nginx 原理 --模块
handler模块的基本结构
handler模块必须提供一个真正的处理函数,这个函数负责对来自客户端请求的真正处理。这个函数的处理,既可以选择自己直接生成内容,也可以选择拒绝处理,由后续的handler去进行处理,或者是选择丢给后续的filter进行处理。来看一下这个函数的原型申明。
typedef ngx_int_t (*ngx_http_handler_pt)(ngx_http_request_t *r);
r是http请求。里面包含请求所有的信息,这里不详细说明了,可以参考别的章节的介绍。 该函数处理成功返回NGX_OK,处理发生错误返回NGX_ERROR,拒绝处理(留给后续的handler进行处理)返回NGX_DECLINE。 返回NGX_OK也就代表给客户端的响应已经生成好了,否则返回NGX_ERROR就发生错误了。
http access module
该模块的代码位于src/http/modules/ngx_http_access_module.c中。该模块的作用是提供对于特定host的客户端的访问控制。可以限定特定host的客户端对于服务端全部,或者某个server,或者是某个location的访问。 该模块的实现非常简单,总共也就只有几个函数。
static ngx_int_t ngx_http_access_handler(ngx_http_request_t *r);
static ngx_int_t ngx_http_access_inet(ngx_http_request_t *r,
ngx_http_access_loc_conf_t *alcf, in_addr_t addr);
#if (NGX_HAVE_INET6)
static ngx_int_t ngx_http_access_inet6(ngx_http_request_t *r,
ngx_http_access_loc_conf_t *alcf, u_char *p);
#endif
static ngx_int_t ngx_http_access_found(ngx_http_request_t *r, ngx_uint_t deny);
static char *ngx_http_access_rule(ngx_conf_t *cf, ngx_command_t *cmd,
void *conf);
static void *ngx_http_access_create_loc_conf(ngx_conf_t *cf);
static char *ngx_http_access_merge_loc_conf(ngx_conf_t *cf,
void *parent, void *child);
static ngx_int_t ngx_http_access_init(ngx_conf_t *cf);
对于与配置相关的几个函数都不需要做解释了,需要提一下的是函数ngx_http_access_init,该函数在实现上把本模块挂载到了NGX_HTTP_ACCESS_PHASE阶段的handler上,从而使自己的被调用时机发生在了NGX_HTTP_CONTENT_PHASE等阶段前。因为进行客户端地址的限制检查,根本不需要等到这么后面。
另外看一下这个模块的主处理函数ngx_http_access_handler。这个函数的逻辑也非常简单,主要是根据客户端地址的类型,来分别选择ipv4类型的处理函数ngx_http_access_inet还是ipv6类型的处理函数ngx_http_access_inet6。
而这个两个处理函数内部也非常简单,就是循环检查每个规则,检查是否有匹配的规则,如果有就返回匹配的结果,如果都没有匹配,就默认拒绝。
http static module
从某种程度上来说,此模块可以算的上是“最正宗的”,“最古老”的content handler。因为本模块的作用就是读取磁盘上的静态文件,并把文件内容作为产生的输出。在Web技术发展的早期,只有静态页面,没有服务端脚本来动态生成HTML的时候。恐怕开发个Web服务器的时候,第一个要开发就是这样一个content handler。
http static module的代码位于src/http/modules/ngx_http_static_module.c中,总共只有两百多行近三百行。可以说是非常短小。
我们首先来看一下该模块的模块上下文的定义。
ngx_http_module_t ngx_http_static_module_ctx = {
NULL, /* preconfiguration */
ngx_http_static_init, /* postconfiguration */
NULL, /* create main configuration */
NULL, /* init main configuration */
NULL, /* create server configuration */
NULL, /* merge server configuration */
NULL, /* create location configuration */
NULL /* merge location configuration */
};
是非常的简洁吧,连任何与配置相关的函数都没有。对了,因为该模块没有提供任何配置指令。大家想想也就知道了,这个模块做的事情实在是太简单了,也确实没什么好配置的。唯一需要调用的函数是一个ngx_http_static_init函数。好了,来看一下这个函数都干了写什么。
static ngx_int_t
ngx_http_static_init(ngx_conf_t *cf)
{
ngx_http_handler_pt *h;
ngx_http_core_main_conf_t *cmcf;
cmcf = ngx_http_conf_get_module_main_conf(cf, ngx_http_core_module);
h = ngx_array_push(&cmcf->phases[NGX_HTTP_CONTENT_PHASE].handlers);
if (h == NULL) {
return NGX_ERROR;
}
*h = ngx_http_static_handler;
return NGX_OK;
}
仅仅是挂载这个handler到NGX_HTTP_CONTENT_PHASE处理阶段。简单吧?
下面我们就看一下这个模块最核心的处理逻辑所在的ngx_http_static_handler函数。该函数大概占了这个模块代码量的百分之八九十。
static ngx_int_t
ngx_http_static_handler(ngx_http_request_t *r)
{
u_char *last, *location;
size_t root, len;
ngx_str_t path;
ngx_int_t rc;
ngx_uint_t level;
ngx_log_t *log;
ngx_buf_t *b;
ngx_chain_t out;
ngx_open_file_info_t of;
ngx_http_core_loc_conf_t *clcf;
if (!(r->method & (NGX_HTTP_GET|NGX_HTTP_HEAD|NGX_HTTP_POST))) {
return NGX_HTTP_NOT_ALLOWED;
}
if (r->uri.data[r->uri.len - 1] == '/') {
return NGX_DECLINED;
}
log = r->connection->log;
/*
* ngx_http_map_uri_to_path() allocates memory for terminating '\0'
* so we do not need to reserve memory for '/' for possible redirect
*/
last = ngx_http_map_uri_to_path(r, &path, &root, 0);
if (last == NULL) {
return NGX_HTTP_INTERNAL_SERVER_ERROR;
}
path.len = last - path.data;
ngx_log_debug1(NGX_LOG_DEBUG_HTTP, log, 0,
"http filename: \"%s\"", path.data);
clcf = ngx_http_get_module_loc_conf(r, ngx_http_core_module);
ngx_memzero(&of, sizeof(ngx_open_file_info_t));
of.read_ahead = clcf->read_ahead;
of.directio = clcf->directio;
of.valid = clcf->open_file_cache_valid;
of.min_uses = clcf->open_file_cache_min_uses;
of.errors = clcf->open_file_cache_errors;
of.events = clcf->open_file_cache_events;
if (ngx_http_set_disable_symlinks(r, clcf, &path, &of) != NGX_OK) {
return NGX_HTTP_INTERNAL_SERVER_ERROR;
}
if (ngx_open_cached_file(clcf->open_file_cache, &path, &of, r->pool)
!= NGX_OK)
{
switch (of.err) {
case 0:
return NGX_HTTP_INTERNAL_SERVER_ERROR;
case NGX_ENOENT:
case NGX_ENOTDIR:
case NGX_ENAMETOOLONG:
level = NGX_LOG_ERR;
rc = NGX_HTTP_NOT_FOUND;
break;
case NGX_EACCES:
#if (NGX_HAVE_OPENAT)
case NGX_EMLINK:
case NGX_ELOOP:
#endif
level = NGX_LOG_ERR;
rc = NGX_HTTP_FORBIDDEN;
break;
default:
level = NGX_LOG_CRIT;
rc = NGX_HTTP_INTERNAL_SERVER_ERROR;
break;
}
if (rc != NGX_HTTP_NOT_FOUND || clcf->log_not_found) {
ngx_log_error(level, log, of.err,
"%s \"%s\" failed", of.failed, path.data);
}
return rc;
}
r->root_tested = !r->error_page;
ngx_log_debug1(NGX_LOG_DEBUG_HTTP, log, 0, "http static fd: %d", of.fd);
if (of.is_dir) {
ngx_log_debug0(NGX_LOG_DEBUG_HTTP, log, 0, "http dir");
ngx_http_clear_location(r);
r->headers_out.location = ngx_palloc(r->pool, sizeof(ngx_table_elt_t));
if (r->headers_out.location == NULL) {
return NGX_HTTP_INTERNAL_SERVER_ERROR;
}
len = r->uri.len + 1;
if (!clcf->alias && clcf->root_lengths == NULL && r->args.len == 0) {
location = path.data + clcf->root.len;
*last = '/';
} else {
if (r->args.len) {
len += r->args.len + 1;
}
location = ngx_pnalloc(r->pool, len);
if (location == NULL) {
return NGX_HTTP_INTERNAL_SERVER_ERROR;
}
last = ngx_copy(location, r->uri.data, r->uri.len);
*last = '/';
if (r->args.len) {
*++last = '?';
ngx_memcpy(++last, r->args.data, r->args.len);
}
}
/*
* we do not need to set the r->headers_out.location->hash and
* r->headers_out.location->key fields
*/
r->headers_out.location->value.len = len;
r->headers_out.location->value.data = location;
return NGX_HTTP_MOVED_PERMANENTLY;
}
#if !(NGX_WIN32) /* the not regular files are probably Unix specific */
if (!of.is_file) {
ngx_log_error(NGX_LOG_CRIT, log, 0,
"\"%s\" is not a regular file", path.data);
return NGX_HTTP_NOT_FOUND;
}
#endif
if (r->method & NGX_HTTP_POST) {
return NGX_HTTP_NOT_ALLOWED;
}
rc = ngx_http_discard_request_body(r);
if (rc != NGX_OK) {
return rc;
}
log->action = "sending response to client";
r->headers_out.status = NGX_HTTP_OK;
r->headers_out.content_length_n = of.size;
r->headers_out.last_modified_time = of.mtime;
if (ngx_http_set_content_type(r) != NGX_OK) {
return NGX_HTTP_INTERNAL_SERVER_ERROR;
}
if (r != r->main && of.size == 0) {
return ngx_http_send_header(r);
}
r->allow_ranges = 1;
/* we need to allocate all before the header would be sent */
b = ngx_pcalloc(r->pool, sizeof(ngx_buf_t));
if (b == NULL) {
return NGX_HTTP_INTERNAL_SERVER_ERROR;
}
b->file = ngx_pcalloc(r->pool, sizeof(ngx_file_t));
if (b->file == NULL) {
return NGX_HTTP_INTERNAL_SERVER_ERROR;
}
rc = ngx_http_send_header(r);
if (rc == NGX_ERROR || rc > NGX_OK || r->header_only) {
return rc;
}
b->file_pos = 0;
b->file_last = of.size;
b->in_file = b->file_last ? 1: 0;
b->last_buf = (r == r->main) ? 1: 0;
b->last_in_chain = 1;
b->file->fd = of.fd;
b->file->name = path;
b->file->log = log;
b->file->directio = of.is_directio;
out.buf = b;
out.next = NULL;
return ngx_http_output_filter(r, &out);
}
首先是检查客户端的http请求类型(r->method),如果请求类型为NGX_HTTP_GET|NGX_HTTP_HEAD|NGX_HTTP_POST,则继续进行处理,否则一律返回NGX_HTTP_NOT_ALLOWED从而拒绝客户端的发起的请求。
其次是检查请求的url的结尾字符是不是斜杠‘/’,如果是说明请求的不是一个文件,给后续的handler去处理,比如后续的ngx_http_autoindex_handler(如果是请求的是一个目录下面,可以列出这个目录的文件),或者是ngx_http_index_handler(如果请求的路径下面有个默认的index文件,直接返回index文件的内容)。
然后接下来调用了一个ngx_http_map_uri_to_path函数,该函数的作用是把请求的http协议的路径转化成一个文件系统的路径。
然后根据转化出来的具体路径,去打开文件,打开文件的时候做了2种检查,一种是,如果请求的文件是个symbol link,根据配置,是否允许符号链接,不允许返回错误。还有一个检查是,如果请求的是一个名称,是一个目录的名字,也返回错误。如果都没有错误,就读取文件,返回内容。其实说返回内容可能不是特别准确,比较准确的说法是,把产生的内容传递给后续的filter去处理。
http log module
该模块提供了对于每一个http请求进行记录的功能,也就是我们见到的access.log。当然这个模块对于log提供了一些配置指令,使得可以比较方便的定制access.log。
这个模块的代码位于src/http/modules/ngx_http_log_module.c,虽然这个模块的代码有接近1400行,但是主要的逻辑在于对日志本身格式啊,等细节的处理。我们在这里进行分析主要是关注,如何编写一个log handler的问题。
由于log handler的时候,拿到的参数也是request这个东西,那么也就意味着我们如果需要,可以好好研究下这个结构,把我们需要的所有信息都记录下来。
对于log handler,有一点特别需要注意的就是,log handler是无论如何都会被调用的,就是只要服务端接受到了一个客户端的请求,也就是产生了一个request对象,那么这些个log handler的处理函数都会被调用的,就是在释放request的时候被调用的(ngx_http_free_request函数)。
那么当然绝对不能忘记的就是log handler最好,也是建议被挂载在NGX_HTTP_LOG_PHASE阶段。因为挂载在其他阶段,有可能在某些情况下被跳过,而没有执行到,导致你的log模块记录的信息不全。
还有一点要说明的是,由于nginx是允许在某个阶段有多个handler模块存在的,根据其处理结果,确定是否要调用下一个handler。但是对于挂载在NGX_HTTP_LOG_PHASE阶段的handler,则根本不关注这里handler的具体处理函数的返回值,所有的都被调用。如下,位于src/http/ngx_http_request.c中的ngx_http_log_request函数。
static void
ngx_http_log_request(ngx_http_request_t *r)
{
ngx_uint_t i, n;
ngx_http_handler_pt *log_handler;
ngx_http_core_main_conf_t *cmcf;
cmcf = ngx_http_get_module_main_conf(r, ngx_http_core_module);
log_handler = cmcf->phases[NGX_HTTP_LOG_PHASE].handlers.elts;
n = cmcf->phases[NGX_HTTP_LOG_PHASE].handlers.nelts;
for (i = 0; i < n; i++) {
log_handler[i](r);
}
}
过滤模块简介
过滤(filter)模块是过滤响应头和内容的模块,可以对回复的头和内容进行处理。它的处理时间在获取回复内容之后,向用户发送响应之前。它的处理过程分为两个阶段,过滤HTTP回复的头部和主体,在这两个阶段可以分别对头部和主体进行修改。
在代码中有类似的函数:
ngx_http_top_header_filter(r);
ngx_http_top_body_filter(r, in);
就是分别对头部和主体进行过滤的函数。所有模块的响应内容要返回给客户端,都必须调用这两个接口。
过滤模块的调用是有顺序的,它的顺序在编译的时候就决定了。控制编译的脚本位于auto/modules中,当你编译完Nginx以后,可以在objs目录下面看到一个ngx_modules.c的文件。打开这个文件,有类似的代码:
ngx_module_t *ngx_modules[] = {
...
&ngx_http_write_filter_module,
&ngx_http_header_filter_module,
&ngx_http_chunked_filter_module,
&ngx_http_range_header_filter_module,
&ngx_http_gzip_filter_module,
&ngx_http_postpone_filter_module,
&ngx_http_ssi_filter_module,
&ngx_http_charset_filter_module,
&ngx_http_userid_filter_module,
&ngx_http_headers_filter_module,
&ngx_http_copy_filter_module,
&ngx_http_range_body_filter_module,
&ngx_http_not_modified_filter_module,
NULL
};
从write_filter到not_modified_filter,模块的执行顺序是反向的。也就是说最早执行的是not_modified_filter,然后各个模块依次执行。所有第三方的模块只能加入到copy_filter和headers_filter模块之间执行。
Nginx执行的时候是怎么按照次序依次来执行各个过滤模块呢?它采用了一种很隐晦的方法,即通过局部的全局变量。比如,在每个filter模块,很可能看到如下代码:
static ngx_http_output_header_filter_pt ngx_http_next_header_filter;
static ngx_http_output_body_filter_pt ngx_http_next_body_filter;
...
ngx_http_next_header_filter = ngx_http_top_header_filter;
ngx_http_top_header_filter = ngx_http_example_header_filter;
ngx_http_next_body_filter = ngx_http_top_body_filter;
ngx_http_top_body_filter = ngx_http_example_body_filter;
ngx_http_top_header_filter是一个全局变量。当编译进一个filter模块的时候,就被赋值为当前filter模块的处理函数。而ngx_http_next_header_filter是一个局部全局变量,它保存了编译前上一个filter模块的处理函数。所以整体看来,就像用全局变量组成的一条单向链表。
每个模块想执行下一个过滤函数,只要调用一下ngx_http_next_header_filter这个局部变量。而整个过滤模块链的入口,需要调用ngx_http_top_header_filter这个全局变量。ngx_http_top_body_filter的行为与header fitler类似。
响应头和响应体过滤函数的执行顺序如下所示:
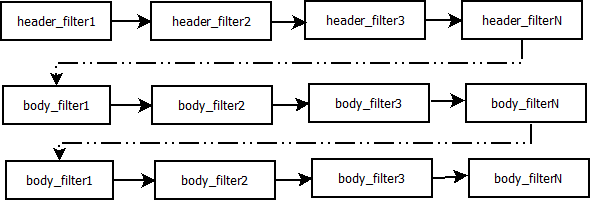
这图只表示了head_filter和body_filter之间的执行顺序,在header_filter和body_filter处理函数之间,在body_filter处理函数之间,可能还有其他执行代码。
响应头过滤函数主要的用处就是处理HTTP响应的头,可以根据实际情况对于响应头进行修改或者添加删除。响应头过滤函数先于响应体过滤函数,而且只调用一次,所以一般可作过滤模块的初始化工作。
响应头过滤函数的入口只有一个:
ngx_int_t
ngx_http_send_header(ngx_http_request_t *r)
{
...
return ngx_http_top_header_filter(r);
}
该函数向客户端发送回复的时候调用,然后按前一节所述的执行顺序。该函数的返回值一般是NGX_OK,NGX_ERROR和NGX_AGAIN,分别表示处理成功,失败和未完成。
你可以把HTTP响应头的存储方式想象成一个hash表,在Nginx内部可以很方便地查找和修改各个响应头部,ngx_http_header_filter_module过滤模块把所有的HTTP头组合成一个完整的buffer,最终ngx_http_write_filter_module过滤模块把buffer输出。
按照前一节过滤模块的顺序,依次讲解如下:
| filter module | description |
|---|---|
| ngx_http_not_modified_filter_module | 默认打开,如果请求的if-modified-since等于回复的last-modified间值,说明回复没有变化,清空所有回复的内容,返回304。 |
| ngx_http_range_body_filter_module | 默认打开,只是响应体过滤函数,支持range功能,如果请求包含range请求,那就只发送range请求的一段内容。 |
| ngx_http_copy_filter_module | 始终打开,只是响应体过滤函数, 主要工作是把文件中内容读到内存中,以便进行处理。 |
| ngx_http_headers_filter_module | 始终打开,可以设置expire和Cache-control头,可以添加任意名称的头 |
| ngx_http_userid_filter_module | 默认关闭,可以添加统计用的识别用户的cookie。 |
| ngx_http_charset_filter_module | 默认关闭,可以添加charset,也可以将内容从一种字符集转换到另外一种字符集,不支持多字节字符集。 |
| ngx_http_ssi_filter_module | 默认关闭,过滤SSI请求,可以发起子请求,去获取include进来的文件 |
| ngx_http_postpone_filter_module | 始终打开,用来将子请求和主请求的输出链合并 |
| ngx_http_gzip_filter_module | 默认关闭,支持流式的压缩内容 |
| ngx_http_range_header_filter_module | 默认打开,只是响应头过滤函数,用来解析range头,并产生range响应的头。 |
| ngx_http_chunked_filter_module | 默认打开,对于HTTP/1.1和缺少content-length的回复自动打开。 |
| ngx_http_header_filter_module | 始终打开,用来将所有header组成一个完整的HTTP头。 |
| ngx_http_write_filter_module | 始终打开,将输出链拷贝到r->out中,然后输出内容。 |
响应体过滤函数 (90%)
响应体过滤函数是过滤响应主体的函数。ngx_http_top_body_filter这个函数每个请求可能会被执行多次,它的入口函数是ngx_http_output_filter,比如:
ngx_int_t
ngx_http_output_filter(ngx_http_request_t *r, ngx_chain_t *in)
{
ngx_int_t rc;
ngx_connection_t *c;
c = r->connection;
rc = ngx_http_top_body_filter(r, in);
if (rc == NGX_ERROR) {
/* NGX_ERROR may be returned by any filter */
c->error = 1;
}
return rc;
}
ngx_http_output_filter可以被一般的静态处理模块调用,也有可能是在upstream模块里面被调用,对于整个请求的处理阶段来说,他们处于的用处都是一样的,就是把响应内容过滤,然后发给客户端。
具体模块的响应体过滤函数的格式类似这样:
static int
ngx_http_example_body_filter(ngx_http_request_t *r, ngx_chain_t *in)
{
...
return ngx_http_next_body_filter(r, in);
}
该函数的返回值一般是NGX_OK,NGX_ERROR和NGX_AGAIN,分别表示处理成功,失败和未完成。
响应的主体内容就存于单链表in,链表一般不会太长,有时in参数可能为NULL。in中存有buf结构体中,对于静态文件,这个buf大小默认是32K;对于反向代理的应用,这个buf可能是4k或者8k。为了保持内存的低消耗,Nginx一般不会分配过大的内存,处理的原则是收到一定的数据,就发送出去。一个简单的例子,可以看看Nginx的chunked_filter模块,在没有content-length的情况下,chunk模块可以流式(stream)的加上长度,方便浏览器接收和显示内容。
Nginx过滤模块一大特色就是可以发出子请求,也就是在过滤响应内容的时候,你可以发送新的请求,Nginx会根据你调用的先后顺序,将多个回复的内容拼接成正常的响应主体。一个简单的例子可以参考addition模块。
Nginx是如何保证父请求和子请求的顺序呢?当Nginx发出子请求时,就会调用ngx_http_subrequest函数,将子请求插入父请求的r->postponed链表中。子请求会在主请求执行完毕时获得依次调用。子请求同样会有一个请求所有的生存期和处理过程,也会进入过滤模块流程。
关键点是在postpone_filter模块中,它会拼接主请求和子请求的响应内容。r->postponed按次序保存有父请求和子请求,它是一个链表,如果前面一个请求未完成,那后一个请求内容就不会输出。当前一个请求完成时并输出时,后一个请求才可输出,当所有的子请求都完成时,所有的响应内容也就输出完毕了
upstream模块
nginx模块一般被分成三大类:handler、filter和upstream。前面的章节中,读者已经了解了handler、filter。利用这两类模块,可以使nginx轻松完成任何单机工作。而本章介绍的upstream模块,将使nginx跨越单机的限制,完成网络数据的接收、处理和转发。
数据转发功能,为nginx提供了跨越单机的横向处理能力,使nginx摆脱只能为终端节点提供单一功能的限制,而使它具备了网路应用级别的拆分、封装和整合的战略功能。在云模型大行其道的今天,数据转发是nginx有能力构建一个网络应用的关键组件。当然,鉴于开发成本的问题,一个网络应用的关键组件一开始往往会采用高级编程语言开发。但是当系统到达一定规模,并且需要更重视性能的时候,为了达到所要求的性能目标,高级语言开发出的组件必须进行结构化修改。此时,对于修改代价而言,nginx的upstream模块呈现出极大的吸引力,因为它天生就快。作为附带,nginx的配置系统提供的层次化和松耦合使得系统的扩展性也达到比较高的程度。
言归正传,下面介绍upstream的写法。
upstream模块接口
从本质上说,upstream属于handler,只是他不产生自己的内容,而是通过请求后端服务器得到内容,所以才称为upstream(上游)。请求并取得响应内容的整个过程已经被封装到nginx内部,所以upstream模块只需要开发若干回调函数,完成构造请求和解析响应等具体的工作。
这些回调函数如下表所示:
| create_request | 生成发送到后端服务器的请求缓冲(缓冲链),在初始化upstream 时使用。 |
| reinit_request | 在某台后端服务器出错的情况,nginx会尝试另一台后端服务器。 nginx选定新的服务器以后,会先调用此函数,以重新初始化 upstream模块的工作状态,然后再次进行upstream连接。 |
| process_header | 处理后端服务器返回的信息头部。所谓头部是与upstream server 通信的协议规定的,比如HTTP协议的header部分,或者memcached 协议的响应状态部分。 |
| abort_request | 在客户端放弃请求时被调用。不需要在函数中实现关闭后端服务 器连接的功能,系统会自动完成关闭连接的步骤,所以一般此函 数不会进行任何具体工作。 |
| finalize_request | 正常完成与后端服务器的请求后调用该函数,与abort_request 相同,一般也不会进行任何具体工作。 |
| input_filter | 处理后端服务器返回的响应正文。nginx默认的input_filter会 将收到的内容封装成为缓冲区链ngx_chain。该链由upstream的 out_bufs指针域定位,所以开发人员可以在模块以外通过该指针 得到后端服务器返回的正文数据。memcached模块实现了自己的 input_filter,在后面会具体分析这个模块。 |
| input_filter_init | 初始化input filter的上下文。nginx默认的input_filter_init 直接返回。 |
memcached模块分析
memcache是一款高性能的分布式cache系统,得到了非常广泛的应用。memcache定义了一套私有通信协议,使得不能通过HTTP请求来访问memcache。但协议本身简单高效,而且memcache使用广泛,所以大部分现代开发语言和平台都提供了memcache支持,方便开发者使用memcache。
nginx提供了ngx_http_memcached模块,提供从memcache读取数据的功能,而不提供向memcache写数据的功能。作为web服务器,这种设计是可以接受的。
下面,我们开始分析ngx_http_memcached模块,一窥upstream的奥秘。
Handler模块?
初看memcached模块,大家可能觉得并无特别之处。如果稍微细看,甚至觉得有点像handler模块,当大家看到这段代码以后,必定疑惑为什么会跟handler模块一模一样。
clcf = ngx_http_conf_get_module_loc_conf(cf, ngx_http_core_module);
clcf->handler = ngx_http_memcached_handler;
因为upstream模块使用的就是handler模块的接入方式。同时,upstream模块的指令系统的设计也是遵循handler模块的基本规则:配置该模块才会执行该模块。
{ ngx_string("memcached_pass"),
NGX_HTTP_LOC_CONF|NGX_HTTP_LIF_CONF|NGX_CONF_TAKE1,
ngx_http_memcached_pass,
NGX_HTTP_LOC_CONF_OFFSET,
0,
NULL }
所以大家觉得眼熟是好事,说明大家对Handler的写法已经很熟悉了。
Upstream模块!
那么,upstream模块的特别之处究竟在哪里呢?答案是就在模块处理函数的实现中。upstream模块的处理函数进行的操作都包含一个固定的流程。在memcached的例子中,可以观察ngx_http_memcached_handler的代码,可以发现,这个固定的操作流程是:
1. 创建upstream数据结构。
if (ngx_http_upstream_create(r) != NGX_OK) {
return NGX_HTTP_INTERNAL_SERVER_ERROR;
}
2. 设置模块的tag和schema。schema现在只会用于日志,tag会用于buf_chain管理。
u = r->upstream;
ngx_str_set(&u->schema, "memcached://");
u->output.tag = (ngx_buf_tag_t) &ngx_http_memcached_module;
3. 设置upstream的后端服务器列表数据结构。
mlcf = ngx_http_get_module_loc_conf(r, ngx_http_memcached_module);
u->conf = &mlcf->upstream;
4. 设置upstream回调函数。在这里列出的代码稍稍调整了代码顺序。
u->create_request = ngx_http_memcached_create_request;
u->reinit_request = ngx_http_memcached_reinit_request;
u->process_header = ngx_http_memcached_process_header;
u->abort_request = ngx_http_memcached_abort_request;
u->finalize_request = ngx_http_memcached_finalize_request;
u->input_filter_init = ngx_http_memcached_filter_init;
u->input_filter = ngx_http_memcached_filter;
5. 创建并设置upstream环境数据结构。
ctx = ngx_palloc(r->pool, sizeof(ngx_http_memcached_ctx_t));
if (ctx == NULL) {
return NGX_HTTP_INTERNAL_SERVER_ERROR;
}
ctx->rest = NGX_HTTP_MEMCACHED_END;
ctx->request = r;
ngx_http_set_ctx(r, ctx, ngx_http_memcached_module);
u->input_filter_ctx = ctx;
6. 完成upstream初始化并进行收尾工作。
r->main->count++;
ngx_http_upstream_init(r);
return NGX_DONE;
任何upstream模块,简单如memcached,复杂如proxy、fastcgi都是如此。不同的upstream模块在这6步中的最大差别会出现在第2、3、4、5上。其中第2、4两步很容易理解,不同的模块设置的标志和使用的回调函数肯定不同。第5步也不难理解,只有第3步是最为晦涩的,不同的模块在取得后端服务器列表时,策略的差异非常大,有如memcached这样简单明了的,也有如proxy那样逻辑复杂的。这个问题先记下来,等把memcached剖析清楚了,再单独讨论。
第6步是一个常态。将count加1,然后返回NGX_DONE。nginx遇到这种情况,虽然会认为当前请求的处理已经结束,但是不会释放请求使用的内存资源,也不会关闭与客户端的连接。之所以需要这样,是因为nginx建立了upstream请求和客户端请求之间一对一的关系,在后续使用ngx_event_pipe将upstream响应发送回客户端时,还要使用到这些保存着客户端信息的数据结构。这部分会在后面的原理篇做具体介绍,这里不再展开。
将upstream请求和客户端请求进行一对一绑定,这个设计有优势也有缺陷。优势就是简化模块开发,可以将精力集中在模块逻辑上,而缺陷同样明显,一对一的设计很多时候都不能满足复杂逻辑的需要。对于这一点,将会在后面的原理篇来阐述。
回调函数
前面剖析了memcached模块的骨架,现在开始逐个解决每个回调函数。
1. ngx_http_memcached_create_request:很简单的按照设置的内容生成一个key,接着生成一个“get $key”的请求,放在r->upstream->request_bufs里面。
2. ngx_http_memcached_reinit_request:无需初始化。
3. ngx_http_memcached_abort_request:无需额外操作。
4. ngx_http_memcached_finalize_request:无需额外操作。
5. ngx_http_memcached_process_header:模块的业务重点函数。memcache协议的头部信息被定义为第一行文本,可以找到这段代码证明:
for (p = u->buffer.pos; p < u->buffer.last; p++) {
if ( * p == LF) {
goto found;
}
如果在已读入缓冲的数据中没有发现LF(‘n’)字符,函数返回NGX_AGAIN,表示头部未完全读入,需要继续读取数据。nginx在收到新的数据以后会再次调用该函数。
nginx处理后端服务器的响应头时只会使用一块缓存,所有数据都在这块缓存中,所以解析头部信息时不需要考虑头部信息跨越多块缓存的情况。而如果头部过大,不能保存在这块缓存中,nginx会返回错误信息给客户端,并记录error log,提示缓存不够大。
process_header的重要职责是将后端服务器返回的状态翻译成返回给客户端的状态。例如,在ngx_http_memcached_process_header中,有这样几段代码:
r->headers_out.content_length_n = ngx_atoof(len, p - len - 1);
u->headers_in.status_n = 200;
u->state->status = 200;
u->headers_in.status_n = 404;
u->state->status = 404;
u->state用于计算upstream相关的变量。比如u->state->status将被用于计算变量“upstream_status”的值。u->headers_in将被作为返回给客户端的响应返回状态码。而第一行则是设置返回给客户端的响应的长度。
在这个函数中不能忘记的一件事情是处理完头部信息以后需要将读指针pos后移,否则这段数据也将被复制到返回给客户端的响应的正文中,进而导致正文内容不正确。
u->buffer.pos = p + 1;
process_header函数完成响应头的正确处理,应该返回NGX_OK。如果返回NGX_AGAIN,表示未读取完整数据,需要从后端服务器继续读取数据。返回NGX_DECLINED无意义,其他任何返回值都被认为是出错状态,nginx将结束upstream请求并返回错误信息。
6. ngx_http_memcached_filter_init:修正从后端服务器收到的内容长度。因为在处理header时没有加上这部分长度。
7. ngx_http_memcached_filter:memcached模块是少有的带有处理正文的回调函数的模块。因为memcached模块需要过滤正文末尾CRLF “END” CRLF,所以实现了自己的filter回调函数。处理正文的实际意义是将从后端服务器收到的正文有效内容封装成ngx_chain_t,并加在u->out_bufs末尾。nginx并不进行数据拷贝,而是建立ngx_buf_t数据结构指向这些数据内存区,然后由ngx_chain_t组织这些buf。这种实现避免了内存大量搬迁,也是nginx高效的奥秘之一。
upstream模块是从handler模块发展而来,指令系统和模块生效方式与handler模块无异。不同之处在于,upstream模块在handler函数中设置众多回调函数。实际工作都是由这些回调函数完成的。每个回调函数都是在upstream的某个固定阶段执行,各司其职,大部分回调函数一般不会真正用到。upstream最重要的回调函数是create_request、process_header和input_filter,他们共同实现了与后端服务器的协议的解析部分。
未完待续。。。。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号