内存对齐详解
什么是内存对齐
- CPU读取内存是一块一块读取的,并不会以一个字节一个字节去读取和写入内存。
- 块的大小可以为2、4、6、8、16等字节大小,块的大小称为内存访问粒度。
为什么要进行内存对齐
- 平台(移植性)原因:不是所有的硬件平台都能够访问任意地址上的任意数据。例如:特点的硬件平台只允许在特定地址获取特定类型的数据,否则会导致异常情况。
- 性能原因:如果不进行内存对齐,会导致CPU两次内存访问,并且要花费额外的时钟周期来处理对齐及运算。如果本身是内存对齐的,则只需要访问一次即可完成读取操作。
没有内存对齐情况下CPU处理流程
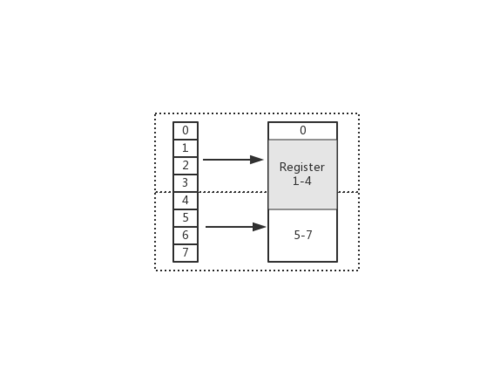
如图:我们需要获取的数据存储在1-4字节
- CPU先读取未对齐地址的第一块内存,0-3字节,然后移除不需要的0字节
- CPU再次读取未对齐地址的第二块内存,4-7字节,然后移除不需要的5、6、7
- 合并1-4字节数据
- 合并后放入寄存器
从上述流程可以看出,如果不做内存对齐需要进行两次读取,还需要增加其他许多耗时动作,如果进行内存对齐,从0地址开始读取4个字节,则只需要读取一次即可,显然会高效很多,相当于空间换时间。
默认系数
- 不同平台上编译器都有自己默认的“对齐系数”,可以通过预编译命令#pragma pack(n)进行变更,n就是“对齐系数”。
- 常用平台系数:32位对齐系数为 4 , 64位对齐系数为 8
对齐流程
- 成员对齐:在Go中可以调用unsafe.Alignof返回相应类型的对齐系数,对齐系数都是2的n次方,最大不会超过8,因为64编译器默认的对齐系数为8。
- 结构体第一个成员变量偏移量为0,往后每个成员变量的对齐值必须为编译器默认对齐长度或当前成员变量类型的长度,取最小值作为当前类型的对齐值,偏移量必须为对齐值的整数倍。
- 整体对齐:所有成员对齐后,最终结构体也需要进行内存对齐
- 对齐值必须为编译器默认对齐长度或结构体所有成员变量类型中的最大长度,取最大数的最小整数倍最为对齐值
“内存对齐”实例分析
// 内存对齐测试
// 类型相应字节大小:
// bool 1字节 int32 4字节 int8 1字节 int64 8字节 byte 1字节
func TestAlignment(t *testing.T) {
// 首先进行成员对齐:
// 1. a 1 字节 偏移量 0 占用 1 内存情况:a
// 2. b 4 字节 偏移量 4 占用 4 内存情况:axxxbbbb
// 3. c 1 字节 偏移量 8 占用 1 内存情况:axxxbbbbc
// 4. d 8 字节 偏移量 16 占用 8 内存情况:axxxbbbbcxxxxxxxdddddddd
// 5. e 1 字节 偏移量 24 占用 1 内存情况:axxxbbbbcxxxxxxxdddddddde
// 成员对齐以后进行整体对齐:
// 当前成员共占用25字节,需要保持对齐系数8的倍数,所以需要对齐到32
// 最终内存对齐情况:axxxbbbbcxxxxxxxddddddddexxxxxxx
part1 := struct {
a bool
b int32
c int8
d int64
e byte
}{}
// 首先进行成员对齐:
// 1. e 1 字节 偏移量 0 占用 1 内存情况:e
// 2. c 1 字节 偏移量 1 占用 1 内存情况:ec
// 3. a 1 字节 偏移量 2 占用 1 内存情况:eca
// 4. b 4 字节 偏移量 4 占用 4 内存情况:ecaxbbbb
// 5. d 8 字节 偏移量 8 占用 1 内存情况:ecaxbbbbdddddddd
// 成员对齐以后进行整体对齐:
// 当前成员共占用16字节,刚好为内存对齐系数8的倍数
// 所以最终内存对齐情况:ecaxbbbbdddddddd
part2 := struct {
e byte
c int8
a bool
b int32
d int64
}{}
fmt.Printf("part1 size: %d, align: %d\n", unsafe.Sizeof(part1), unsafe.Alignof(part1))
fmt.Printf("part2 size: %d, align: %d\n", unsafe.Sizeof(part2), unsafe.Alignof(part2))
// 成员对齐:Age 占用 4 字节
// 整体对齐:64位内存系数位8 所以最终内存占用 8 字节
part3 := struct {
Age int
}{}
fmt.Printf("part3 size: %d, align: %d\n", unsafe.Sizeof(part3), unsafe.Alignof(part3))
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号