
Netty ByteBuf源码分析
Netty的ByteBuf是JDK中ByteBuffer的升级版,提供了NIO buffer和byte数组的抽象视图。
ByteBuf的主要类集成关系:
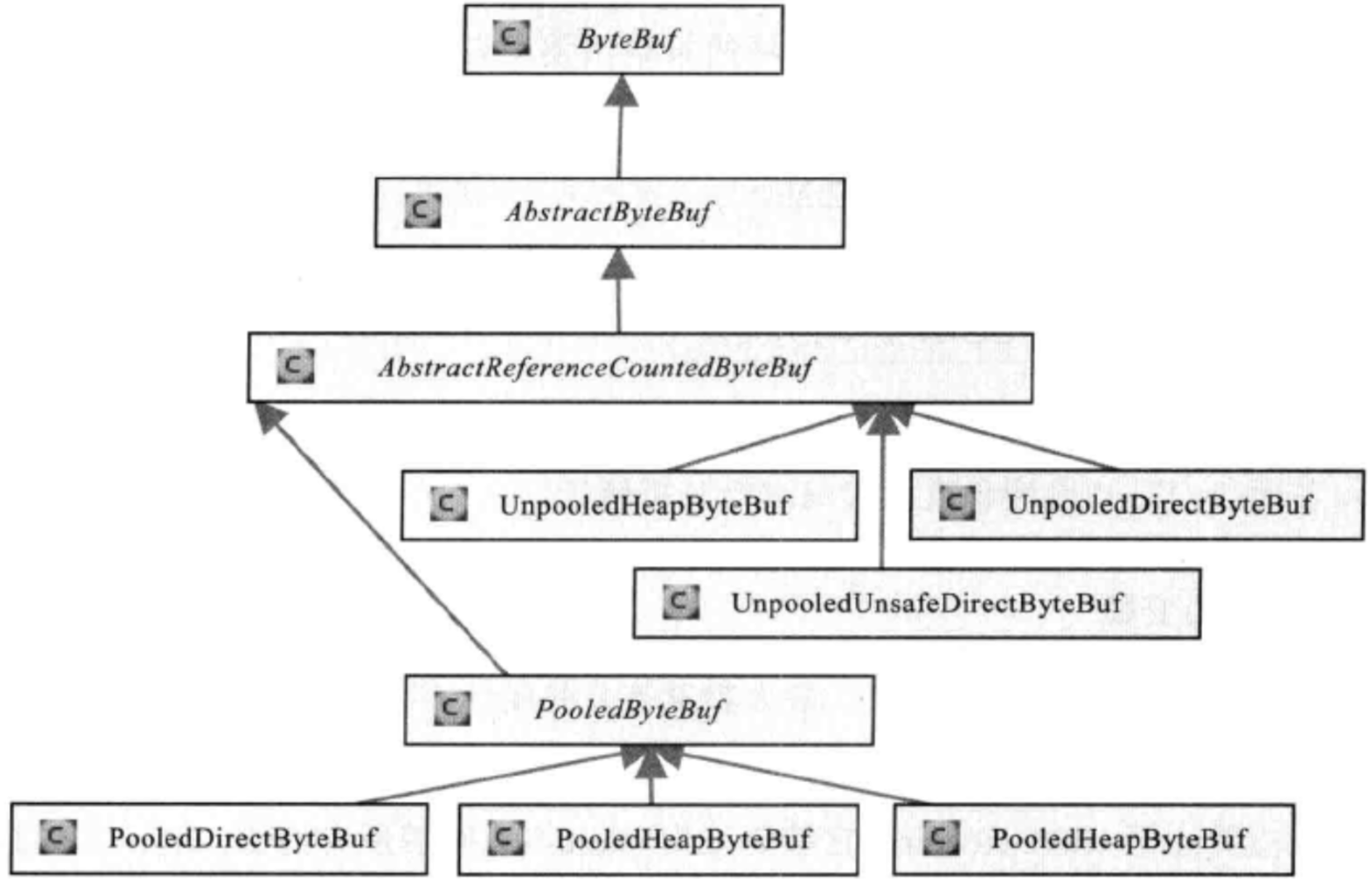
(图片来自Netty权威指南,图中有一个画错的地方是PooledByteBuf中的最后一个子类应该是PooledUnsafeDirectByteBuf)
从继承关系可以看出AbstractReferenceCountedByteBuf的子类分为两类:Pooled和Unpooled的ByteBuf。
Pooled ByteBuf是基于对象池的ByteBuf(会被缓存),Unpooled则是普通的ByteBuf对象。
无论是否基于内存池的ByteBuf,它的子类有分为DirectByteBuf和HeapByteBuf分别表示在堆外内存分配的缓冲区和在堆内存的缓冲区。
堆内存缓冲区的特点是分配和回收速度快,可以被JVM自动回收;缺点是如果进行Socket的IO读写,需要额外做一次内存复制。
堆外内存的缓冲区相对于堆内存的缓冲区,分配和回收的速度会慢一些,但是将它写入或从Socket Channel读取数据是,会少一次内存复制,速度比堆内存更快一些。
BufferBuf也提供了一类API来将自己转化成为ByteBuffer以便于在需要ByteBuffer的地方进行操作。
AbstractByteBuf
AbstractByteBuf定义了ByteBuf的基础属性和一些公用的方法。
主要成员变量有:
readerIndex
writerIndex
markedReaderIndex
markedWriterIndex
maxCapacity
可以看到ByteBuf中分别定义了读写游标,也就是说读游标和写游标是分离的,这相对于ByteBuffer只使用一个position,在读写操作时会便利很多。

一块缓冲区会被两个游标分隔为三块区域,分别是已经读取过的、可读的、剩余可写的。
在写入数据后可以直接开始读取,不需要flip操作。
另外AbstractByteBuf中的方法分为三类:
读取数据、写入数据、操作游标
读取操作分为readXXX和getXXX,以读取Long为例,
readLong()方法在当前readerIndex位置读取8个Byte并增加readerindex的值;
getLong(int index)则需要接收一个index参数,从index位置开始读取8个Byte,get操作不会改变readerIndex的值。
写入操作也有两类,分别是setXXX和writeXXX,
writeLong(long value)方法在当前writerIndex位置开始写入一个Long值并增加writerIndex的值;
setLong(int index, long value)方法则接收一个index参数作为写入的位置,写入操作不修改writerIndex的值。
索引操作就是通过setReaderIndex之类的方法改变readerIndex的值来重新读取数据,非常简单,不做说明。
AbstractReferenceCountedByteBuf
从类名上看,AbstractReferenceCountedByteBuf主要是实现了对引用的计数,类似于JVM内存回收的对象引用计数器,用于跟踪对象的分配和销毁。

只有一个成员变量:refCnt,看命名也知道是用于计数的,并且用AtomicIntegerFieldUpdater来实现线程安全的计数。 
retain API用于增加引用的计数。

release则用于减少计数值。

定义deallocate方法让子类去实现当引用计数为0时的操作(由子类实现具体的“回收”操作)。
UnpooledHeapByteBuffer
UnpooledHeapByteBuffer是不适用对象池,且直接在堆内存上分配的缓冲区。 
ByteBufAllocator alloc:创建了这个缓冲区的分配器
byte[] array:底层存储
ByteBuffer tmpNioBuf:Nio ByteBuffer对象,用于将自身转换成一个ByteBuffer对象
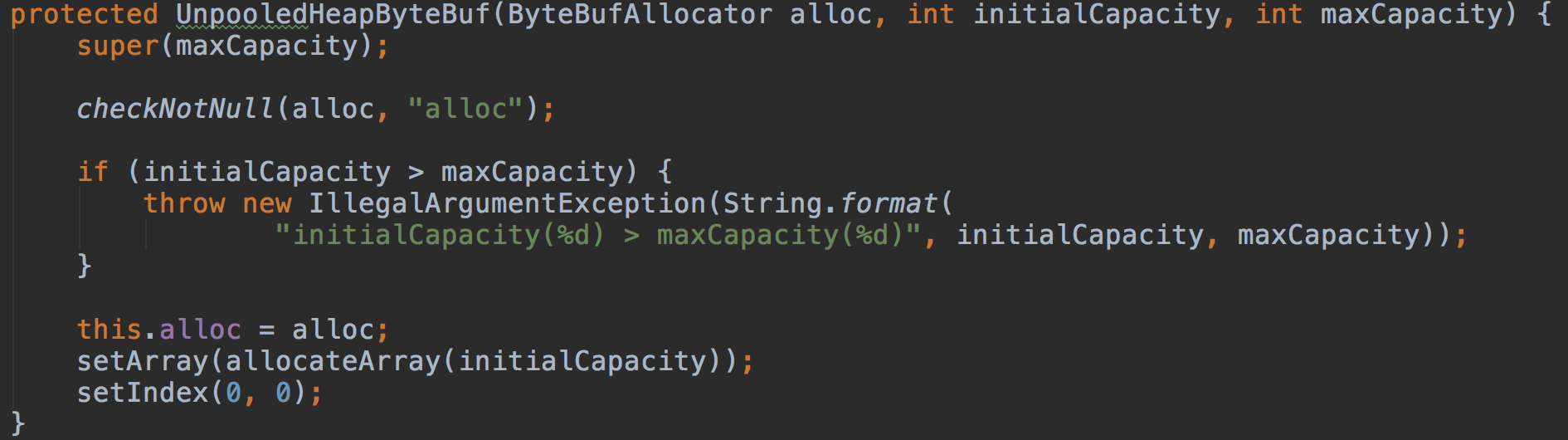
构造方法非常简单:
记录分配器alloc;
初始化数组;
将读写位置调整为0;
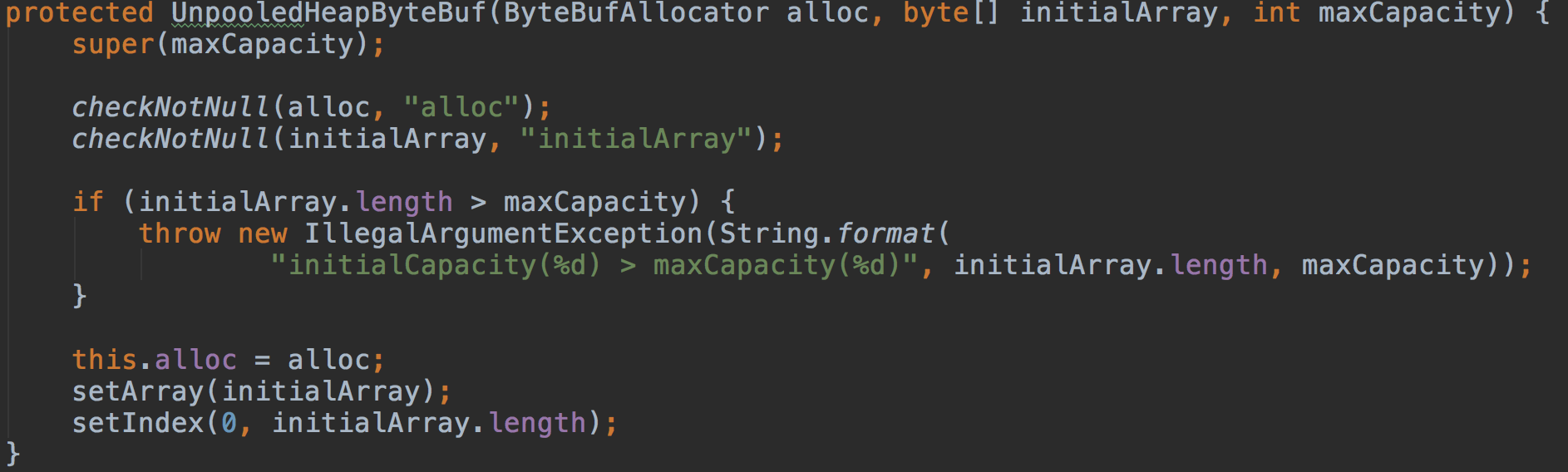
这个构造方法则是传入byte数组做初始化,writerIndex调整到数组后的第一个位置。
两个构造方法都有maxCapacity参数,且初始容量要么是initialCapacity要么是initalArray的长度,说明缓冲区的大小是可以调整的,最大不超过maxCapacity。
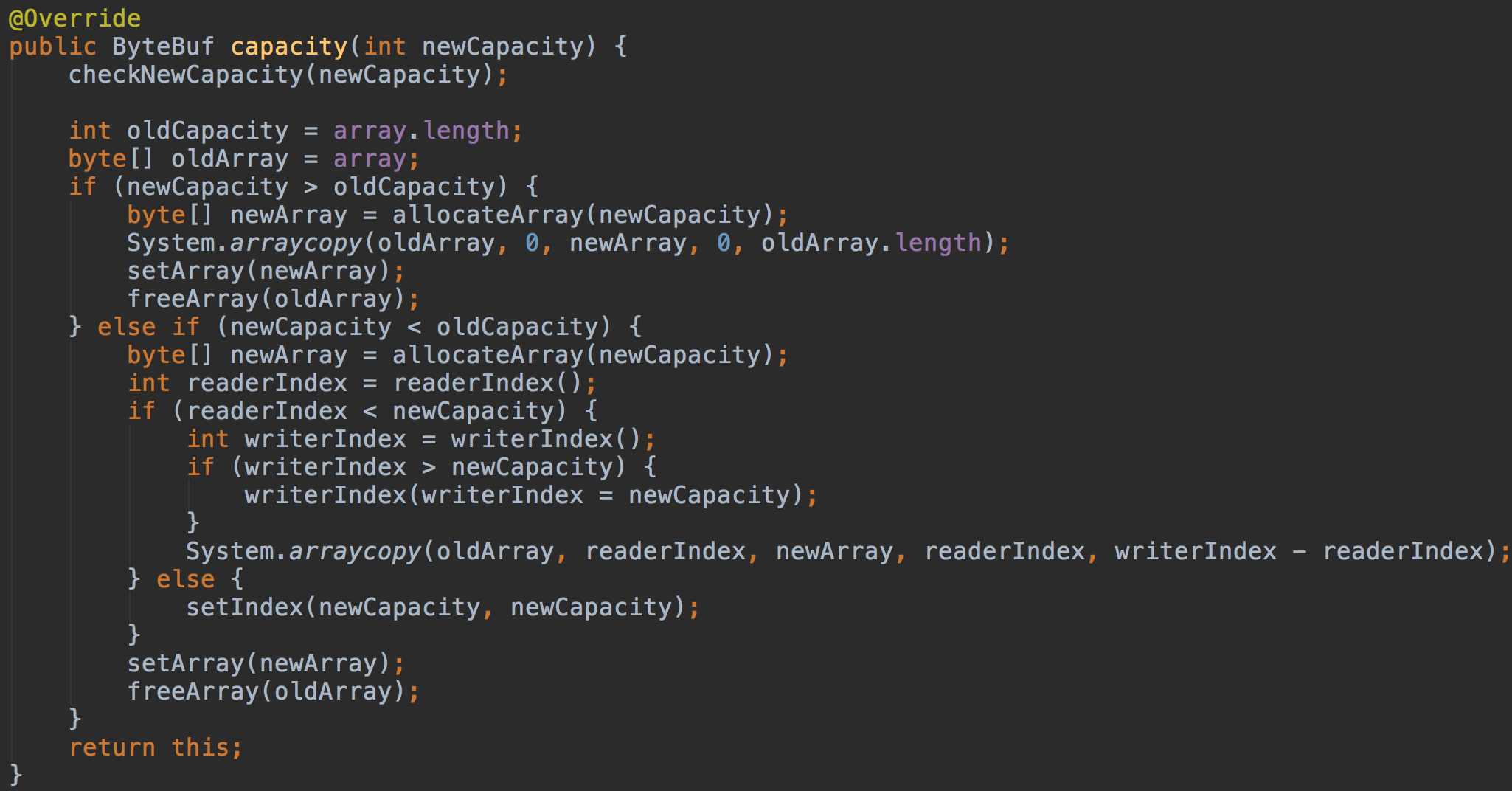
通过capacity来调整缓冲区的大小。如果newCapacity小于当前array的length,那么会有部分数据被丢弃。如果newCapacity超过array的length,那么新扩容的位置数据未空。
UnpooledDirectByteBuf

ByteBufAllocator alloc:使用的分配器
ByteBuffer buffer:内部用于存储数据的结构
ByteBuffer tmpNioBuf:临时的ByteBuffer,在将自己转换成ByteBuffer对象时会使用
int capacity:容量
doNotFree:标志ByteBuffer是否可以回收
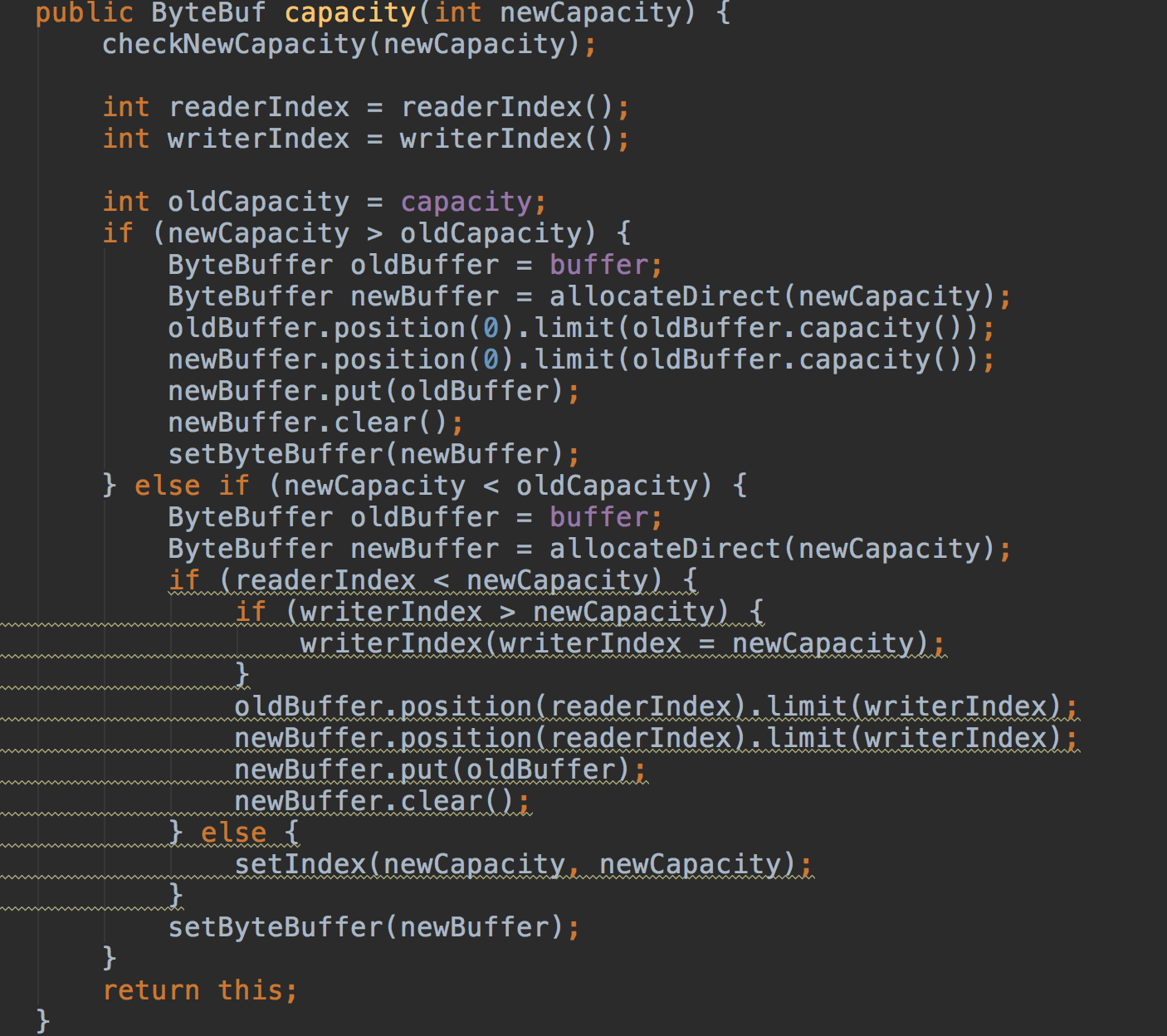
区别于UnpooledHeapByteBuf,UnpooledDirectByteBuf的扩容操作不在是申请数组进行数据拷贝,而是申请新的ByteBuffer之后进行收拷贝,而ByteBuffer一定是Direct的。
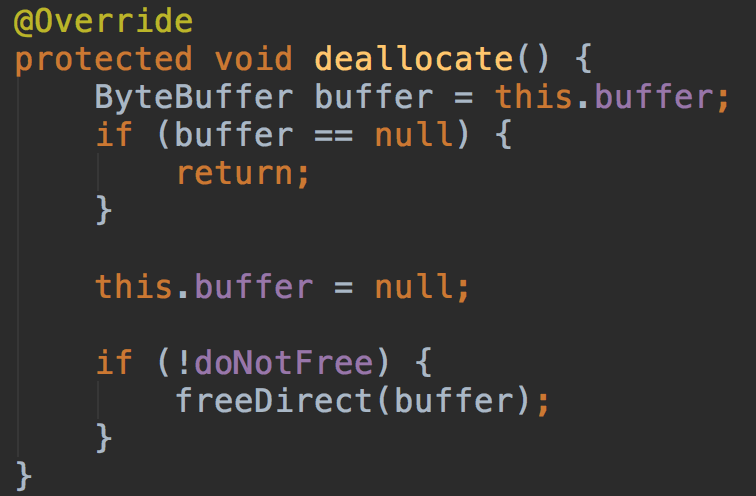
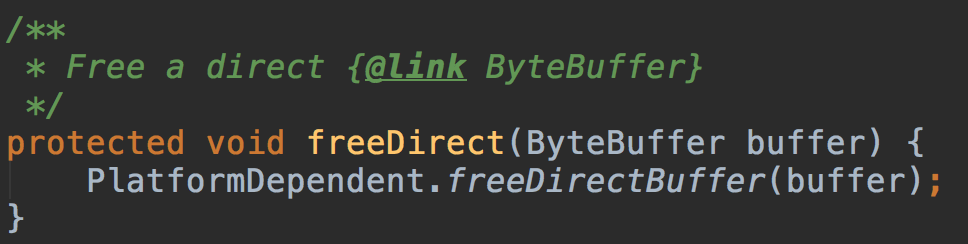
deallocate实现了底层存储ByteBuffer的回收操作,即在引用计数为0时将DirectByteBuffer回收掉(DirectByteBuffer的内存是由自己回收的,而不是JVM)。
UnpooledUnsafeDirectByteBuf
UnpooledUnsafeDirectByteBuf和UnpooledUnsafeDirectByteBuf的区别在于UnpooledUnsafeDirectByteBuf直接使用ByteBuffer来操作数据,而UnpooledUnsafeDirectByteBuf采用Unsafe来操作数据。
UnpooledUnsafeDirectByteBuf的_getLong实现:
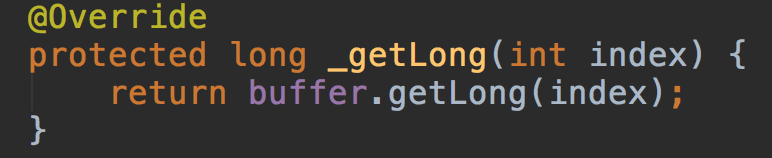
UnpooledUnsafeDirectByteBuf的_getLong实现:

AbstractReferenceCountedByteBuf子类的另一个分支是PooledByteBuf,即使用对象池,会被缓存的ByteBuffer。
PooledByteBuf有三个子类:
PooledHeapByteBuf
PooledDirectByteBuf
PooledUnsafeDirectByteBuf
他们分别和Unpooled的几个子类对应。
对于Pooled的实现,详见Netty对象池实现分析。
欢迎关注我的个人公众号,会写一些列关于消息中间件的文章,也欢迎交流任何技术问题,或者扯扯淡。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号