软件设计师备考笔记(文末复习资料分享)
软考学习笔记
一、数据的表示
- R进制转十进制使用按权展开法
- 二进制符号位:0代表正数,1代表负数
- 二进制转八进制:按三位划分计算
- 二进制转十六进制:按四位划分计算
- 正数的原码、反码、补码相同
- 负数的反码:在原码的基础上除符号位全部取反
- 负数的补码:在反码的基础上+1
- 负数的补码转原码:除符号位全部取反 +1
- 移码:在补码的基础上将符号位取反
- 减法运算:使用两个数的补码相加
二、数值表示范围
-
定点整数
- 原码 -(2^n-1-1) ~ +(2^n-1-1)
- 反码 -(2^n-1-1) ~ +(2^n-1-1)
- 补码 -2^n-1 ~ +(2^n-1-1)
- 移码 -2^n-1 ~ +(2^n-1-1)
-
定点小数
- 原码 -(1-2^-(n-1)) ~ +(1-2^-(n-1))
- 反码 -(1-2^-(n-1)) ~ +(1-2^-(n-1))
- 补码 -1 ~ +(1-2^-(n-1))
- 移码 -1 ~ +(1-2^-(n-1))
三、浮点的运算
- 浮点数表示:N = 尾数 * 基数^指数
- 运算过程:对阶 》 尾数运算 》 结果格式化
- 特点
- 一般尾数用补码,阶码用移码
- 阶码的尾数决定数的表示范围,位数越多范围越大
- 尾数的尾数决定数的有效精度,位数越多精度越高
- 对阶时,小数向大数看齐
- 对阶是通过较小数的尾数右移实现的
- 浮点数存储方式: 阶符 | 阶码 | 尾符 | 尾码
四、计算机结构
- 外设
- 输入设备
- 存储器 辅助存储器
- 输出设备
- 主机
- 主存储器
- CPU
- 运算器
- 算数逻辑单元ALU:数据的算数运算和逻辑运算
- 累加寄存器AC:通用寄存器,为ALU提供一个工作区,用在暂存数据
- 数据缓冲寄存器DR:写内存时,暂存指令或数据
- 状态条件寄存器PSW:存状态标志与控制标志(争议:也有将其归为控制器的)
- 控制器
- 程序计数器PC :存储下一条要执行指令地址
- 指令寄存器IR:存储即将执行的指令
- 指令译码器 ID:对指令中的操作码字段进行分析解释
- 时序部件:提供时序控制信号
- 地址寄存器DR: 记录当前指令地址
- 运算器
五、计算机体系结构分类-Flynn
- 单指令流单数据流SISD
- 控制部分 处理器 主存模块 均一个
- 代表:单处理器系统
- 单指令流多数据流SIMD
- 处理器和主存模块多个
- 关键特性:个处理器以异步的形式执行同一条指令
- 代表:并行处理机,阵列处理机,超级向量处理机
- 多指令流单数据流MISD
- 控制器和主存模块多个
- 被证明不可能,至少是不实际
- 目前咩有,有文献称流水线计算机为此类
- 多指令流多数据流MIMD
- 控制部分,处理器,主存模块均为多个
- 能够实现作业,任务,指令等各级全面并行
- 多处理机系统,多计算机
六、指令的基本概念
- 一条指令就是机器语言的一个语句,它是一组有意义的二进制代码,指令的基本格式: 操作代码字段|地址码字段
- 操作码部分指出了计算机要执行什么性质的操作,如加法、减法、取数、存数等。地址码字段需要包含各操作结果的存放地址等,从其地址结构的角度可以分为三地址指令、二地址指令、一地址指令和零地址指令。
七、寻址方式
- 立即寻址方式
- 操作数直接在指令中,速度快,灵活性差
- 直接寻址方式
- 指令中存放的是操作数的地址
- 间接寻址方式
- 指令中存放了一个地址,这个地址对应的内容是操作数的地址
- 寄存器寻址方式
- 寄存器存放操作数
- 寄存器间接寻址方式
- 寄存器内存放的是操作数的地址
八、CISC与RISC
- CISC(复杂)
- 数量多,使用频率差别大,可变长格式
- 寻址方式支持多种
- 实现方式:微程序控制技术(微码)
- 研制周期长
- RISC(精简)
- 数量少,使用频率接近,定长格式,大部分为单周期指令,操作寄存器,只有Load/Store操作内存
- 寻址方式支持方式少
- 实现方式:增加了通用寄存器;硬布线逻辑控制为主适合采用流水线
- 优化编译,有效支持高级语言
- CISC与RISC比较维度:指令数量,指令使用频率,寻址方式,寄存器,流水线支持,高级语言支持
- CISC:复杂,指令数量多,频率差别大,多寻址
- RISC:精简,指令数量少,操作寄存器,单周期,少寻址,多通用寄存器,流水线
九、流水线
-
指在程序执行时多条指令重叠进行操作的一种准并行处理实现技术。各种部件同时处理是针对不同指令而言的,她们可同时为多条指令的不同部分进行工作,以提高各部件的利用率和指令的平均执行速度。
-
流水线周期为执行时间最长的一段
-
流水线计算公式为:1条指令执行时间 + (指令条数-1)*流水线周期
- 理论公式:(t1+t2+...tk)+(n-1)*△t
- 实践公式:k*△t+(n-1)*△t
- △t指的就是流水线执行周期 ,K为步骤数量
一条指令的执行过程可以分解为取值、分析和执行三步,在取指时间t取指=3△t、分析时间t分析=2△t、执行时间t执行=4△t的情况下,若按串行方式执行,则10条指令全部执行完需要(90)△t,若按流水线的方式执行,流水线周期为(4)△t,则10条指令全部执行完需要(45)△t。
-
超标量流水线
- 度:有几条流水线就是几度
-
流水线吞吐率计算
-
流水线吞吐率 TP 是指单位时间内流水线所完成的任务数量或输出的结果数量。计算流水线吞吐率的最基本的公式:
TP = 指令条数 / 流水线执行时间
上题吞吐率为:10 / 45△t
-
流水线最大吞吐率
TPmax = Lim n->∞*n / (k+n-1)△t = 1 / △t
上题最大吞吐率: 1 / 4△t
-
十、层次化存储结构
- CPU 寄存器 最快,但容量小,成本高
- Cache 按内容存取
- 内存(主存) 分两类:随机存储器(RAM) 只读存储器(ROM)
- 外存(辅存)硬盘,光盘,U盘等
十一、Cache
-
概念
-
在计算机的存储系统体系中,Cache是访问速度最快的层次(若有寄存器,则寄存器最快)
-
使用Cache改善系统性能的依据是程序的局部性原理
-
如果以h代表对Cache的访问命中率,t1表示Cache的周期时间,t2表示主存储器周期的时间,以读操作为例,使用“Cache + 主存储器”的系统的平均周期为t3,则:
t3 = h * t1 + (1-h) * t2
其中,(1-h)又称为失效率(未命中率)
-
-
映像
- 直接相联映像:硬件电路较简单,但冲突率很高
- 全相联映像:电路难于设计和实现,只适合小容量的cache,冲突率较低
- 组相联映像:直接相联与全相联的折中
- 地址映像是将主存与Cache的存储空间划分为若干大小相同的页(称为块)
- 例如,某机的主存容量为1GB,划分为2048页,每页512KB;Cache容量为8MB,划分为16页,每页512KB.
十二、主存-编址与计算
-
存储单元
-
按字编址:存储体的存储单元是字存储单元,即最小寻址单位是一个字
-
按字节编址:存储体的存储单元是字节存储单元,即最小寻址单位是一个字节 1 byte = 8 bit
-
根据存储器所要求的容量和选定的存储芯片的容量,就可以计算出所需芯片总数,即:
- 总片数 = 总容量 / 每片的容量
-
例:若内存地址区间为4000H~43FFH,每个存储单元可存储16位二进制数,该内存区域用4片存储器芯片构成,则构成该内存所用的存储器芯片的容量是多少?
43FFH - 4000H +1 = 4400H - 4000H = 400H
十六进制一位代表4位二进制,400H = 0100 0000 0000
2 的10次方 * 16bit / 4 = 256 * 16bit
十三、总线
- 一条总线同一时刻仅允许一个设备发送,但允许多个设备接收。
- 总线的分类:
- 数据总线(Data Bus):在CPU与RAM之间来回传送需要处理或是需要存储的数据。
- 地址总线(Address Bus):用来指定在RAM(Random Access Memory)之中存储的数据的地址。
- 控制总线(Control Bus):将微处理器控制单元(Control Unit)信号传送到周边设备,一般常见的为USB Bus和1394 Bus。
十四、串联系统与并联系统
- 可靠性计算公式:
- 串联型:R = R1 * R2 * ... * Rn
- 并联型:R = 1 - (1-R1)*(1-R2)*...*(1-Rn)
十五、N模混合系统
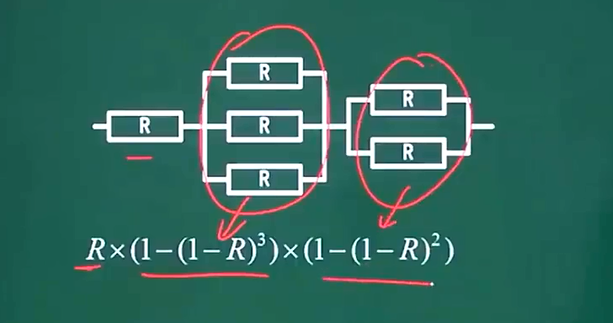
十六、校验码
- 基础知识
- 码距:任何一种编码都由许多码字构成,任意两个码字之间最少变化的二进制数就称为数据校验码的码距。
- 例如,用4位二进制表示16种状态,则有16个不同的码字,此时码距为1,如0000与0001。
- 奇偶效验
- 奇偶校验码的编码方法是:由若干位有效信息(如一个字节),再加上一个二进制位(效验位)组成校验码。
- 奇校验:整个校验码(有效信息和校验位)中“1”的个数为奇数。
- 偶校验:整个校验码(有效信息和校验位)中“1”的个数为偶数。
- 奇偶校验,可检查1位的错误,不可纠错。
- 循环校验码CRC
- CRC校验,可检错,不可纠错。
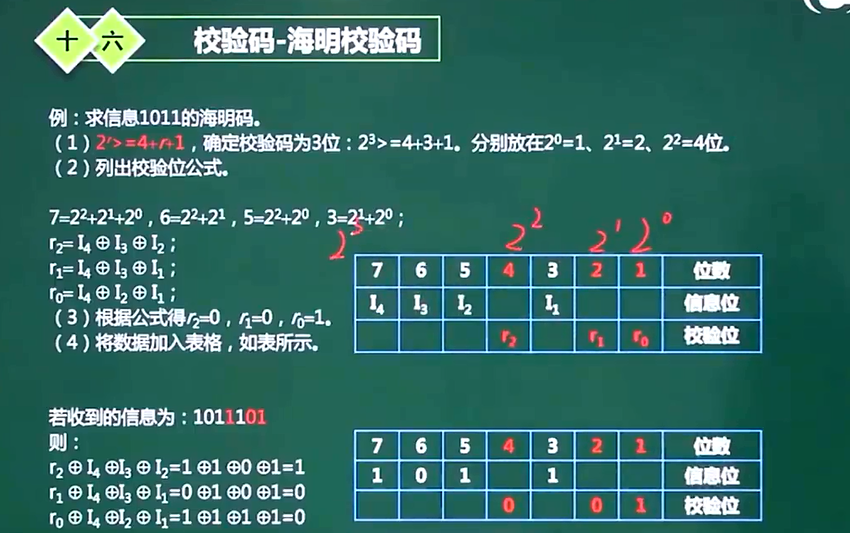
- 海明校验码
- 海明校验,可检错,也可纠错
- 在有效信息位中加入几个校验位形成海明码,是码距比较均匀的拉大,并把海明码的每个二进制位分配到几个奇偶校验组中。当某一位出错后,就会引起有关的一个校验位的值发生变化,这不但可以发现错误,还能指出错误的位置,为自动纠错提供了依据。
- 2 ^r >= m + r + 1
- 编码集的海明码距为d+1,那么可以检测出d位的错误
- 编码集的海明码距为2d+1,那么可以纠正d位错误
十八、存储管理
-
页式存储组织
-
将程序与内存划分为同样大小的快,以页为单位将程序调入内存。
-

-
优点:利用率高,碎片小,分配及管理简单
-
缺点:增加了系统开销;可能产生抖动现象
-
逻辑地址 = 页号 + 内存地址
-
物理地址 = 页侦号 + 页内地址
-
例如,页式存储系统中,每个页的大小为4k,将逻辑地址转换为对应的物理地址:
逻辑地址:10 1100 1101 1110
从题目我们可以知道每页大小为4k,也就是10的12次方,所以后面的十二位二进制为页内地址,不需要变化。由前面的二位二进制10可以得出页号为2,从图中可以看到页号2对应的页侦号为6。
所以对应的物理地址为:110 1100 1101 1110
-
-
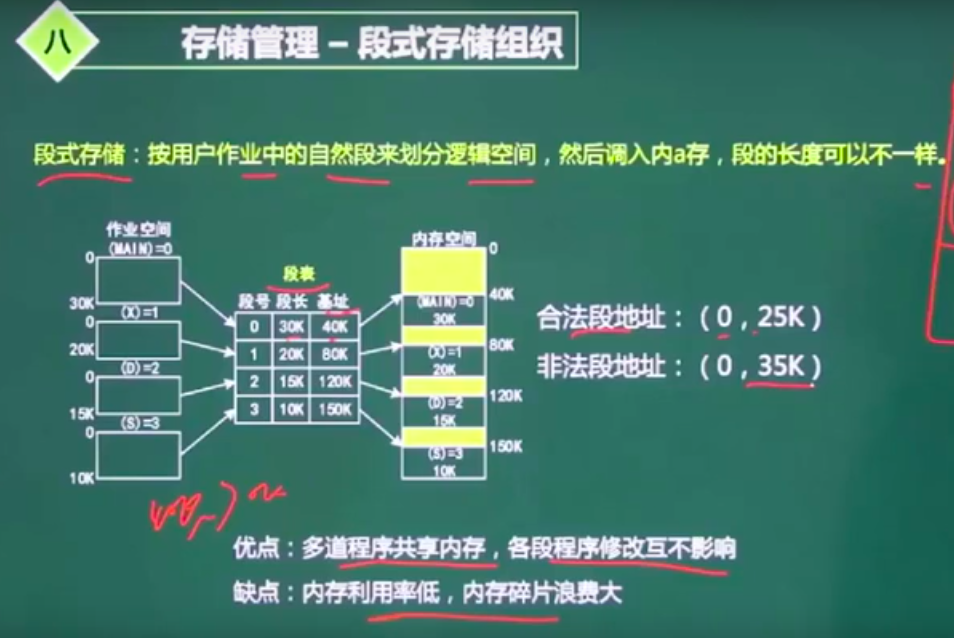
段式存储
-
-
段长表示该段能够存储的长度,基址代表起始位置。0段长度不能超过30k。
-
优点:多道程序共享内存,各段程序修改互不影响
-
缺点:内存利用率低,内存碎片浪费大
-
-
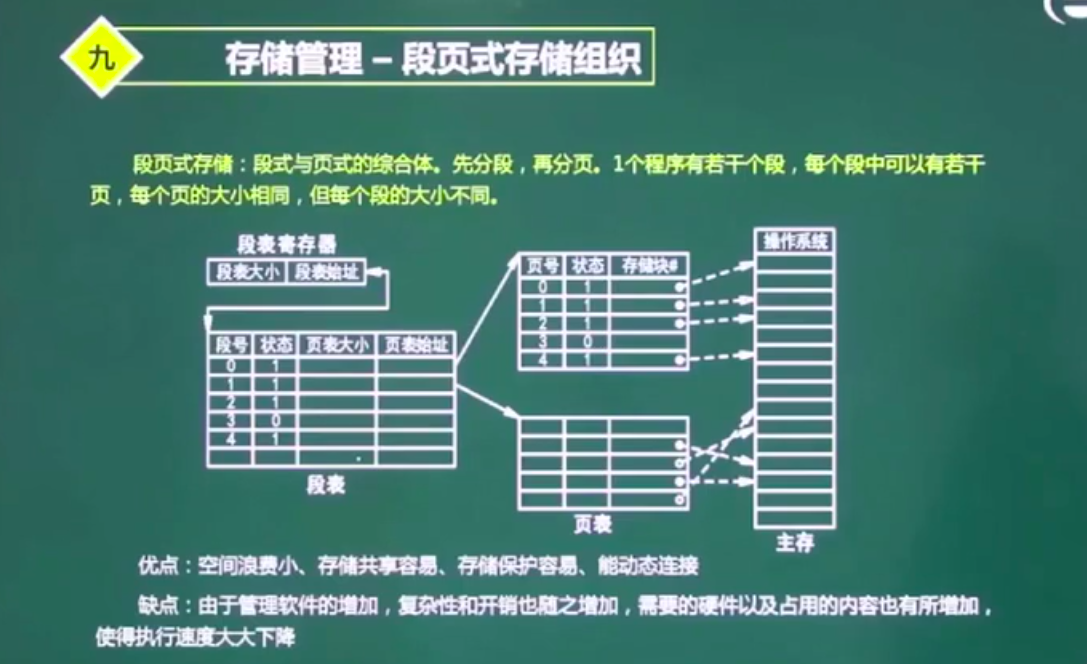
段页式存储
-
-
优点:空间浪费小、存储共享容易、存储保护容易、能动态连接
-
缺点:由于管理软件增加,复杂性和开销也随之增加,需要的硬件以及占用的内容也有所增加,使得执行速度大大下降。
-
-
页面置换算法
-
磁盘管理
- 磁道
- 扇区
- 存取时间 = 寻道时间 + 等待时间,寻道时间是指磁头移动到磁道需要的时间,等待的时间为等待读写的扇区转到磁头下方所用的时间。
-
磁盘调度算法
- 先来先服务 FCFS
- 最短寻道时间优先 SSTF
- 扫描算法 SCAN
- 循环扫描 CSCAN 算法
-
读取磁盘数据时间计算
-
读取磁盘数据的时间应包括以下三个部分:
- 找磁道的时间
- 找块(扇区)的时间,即旋转延迟时间
- 传输时间
某磁盘磁头从一个磁道移至另一个磁道需要10ms,文件在磁盘上非连续存放,逻辑上相邻数据块的平均移动距离为10个磁道,每块的旋转延迟时间及传输的时间分别为100ms和2ms,则读取一个100块的文件需要多少ms时间?
((10 * 10)+ 100 + 2)* 100 = 20200
-

十九、作业管理
- 作业调度算法
- 先来先服务法
- 时间片轮转法
- 短作业优先法
- 最高优先权优先法
- 高响应比优先法
十四、文件管理-索引文件结构
- 直接索引
- 一级间接索引
- 二级间接索引
- 三级间接索引
- https://www.bilibili.com/video/BV1EU4y1a7Vt?from=search&seid=8803601225094703891
- https://www.bilibili.com/video/BV1TT4y1u7K6?from=search&seid=8803601225094703891
十五、文件管理-树型目录结构
- 考察相对路径和绝对路径
- 相对路径在本身目录下面找,不要包括本身目录
- 绝对路径从根目录开始找
十六、文件管理-空闲存储空间的管理
十七、设备管理-数据传输控制方式
- 程序控制(查询)方式:分为无条件传送和程序查询方式两种。方法简单,硬件开销小,但I/O能力不高,严重影响CPU的利用率。
- 程序中断方式:与程序控制方式相比,中断方式因为CPU无需等待而提高了传输请求的响应速度。
- DMA方式:DMA方式是为了在主存与外设之间实现高速、批量数据交换而设置的。DMA方式比程序控制方式与中断方式都高效。
- 通道方式
- I/0处理机
- 以上方式从上往下效率越来越高
十八、设备管理-虚设备与SPOOLING技术
- SPOOLing是关于慢速字符设备如何与计算机交换信息的一种技术,通常称为“假脱机技术”。SPOOLing技术通过磁盘实现。
- 采用队列的方式处理等待数据
十九、数据库系统
一、三级模式-两层映射
二、数据库设计过程

三、E-R模型

- 矩形框代表实体
- 椭圆代表属性
- 菱形代表联系
- 矩形有两竖线代表弱实体,弱实体是某一实体的特殊化,使用一个圈两边线连接
1、1:1联系

2、1:n联系
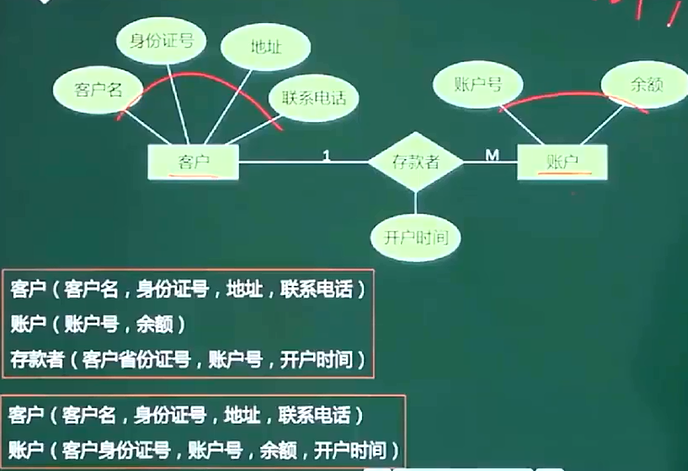
3、m:n联系
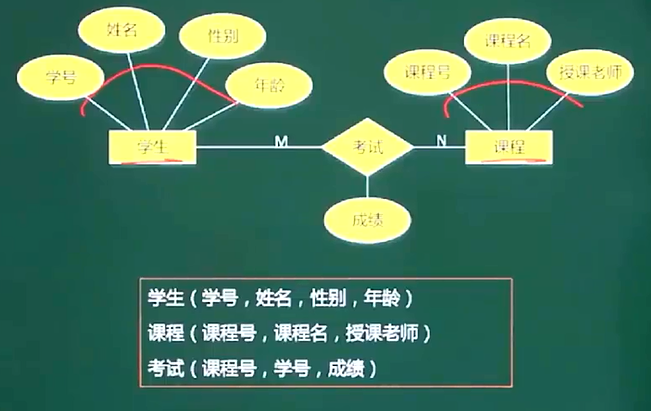
- 一个实体型转换为一个关系模式
- 联系转关系模式:
- 1:1联系:可将联系合并至任意一端的实体关系模式中
- 1:n联系:可以将联系合并至n端实体关系模式中
- m:n:联系必须单独转成关系模式
- 三个以上实体间的一个多元联系
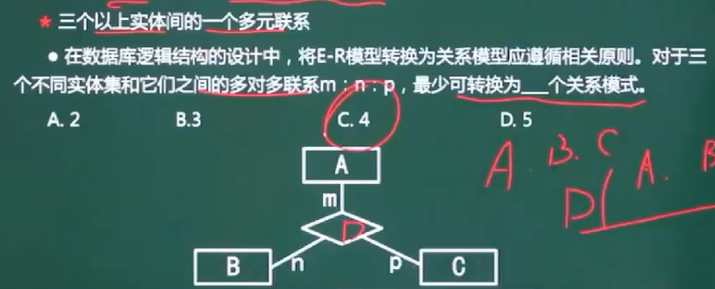
4、关系代数
-
并
-
交
-
差
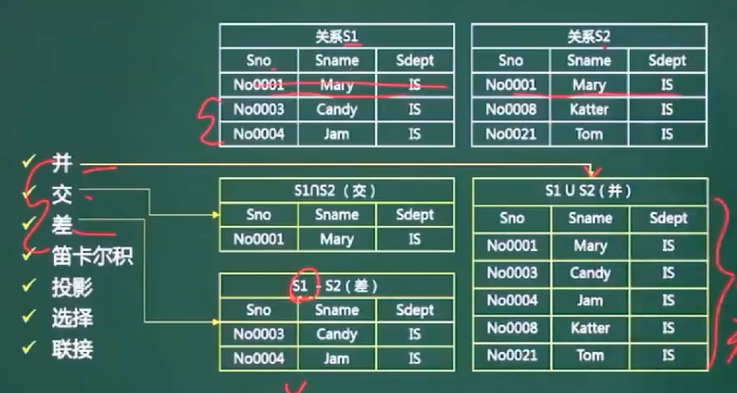
-
笛卡尔积
-
投影
-
选择

-
联接
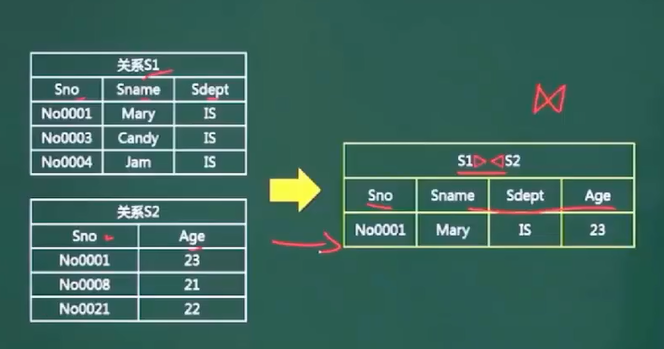
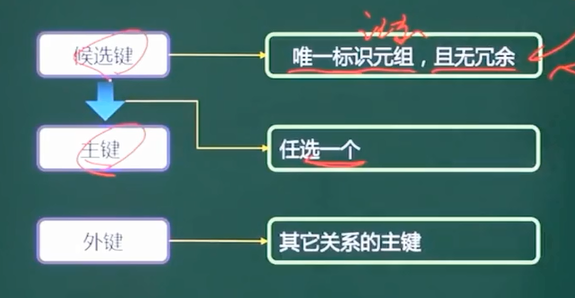
5、规范化理论-候选码
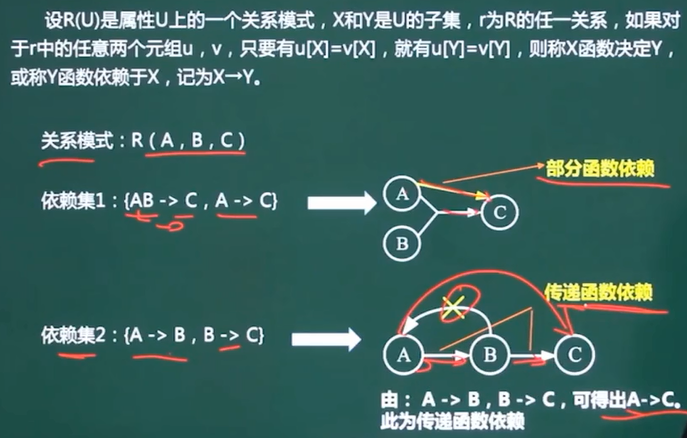

- 通过题目可以画出右边所示关系图,寻找0入度节点,然后看这个节点能否走完全程。

-
通过题目可以画出右边所示关系图,寻找0入度的节点,这道题候选码为ABDC
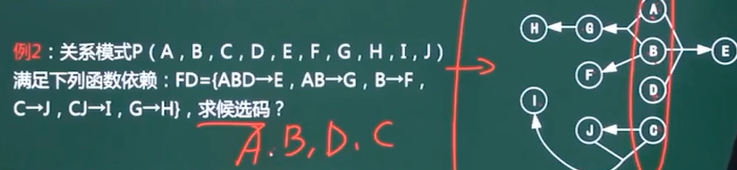
-
通过题目可以画出右边所示关系图,寻找0入度的节点,这道题有进有出的节点有A和B,这两个节点都可以遍历全图,所以答案为A和B

5、规范化理论-主属性

- 从关系中可以看出,(ST,City)可以推倒出zip为候选键,(ST,Zip)中,Zip可以推导出City,(ST,City)又可以推导出Zip。所以在这个例题中都是主属性。
5、规范化理论-范式
-
在系名称高级职称人数可以分为教授和副教授,不符合原子性,所以不满足1NF,如果要满足1NF则需要将教授和副教授拆分出来。
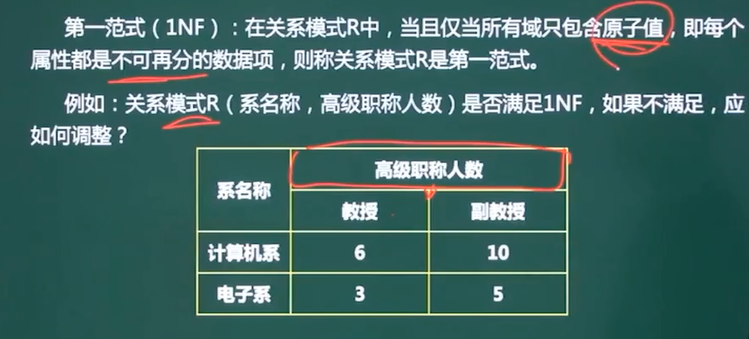
-
第二范式(2NF):当且仅当关系模式R是第一范式(1NF),且每一个非主属性完全依赖候选键(没有不完全依赖)时,则称关系模式R是第二范式。
-
第三范式(3NF):当且仅当关系模式R是第二范式(2NF),且R中没有非主属性传递依赖于候选键时,则关系模式R是第三范式。
-
BC范式(BCNF):设R是一个关系模式,F是它的依赖集,R属于BCNF当且仅当其F中每个依赖决定因素必定包含R的某个候选码。
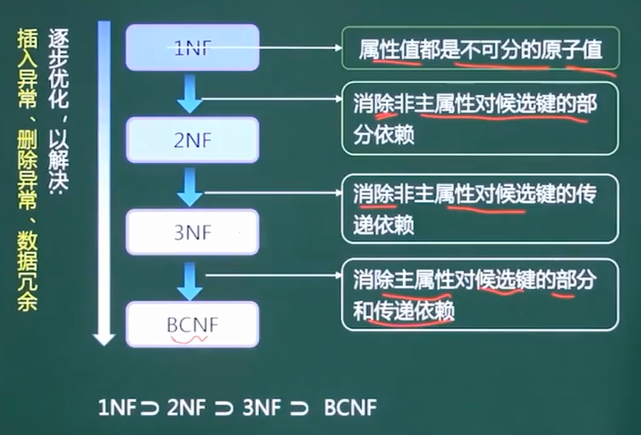
6、规范化理论-模式分解



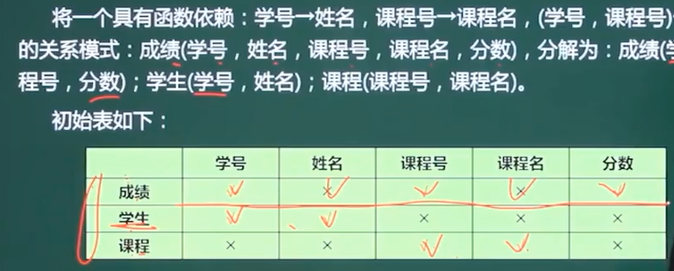

无损分解(公式法)
7、SQL
-
建表语句(掌握创建语句写法,主键,外键,关联等单词)

-
删除与修改

-
查询

-

8、并发控制
- 事务:原子性,一致性,隔离性,持续性
- 并发产生的问题:丢失更新,不可重复问题,读“脏”数据
- 解决方案:
- 封锁协议:S封锁,X封锁,两段锁协议
- 死锁:预防,死锁的解除
9、数据库完整性约束
-
实体完整性约束(主键:非空,唯一)
-
参照完整性约束(外键)
-
用户自定义完整性约束
√ 触发器
二十、计算机网络与信息安全
一、OSI/RM七层模型

TCP传输可靠性比较高的数据
ARP:地址解析协议
RARP:反向地址解析协议
ICMP:英特网控制协议
IGMP:组播协议,网关信息协议
二、TCP/IP协议族

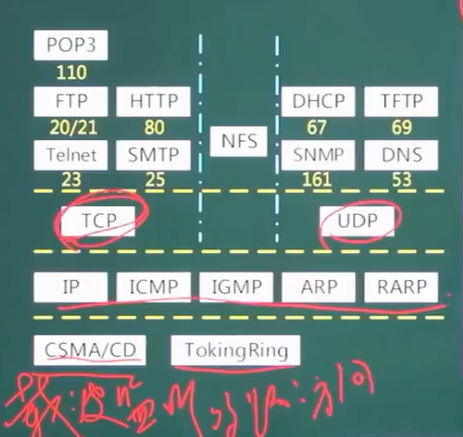
110、80等是端口地址

三、IP地址
- 五类IP地址(32位二进制)
- A类:起始位0,网络号7位,主机号24位 范围:0-127
- B类:起始位 1 0,网络号共16位,主机号16位 范围:128-191
- C类:起始位 1 1 0,网络号共24位,主机号8位 范围:192-223
- 可分配主机地址个数为2的主机号位数次方减2
四、子网划分
-
子网掩码
-
将一个网络划分为多个子网(取部分主机号当子网号)
-
将多个网络合并成一个大的网络(取部分网络号当主机号)
-
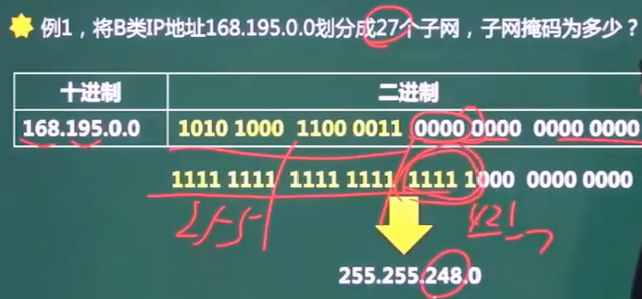
该题要划分27个子网,需要2的5次方,所以需要从主机位借5位当网络为,网络为全为1计算得出子网掩码。

由题意每个子网内有主机700台可以得出,2的10次方可满足需求,也就是说只需要10个主机位即可,多余6个主机位可以借给网络位。
五、网络规划与设计
- 需求分析
- 网络功能要求
- 网络的性能要求
- 网络运行环境要求
- 网络的可扩充性和可维护性要求
- 网络规则原则
- 实用性原则
- 开发性原则
- 先进性原则
- 网络设计与实施原则
- 可靠性原则
- 安全性原则
- 高效性原则
- 可扩展性原则
- 层次化网络设计
- 核心层 核心交换机
- 汇聚层 汇聚交换机
- 接口层 接入交换机
六、计算机网络分类
- 按分布范围分
- 局域网 LAN 10公里内
- 城域网 MAN
- 广域网 WAN
- 因特网
- 按拓扑结构分
- 总线型
- 星型
- 环型
七、网络接入技术
八、HTML
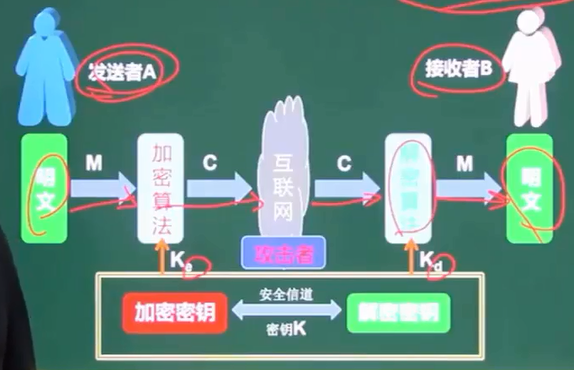
九、对称加密技术
-
特点:
- 加密强度不高,但效率高
- 密钥分法困难
-
常用对称密钥加密算法:DES、3DES、RC-5 、IDEA算法
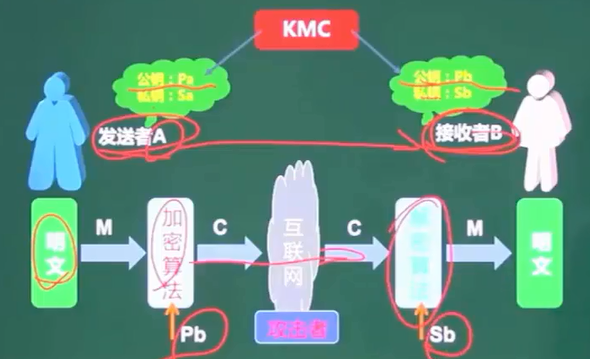
十、非对称加密技术
-
密钥必须成对使用(公钥加密,相对应私钥解密)
-
特点:加密速度慢,但强度高
-
常见非对称密钥加密算法:RSA、ECC
十一、数字签名

十二、消息摘要
常用的消息摘要算法:MD5,SHA等,市场上广泛使用的MD5,SHA算法的散列值分别为128和160位,由于SHA通常采用的密钥长度较长,因此安全性高于MD5。

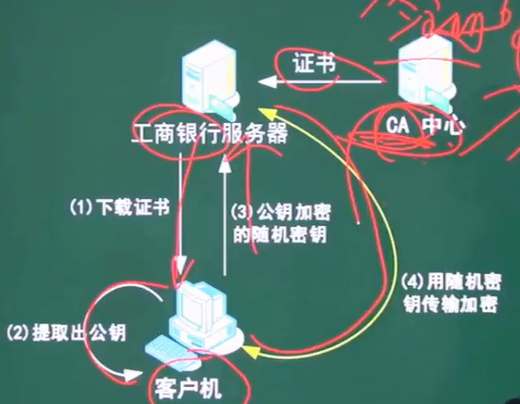
十三、PKI公钥体系
十四、网络安全-各个网络层次的安全保障
- 物理层
- 隔离
- 屏蔽
- 数据链路层
- 链路加密
- PPTP
- L2TP
- 网络层
- 防火墙
- IPSec
- 传输层
- TLS TLS是基于SSL的3.0协议
- SET
- 应用、表示、会话层
- PGP 加密邮件协议
- Https 网页访问
十五、主动攻击与被动攻击
- 被动攻击
- 监听(保密性)
- 消息内容获取
- 业务流分析
- 监听(保密性)
- 主动攻击
- 中断(可用性)
- 篡改(完整性)
- 伪造(真实性)
十六、Dos(拒绝服务)与DDos
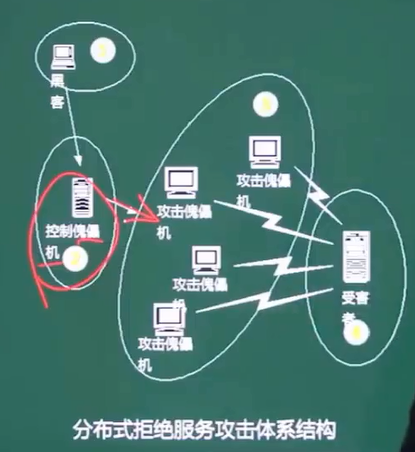
黑客利用傀儡机对某服务器不断进行请求,导致服务器崩溃无法处理真实请求。
十七、木马与病毒
- 木马是窃取信息,将信息传输到黑客可以接收到的位置
- 病毒是直接破坏计算机
二十一、系统开发基础
一、软件开发模型
-
瀑布模型
适用于需求比较明确的项目,要很少发生需求变更。一开始需求要明确,否则发生需求变更将导致延期甚至无法完成。瀑布模型的每个阶段都有产出,可行性分析文档,需求分析文档,系统概要设计文档,详细设计文档等。
软件计划-需求分析-软件设计-程序编码-软件测试-运行维护
-
V模型
需求分析-概要设计-详细设计-编码-v模型-单元测试-集成测试-系统测试-验收测试
单元测试测试的是编码,以详细设计为依据
集成测试测试详细设计,以概要设计为依据
系统测试测试概要设计,以需求分析为依据
验收测试是以用户为主导的测试。
和瀑布模型一样,同样把测试放在了编码完成以后,一旦测试不通过,编码出现问题,则需要推倒重来,产生维护成本高。
-
喷泉模型
面对对象开发模型,每个阶段没有明确的界限,可以几个阶段并行,一定程度上提高开发效率,节约成本。在管理方面更加严格。
分析-设计-实现-测试-维护-演化
-
原型化模型
通过与用户沟通产生原型
- 探索模型
- 实验模型
- 演化模型
-
螺旋模型
螺旋模型综合了瀑布模型和原型的优点,强调的是有风险的分析,原型模型适合开发高风险项目。缺点在于风险分析阶段成本会增加。
-
统一过程 RUP
用例驱动,以架构为中心,迭代和增量
初始-细化-构建-交付
-
初始
确定项目范围和边界,识别系统的关键用例,展示系统的候选架构,估计项目费用和时间,评估项目风险
-
细化
分析系统问题领域,建立软件架构基础
-
构建
开发剩余的构建,构建组装
-
交付
进行验收测试,制作发布版本,用户文档定稿,确认新系统,培训、调整产品
-
-
敏捷方法
-
XP 极限编程
在一些对费用控制严格的公司中使用,被证明非常有效
-
Cockburn水晶系列方法
用最少的纪律约束而仍能成功的方法,从而在产出效率与易于运作上达到一种平衡
-
开发式源码
程序开发人员在地域上分布很广
-
SCRUM 并列争求法
明确定义了可重复的方法过程,为明确定义了的可重复的人员所用,去解决明确定义了的可重复的问题。
-
Coad的功用驱动开发用法
-
ASD方法
自适应软件开发方法,核心是三个非线性的,重叠的开发阶段:猜测、合作与学习。
-
二、软件开发方法
-
结构化方法(面向数据流的方法)
用户至上
严格区分工作阶段,每阶段有任务和结果
强调系统开发过程的整体性和全局性
系统开发过程工程化,文档资料标准化
自顶向下,逐步分解(求精)
不适用与开发大型复杂的项目
-
原型法
-
面向对象方法(喷泉模型)
更好的复用性
关键在于建立一个全面、合理、统一的模型
分析、设计、实现三个阶段,界限不明确
-
面向服务的方法 SOA
三、需求分析
-
需求的任务
-
需求的过程
问题识别
分析与综合
编制需求分析文档
需求分析与评审
-
需求的分类
功能需求
非功能需求
设计约束
-
应用的工具
数据流图(DFD)
数据字典(DD)
判定表
判定树(决策树)
四、软件设计
- 高内聚,低耦合
- 应用工具
- IPO图
- PDL
- PAD
- 程序流程图
- N/S盒图
- 内聚由高到低(考察排序或通过描述选择内聚类型):
- 功能内聚:完成一个单一功能,各个部分协同工作,缺一不可
- 顺序内聚:处理元素先关,而且必须顺序执行
- 通信内聚:所有处理元素集中在一个数据结构的区域上
- 过程内聚:处理元素相关,而且必须按特定的次序执行
- 瞬时内聚(时间内聚):所包含的任务必须在同一时间间隔内执行
- 逻辑内聚:完成逻辑上相关的一组任务
- 偶然内聚(巧合内聚):完成一组没有关系或松散关系的任务
- 耦合类型由低到高:
- 非直接耦合:两个模块之间没有直接关系,他们之间的联系完全是通过主模块的控制和调用来实现的
- 数据耦合:一组模块借助参数表传递简单数据
- 标记耦合:一组模块通过参数表传递记录信息(数据结构)
- 控制耦合:模块之间传递的信息中包含用于控制模块内部逻辑的信息
- 外部耦合:一组模块都访问同一全局简单变量,而且不是通过参数表传递该全局变量的信息
- 公共耦合:多个模块都访问同一个公共数据环境
- 内容耦合:一个模块直接访问另一个模块的内部数据;一个模块不通过正常入口转到另一个模块的内部;两个模块有一部分程代码重叠;一个模块有多个入口
二十二、软件设计师复习资料分享
- 关注微信公众号“励码万言”回复“软考”获取2021复习资料,都是我软考复习期间收集的资料,非常全面,希望能帮到大家~


 浙公网安备 33010602011771号
浙公网安备 33010602011771号