2017上海QCon之旅总结(上)
本来这个公众号的交流消息中间件相关的技术的。这周去上海参加了QCon,第一次参加这样的技术会议,感受挺多的,所以整理一下自己的一些想法接公众号和大家交流一下。
下面进入正题,从自己参加了的一些分享中挑一些有趣的议题来和大家讨论。
《“深蓝”20年之后的人工智能》
2017年可以说是人工智能的元年了,AlphaGo战胜李世石然人工智能一下进入了大众的视野。之后以Master的身份60连胜,接着战胜长期世界排名第一的柯洁,QCon期间AlphaGo Zero通过3天自学的方式就以100:0的方式战胜了AlphaGo,可以说在棋类领域人类对人工智能已经没有任何胜算了。
这次QCon,复旦大学的危辉教授从人工智能的历史说起,之后从人工智能的问题域、解题步骤步步深入,清晰的描述了目前人工智能领域的进展。
危辉教授的《“深蓝”20年之后的人工智能》分享可能从听众的感受上有点“反”人工智能热潮,但是我认为这场分享是给人工智能的门外的我们一个很好的入门介绍,让我们明白目前人工智能领域的发展状况,让我们对遍地的人工智能现象有一个清晰的任务。
另外危辉教授演讲的逻辑性、严谨性和现场把控能力,真的是单从一场分享能感受到功底的深厚。
这场分享的PPT没能从QCon网站上下载到,并不能回忆起很多具体的分享内容,以上是个人现场感受的一些体验。
《免费的性能午餐——Alibaba JDK协程》
这一场是阿里巴巴技术专家郁磊带来关于Alibaba JDK协程的介绍。
在参加这次分享之前,我对协程并没有什么概念(没写过C++程序)。这场分享下来只能说有个简单的认识,另外就是感叹于阿里的同学在这块技术领域的深入。
不过就目前的状况,对我们这样一些小公司而言,可能并没有技术能力去修改JVM,短期内的编程方式并不会有太大的改变。可能当协程成为一种标准,一种官方提倡的编程方式之后才会慢慢进入大众程序员的领域(那为什么不提前学习一些呢?)。
《基于内存的分布式计算》
这是这次QCon去听的第一个具体问题领域的解决方案。
包含内容如下:
- 背景介绍及问题阐述
- 候选解决方案分析
- 分布式内存计算框架介绍
- 客户实践
这里我简要的说一下第1点和第3点。
问题背景
Talking Data技术团队使用bitmap索引技术移动运营各项指标(如日活、留存)的实时计算,因为bitmap索引高效且能节省存储空间,它能很方便地做指标的实时排重。

上面是日活的一个例子,其实就是用一个二进制位来保存用户的状态。比如第一位表示用户设备1,该位为0表示用户未登录过,为1表示用户登录过。那么用户重复的登录自然就被忽略了。
Talking Data使用MySQL的blob类型存储bitmap数据,那么每次需要更新数据时,如需要更新某一个用户的状态,那么需要将bitmap读取出来,修改其中一位,之后将数据写回到MySQL中。那么就带来了一个问题,当某个APP的日活数据量特别大时,bitmap数据特别大,频繁的update导致了产生大量的MySQL binlog。
解决方案
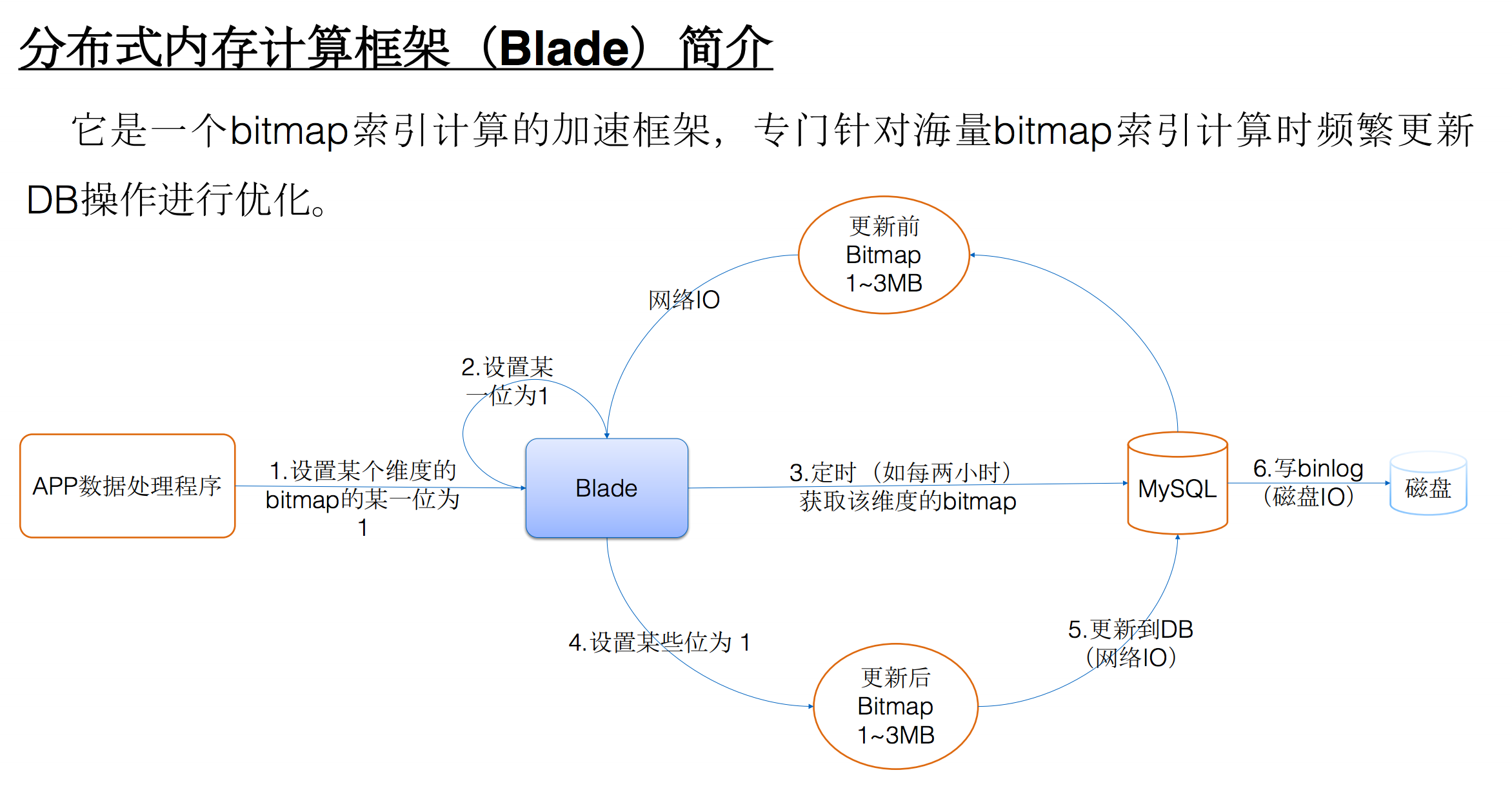
大概思路就是在MySQL之前加上一层缓存,前端的更新操作都在Blade内存中操作,之后定时同步写到MySQL中,这样就解决了频繁更新bitmap导致的大量binlog问题。
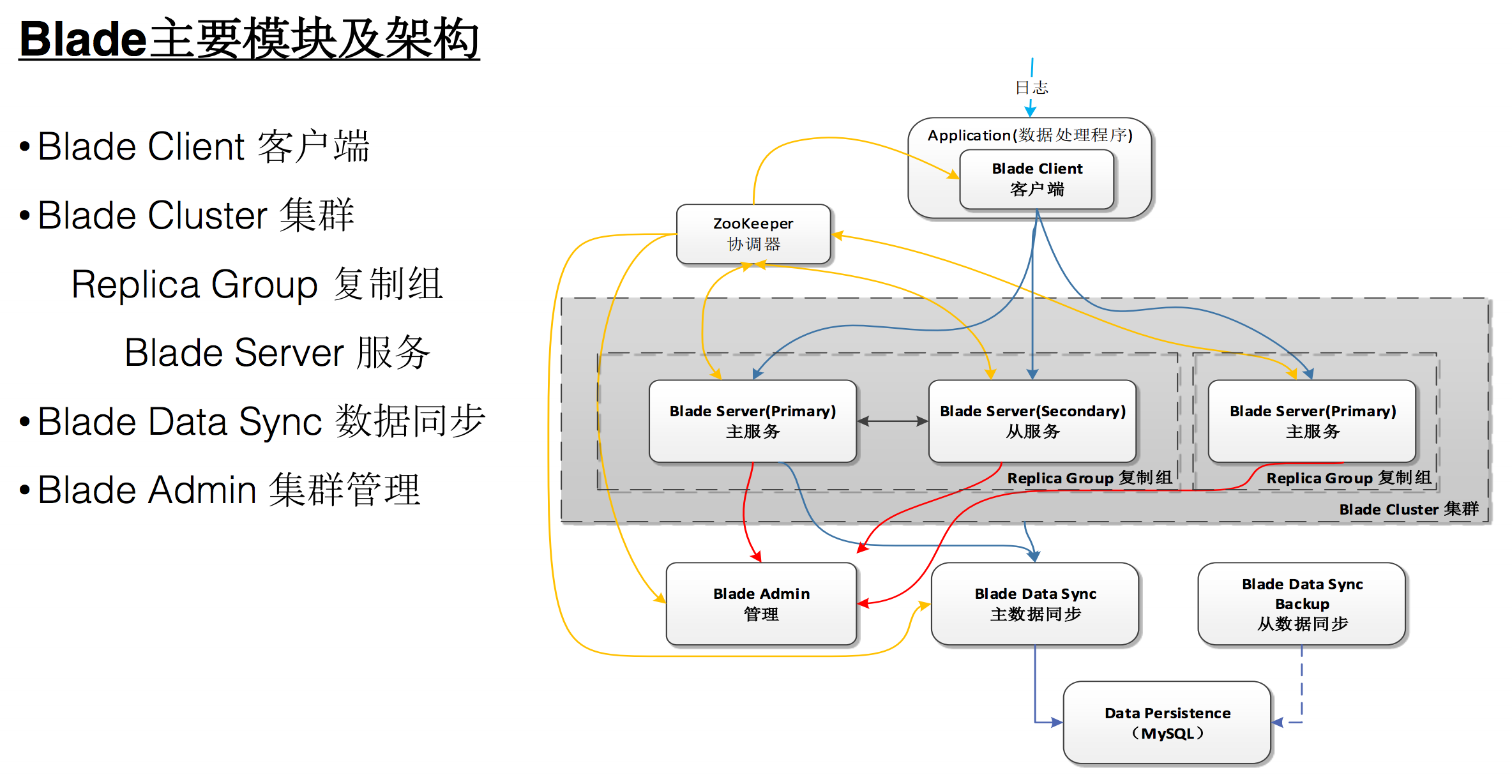
几个组件如上图:
- APP中使用的Client
- 内存计算服务Blade Server(分为Master和Slave)
- Blade Data Sync负责从Server定时同步数据到MySQL
- Blade Admin提供管控功能
上图中Blade Server有主备关系,且主备间有交互。
现场提问环节,我提了以下几个问题:
- 主从复制是怎么做的、支持一主多从吗?
- Blade Server是基于内存的,没有做持久化,那么可么保证系统的可靠性,比如如果主从两个节点宕机了,未同步到MySQL的数据是否就丢失了?
得到的答复是目前他们并没有做主从复制,当前其实是双写的模式,即Client会将数据写到Master和Slave。这样也就没有第二个问题的处理了。
对于分布式系统,认为首先要考虑的就是系统的可靠性和可用性。
我们常常说的一点就是为了保证数据的可靠性,我们需要一式三份,而且是尽量让三分数据分不到不同机器中,比如同机柜的机器存一份,跨机柜的存一份,像HDFS那样存储数据。
所以我觉得上面的方案并不是一个很可靠的方案。
比如使用消息中间件的方式是否能代替上面的方案呢?
客户端将消息发送到消息中间件中,类似于RocketMQ和Kafka这样的组件中,之后通过Consumer定时从中取消费数据来解决频繁更新的问题(数据的可靠性通过消息中间件得到了保证)。
也可启动实时消费的Consumer来消费数据更新到某个内存服务中,这样可以提供实时的查询服务。
以上是自己的一些疑问和拍脑袋的一个替代方案,欢迎交流不同的想法。
《饿了么异地多活的基础设施建设》
之前我们团队考虑过一些异地多活的实现方案,所以特地去听了这场分享。
之前在自己考虑异地多活方案时,遇到的最大的问题是数据同步和数据一致性。
下面看饿了么是如何实现基地多活的。
首先是饿了么的业务特点:

其中最重要的一点就是地域性。
饿了么的业务特点,可以将所有数据按照商户所在的位置信息来进行划分。
比如所有南方商户的数据走上海机房,所有北方商户的数据走北京机房。对于用户和订单信息,都可以关联到对应的商家,然后访问商家对应所在的机房的服务。
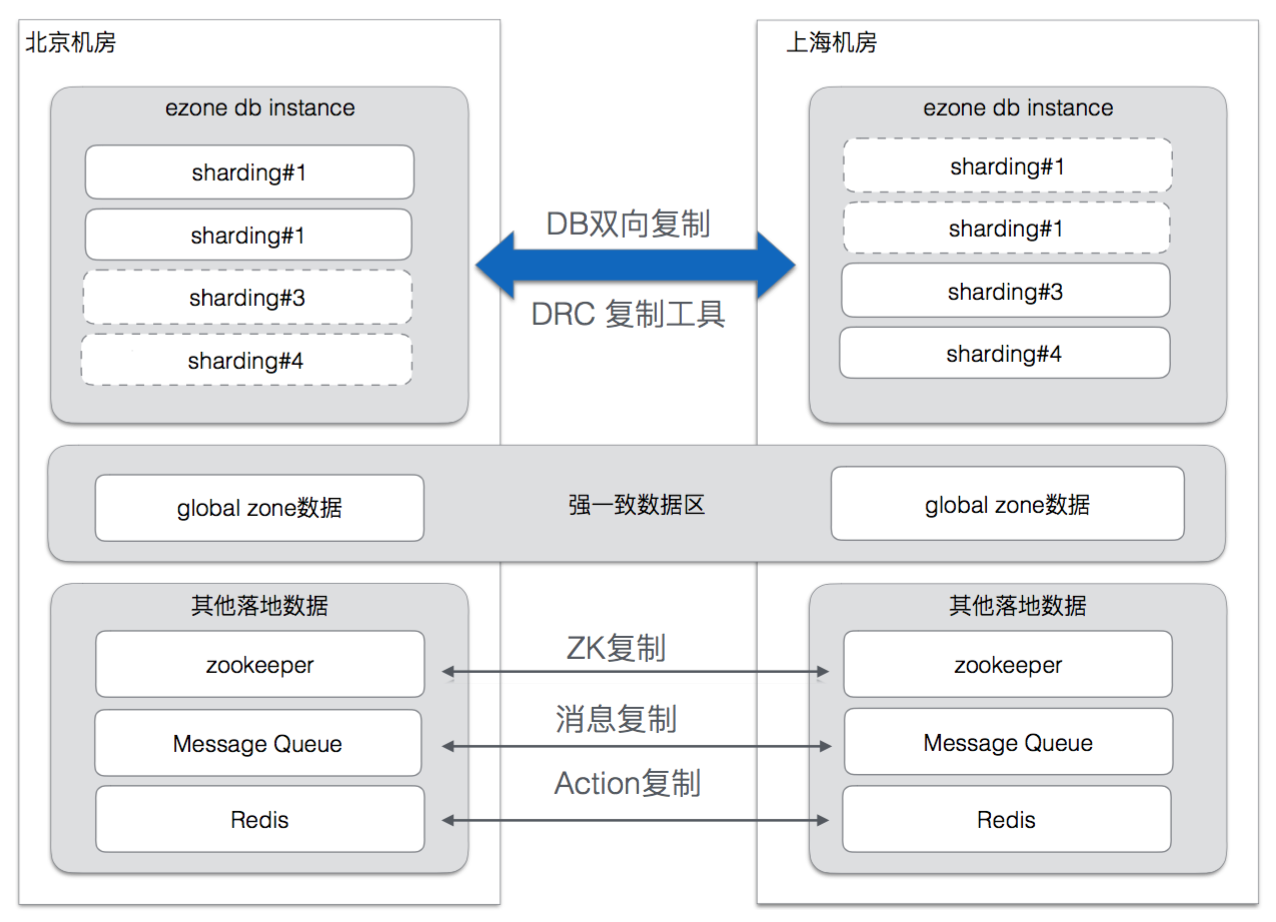
上面是饿了么异地多活的数据复制实现。思路就是在两个机房之间进行双向的数据复制。
回想一下,因为饿了么的业务特点,双向复制的数据中不会有重叠的部分。
- 从北京机房往上海机房复制的是北方商户的数据
- 从上海机房到北京机房复制的是南方商户的数据
- 在复制中过滤掉不必要的数据,比如从上海复制到北京的数据,这部分数据应用到MySQL之后也会产生binlog,这部分binlog需要从北京复制到上海的数据中剔除(这个通过改造SQL或者增加标识是可以做到的)
这样就避免掉了一个数据在两个机房同时被修改的问题。
扩展
考虑一个问题,比如在电商场景中做异地多活。
对于一个商品,在北京机房和上海机房都会被访问,这个时候就产生了一个问题:
- 商品的库存为1,北京机房下了一单,将商品库存变更为0;同时上海机房也下了一单,也将库存变更为0。这样就产生了超卖的问题。
- 另外,如何在双向数据同步中将上线的数据修复,即使其中一个订单失效,将库存修复也会一个问题。
Otter
阿里巴巴B2B公司,因为业务的特性,卖家主要集中在国内,买家主要集中在国外,所以衍生出了杭州和美国异地机房的需求,同时为了提升用户体验,整个机房的架构为双A,两边均可写,由此诞生了otter这样一个产品。
Otter在解决数据一致性问题时(同一行记录多地修改),有两种方案:
- 事前控制:比如paoxs协议,在多地数据写入各自数据存储之前,就已经决定好最后保留哪条记录
- 事后补救:指A/B两地修改的数据,已经保存到数据库之后,通过数据同步后保证两数据的一致性
两种方式都是数据最终一致性的保证,具体内容可以参考:Otter数据一致性解决方案
未完待续...
QCon3天,还有挺多想和大家分享的,所以还有下篇,包含《PhxQueue——微信开源高可用强一致分布式队列的设计与实现》、《Heron的Exactly-Once实现》几个议题的分享感受。
欢迎关注公众号交流。
2017QCon上海站PPT下载:PPT


 浙公网安备 33010602011771号
浙公网安备 33010602011771号