页面中元素的ID-那个要被更新的对象;它的第二个参数,“data”是用来将那个将被替换值的对象(“obj”)的内容替换掉。一般来说,检验一下并确定当前页面上确实有一个元素的ID是“obj”是比较明智的,但对我们的脚本的这个隔离级别来说校验并不必要。这个函数更新的方式和我们之前从XML文件的“data”节点取得数据的方式类似-它定位它要更新的元素(这时候这个元素的ID代替了它的标签名和在页面中的索引)并设置这个元素的第一个子节点(文本节点)的data属性为新的值。如果你需要使用HTML而不是纯文本来更新一个元素,你也可以使用
document.getElementById(obj).innerHTML = data
这就是全部了
这个概念很简单,而且代码也不是很难。你能够从某个地方读取一个文件并且不需要重新加载这个web页面。你有足够的灵活性来作各种事情,包括从表单发送数据(不需要重新加载web页面)并且使用一个服务端语言来动态生成XML文件。如果你需要更近一步,记得这个连接是很有用的-哦,还要记得Google是你朋友。在另外的文章中,我将解释你如何配合服务端技术使用AJAX来构造强大的web应用程序。
关于作者
Jonathan Fenocchi(mail:jona#slightlyremarkable.com #换成@)是一个网络开发者,主攻web设计,客户端脚本,php脚本。
他的网站位于:http://www.slightlyremarkable.com
请尝试Michael Schwarz的AJAX .NET包装器,通过它ASP.NET开发人员可以快速方便的部署很容易利用AJAX功能的页面。需要注意的是,这个包装器处于初期开发阶段,因此还没有完全成熟。
然而,AJAX这样的技术很可能破坏分层体系结构(N-Tier)。我的看法是,AJAX增加了表示逻辑层(甚至更糟,业务层)渗透到表示层的可能性。像我这样严肃的架构师对这种想法可能畏步不前。我感到AJAX的使用即便稍微越过了层次边界,这种代价也是值得深思的。当然,这要视具体的项目和环境而定。
起步
它是如何工作的——概述
AJAX依靠代理(broker)指派和处理往返服务器的请求。对此,.NET包装器依靠客户端XmlHttpRequest对象。多数浏览器都支持XmlHttpRequest对象,这就是选择它的原因。因为包装器的目的是隐藏XmlHttpRequest的实现,我们就不再详细讨论它了。
包装器本身通过将.NET函数标记为AJAX方法来工作。标记之后,AJAX就创建对应的javascript函数,这些函数(和任何javascript函数一样)作为代理可以在客户端使用XmlHttpRequest调用。这些代理再映射回服务器端函数。
复杂吗?并不复杂。我们来看一个例子。假设有一个.NET函数:
public int Add(int firstNumber, int secondNumber)
{
return firstNumber + secondNumber;
}
Ajax .NET包装器将自动创建名为“Add”、带有两个参数的javascript函数。使用javascript(在客户机上)调用该函数时,请求将传递给服务器并把结果返回给客户机。
初始设置
我们首先介绍“安装”项目中使用的.dll的步骤。如果您很清楚如何添加.dll文件引用,可以跳过这一节。
首先,如果还没有的话,请下载最新的AJAX版本。解压下载的文件并把Ajax.dll放到项目的引用文件夹中。在Visual Studio.NET中有机Solution Explorer的“References(引用)”节点并选择Add Reference(添加引用)。在打开的对话框中,单击Browse(浏览)并找到ref/Ajax.dll文件。依次单击Open(打开)和Ok(确认)。这样就可以用AJAX .NET包装器编程了。
建立HttpHandler
为了保证正常工作,第一步是在web.config中设置包装器的HttpHandler。不需要详细解释HttpHandlers是什么及其如何工作,只要知道它们用于处理ASP.NET请求就足够了。比如,所有*.aspx页面请求都由System.Web.UI.PageHandlerFactory类处理。类似的,我们让所有对 Ajax/*.ashx的请求由Ajax.PageHandlerFactory处理:
<configuration>
<system.web>
<httpHandlers>
<add verb="POST,GET" path="Ajax/*.ashx"
type="Ajax.PageHandlerFactory, Ajax" />
</httpHandlers>
...
<system.web>
</configuration>
简言之,上面的代码告诉ASP.NET,和指定路径(Ajax/*.ashx)匹配的任何请求都由 Ajax.PageHandlerFactory而不是默认处理程序工厂来处理。不需要创建Ajax子目录,使用这个神秘的目录只是为了让其他 HttpHandlers能够在自己建立的子目录中使用.ashx扩展。
建立页面
现在我们可以开始编码了。创建一个新页面或者打开已有的页面,在file后的代码中,为Page_Load事件添加以下代码:
public class Index : System.Web.UI.Page{
private void Page_Load(object sender, EventArgs e){
Ajax.Utility.RegisterTypeForAjax(typeof(Index));
//...
}
//...
}
调用RegisterTypeForAjax将在页面上引发后面的javascript(或者在页面中手工加入以下两行代码):
<script language="javascript" src="Ajax/common.ashx"></script>
<script language="javascript"
src="Ajax/Namespace.PageClass,AssemblyName.ashx"></script>
其中最后一行的含义是:
Namespace.PageClass——当前页面的名称空间和类(通常是@Page指令中Inherits属性的值)
AssemblyName——当前页面所属程序集的名称(通常就是项目名)
下面是AjaxPlay项目中sample.aspx页面的结果例子:
<%@ Page Inherits="AjaxPlay.Sample" Codebehind="sample.aspx.cs" ... %>
<html>
<head>
<script language="javascript" src="Ajax/common.ashx"></script>
<script language="javascript"
src="Ajax/AjaxPlay.Sample,AjaxPlay.ashx"></script>
</head>
<body>
<form id="Form1" method="post" runat="server">
...
</form>
</body>
</html>
可以在浏览器中手工导航到src路径(查看源代码,复制粘贴路径)检查是否一切正常。如果两个路径都输出一些(似乎)毫无意义的文本,就万事大吉了。如果什么也没输出或者出现ASP.NET错误,则表明有些地方出现问题。
即便不知道HttpHandlers如何工作,上面的例子也很容易理解。通过web.config,我们已经保证所有对Ajax/*.ashx的请求都由自定义的处理程序处理。显然,这里的两个脚本标签将由自定义的处理程序处理。
创建服务器端函数
现在来创建可从客户端调用中异步访问的服务器端函数。因为目前还不支持所有的返回类型(不用担心,将在目前的基础上开发新的版本),我们继续使用简单的ServerSideAdd函数吧。在file后的代码中,向页面添加下列代码:
[Ajax.AjaxMethod()]
public int ServerSideAdd(int firstNumber, int secondNumber)
{
return firstNumber + secondNumber;
}
要注意,这些函数具有Ajax.AjaxMethod属性集。该属性告诉包装器这些方法创建javascript代理,以便在客户端调用。
客户端调用
最后一步是用javascript调用该函数。AJAX包装器负责创建带有两个参数的javascript函数Sample.ServerSideAdd。对这种最简单的函数,只需要调用该方法并传递两个数字:
<%@ Page Inherits="AjaxPlay.Sample" Codebehind="sample.aspx.cs" ... %>
<html>
<head>
<script language="javascript" src="Ajax/common.ashx"></script>
<script language="javascript"
src="Ajax/AjaxPlay.Sample,AjaxPlay.ashx"></script>
</head>
<body>
<form id="Form1" method="post" runat="server">
<script language="javascript">
var response = Sample.ServerSideAdd(100,99);
alert(response.value);
</script>
</form>
</body>
</html>
当然,我们不希望仅仅用这种强大的能力来警告用户。这就是所有客户端代理(如javascript Sample.ServerSideAd函数)还接受其他特性的原因。这种特性就是为了处理响应而调用的回调函数:
Sample.ServerSideAdd(100,99, ServerSideAdd_CallBack);
function ServerSideAdd_CallBack(response){
if (response.error != null){
alert(response.error);
return;
}
alert(response.value);
}
从上述代码中可以看到我们指定了另外一个参数。ServerSideAdd_CallBack(同样参见上述代码)是用于处理服务器响应的客户端函数。这个回调函数接收一个响应对象,该对象公开了三个主要性质
Value——服务器端函数实际返回的值(无论是字符串、自定义对象还是数据集)。
Error——错误消息,如果有的话。
Request——xml http请求的原始响应。
Context——上下文对象。
首先我们检查error只看看是否出现了错误。通过在服务器端函数中抛出异常,可以很容易处理error特性。在这个简化的例子中,然后用这个值警告用户。Request特性可用于获得更多信息。
处理类型
返回复杂类型
Ajax包装器不仅能处理ServerSideAdd函数所返回的整数。它目前还支持integers、 strings、double、booleans、DateTime、DataSets和DataTables,以及自定义类和数组等基本类型。其他所有类型都返回它们的ToString值。
返回的DataSets和真正的.NET DataSet差不多。假设一个服务器端函数返回DataSet,我们可以通过下面的代码在客户端显示其中的内容:
<script language="javascript">
//Asynchronous call to the mythical "GetDataSet" server-side function
function getDataSet(){
AjaxFunctions.GetDataSet(GetDataSet_callback);
}
function GetDataSet_callback(response){
var ds = response.value;
if(ds != null && typeof(ds) == "object" && ds.Tables != null){
var s = new Array();
s[s.length] = "<table border=1>";
for(var i=0; i<ds.Tables[0].Rows.length; i++){
s[s.length] = "<tr>";
s[s.length] = "<td>" + ds.Tables[0].Rows[i].FirstName + "</td>";
s[s.length] = "<td>" + ds.Tables[0].Rows[i].Birthday + "</td>";
s[s.length] = "</tr>";
}
s[s.length] = "</table>";
tableDisplay.innerHTML = s.join("");
}
else {
alert("Error. [3001] " + response.request.responseText);
}
}
</script>
Ajax还可以返回自定义类,唯一的要求是必须用Serializable属性标记。假设有如下的类:
[Serializable()]
public class User{
private int _userId;
private string _firstName;
private string _lastName;
public int userId{
get { return _userId; }
}
public string FirstName{
get { return _firstName; }
}
public string LastName{
get { return _lastName; }
}
public User(int _userId, string _firstName, string _lastName){
this._userId = _userId;
this._firstName = _firstName;
this._lastName = _lastName;
}
public User(){}
[AjaxMethod()]
public static User GetUser(int userId){
//Replace this with a DB hit or something :)
return new User(userId,"Michael", "Schwarz");
}
}
我们可以通过调用RegisterTypeForAjax注册GetUser代理:
private void Page_Load(object sender, EventArgs e){
Utility.RegisterTypeForAjax(typeof(User));
}
这样就可以在客户端异步调用GetUser:
<script language="javascript">
function getUser(userId){
User.GetUser(GetUser_callback);
}
function GetUser_callback(response){
if (response != null && response.value != null){
var user = response.value;
if (typeof(user) == "object"){
alert(user.FirstName + " " + user.LastName);
}
}
}
getUser(1);
</script>
响应中返回的值实际上是一个对象,公开了和服务器端对象相同的属性(FirstName、LastName和UserId)。
自定义转换器
我们已经看到,Ajax .NET包装器能够处理很多不同的.NET类型。但是除了大量.NET类和内建类型以外,包装器对不能正确返回的其他类型仅仅调用ToString()。为了避免这种情况,Ajax .NET包装器允许开发人员创建对象转换器,用于在服务器和客户机之间平滑传递复杂对象。
其他事项
在其他类中注册函数
上面的例子中,我们的服务器端函数都放在执行页面背后的代码中。但是,没有理由不能把这些函数放在单独的类文件中。要记住,包装器的工作方式是在指定类中发现所有带Ajax.AjaxMethod的方法。需要的类通过第二个脚本标签指定。使用 Ajax.Utility.RegisterTypeForAjax,我们可以指定需要的任何类。比如,将我们的服务器端函数作为单独的类是合情合理的:
Public Class AjaxFunctions
<Ajax.AjaxMethod()> _
Public Function Validate(username As String, password As String) As Boolean
'do something
'Return something
End Function
End Class
通过指定类的类型而不是页面就可以让Ajax包装器创建代理:
private void Page_Load(object sender, EventArgs e){
Ajax.Utility.RegisterTypeForAjax(typeof(AjaxFunctions));
//...
}
要记住,客户端代理的名称是<ClassName>. <ServerSideFunctionName>。因此,如果ServerSideAdd函数放在上面虚构的AjaxFunctions类中,客户端调用就应该是: AjaxFunctions.ServerSideAdd(1,2)。
代理到底是如何工作的
Ajax工具生成的第二个脚本标签(也可以手工插入)传递了页面的名称空间、类名和程序集。根据这些信息, Ajax.PageHandlerFactory就能够使用反射得到具有特定属性的任何函数的详细信息。显然,处理函数查找具有AjaxMethod属性的函数并得到它们的签名(返回类型、名称和参数),从能够创建必要的客户端代理。具体而言,包装器创建一个和类同名的javascript对象,该对象提供代理。换句话说,给定一个带有Ajax ServerSideAdd方法的服务器端类AjaxFunctions,我们就会得到公开ServerSideAdd函数的AjaxFunction javascript对象。如果将浏览器指向第二个脚本标签的路径就会看到这种动作。
返回Unicode字符
Ajax .NET包装器能够从服务器向客户机返回Unicode字符。为此,数据在返回之前必须在服务器上用html编码。比如:
[Ajax.AjaxMethod]
public string Test1(string name, string email, string comment){
string html = "";
html += "Hello " + name + "<br>";
html += "Thank you for your comment <b>";
html += System.Web.HttpUtility.HtmlEncode(comment);
html += "</b>.";
return html;
}
SessionState
服务器端函数中很可能需要访问会话信息。为此,只需要通过传递给Ajax.AjaxMethod属性的一个参数告诉Ajax启用这种功能。
在考察包装器会话能力的同时,我们来看看其他几个特性。这个例子中我们有一个文档管理系统,用户编辑的时候会对文档加锁。其他用户可以请求在文档可用的时候得到通知。如果没有AJAX,我们就只能等待该用户再次返回来检查请求的文档是否可用。显然不够理想。使用支持会话状态的Ajax就非常简单了。
首先来编写服务器端函数,目标是循环遍历用户希望编辑的documentId(保存在会话中)并返回所有已释放的文档。
[Ajax.AjaxMethod(HttpSessionStateRequirement.Read)]
public ArrayList DocumentReleased(){
if (HttpContext.Current.Session["DocumentsWaiting"] == null){
return null;
}
ArrayList readyDocuments = new ArrayList();
int[] documents = (int[])HttpContext.Current.Session["DocumentsWaiting"];
for (int i = 0; i < documents.Length; ++i){
Document document = Document.GetDocumentById(documents[i]);
if (document != null && document.Status == DocumentStatus.Ready){
readyDocuments.Add(document);
}
}
return readyDocuments;
}
}
要注意,我们指定了HttpSessionStateRequirement.Read值(还可以用Write和ReadWrite)。
现在编写使用该方法的javascript:
<script language="javascript">
function DocumentsReady_CallBack(response){
if (response.error != null){
alert(response.error);
return;
}
if (response.value != null && response.value.length > 0){
var div = document.getElementById("status");
div.innerHTML = "The following documents are ready!<br />";
for (var i = 0; i < response.value.length; ++i){
div.innerHTML += "<a href=\"edit.aspx?documentId=" + response.value[i].DocumentId + "\">" + response.value[i].Name + "</a><br />";
}
}
setTimeout('page.DocumentReleased(DocumentsReady_CallBack)', 10000);
}
</script>
<body onload="setTimeout('Document.DocumentReleased(DocumentsReady_CallBack)', 10000);">
我们的服务器端函数在页面加载时调用一次,然后每隔10秒钟调用一次。回调函数检查响应看看是否有返回值,有的话则在div标签中显示该用户可使用的新文档。
结束语
AJAX技术已经催生了原来只有桌面开发才具备的健壮而丰富的Web界面。Ajax .NET包装器让您很容易就能利用这种新的强大技术。请注意,Ajax .NET包装器和文档仍在开发之中。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号