Python 数据分析预测商品销售额
一、选题的背景
选择此题: 题目来源于Kaglge竞赛平台,具有一定的学习意义。可以更好的理解机器学习和数据分析的券过程。
目标:根据商店的销售数据预测商品的销售额
社会: 通过机器学习帮助商店老板做出决策,可以提供货物的资源利用率,促进社会经济发展。
经济: 通过对销售额的预测,可以更好的帮助老板进货和销售,提高商店的收益。
技术: 通过这一次的项目的学习,可以学到机器学习,数据挖掘的全部流程。从数据获取,到数据处理,特征选择,模型建立各个方面全面掌握机器学习的流程。可以更深入对机器学习总回归任务的理解。
二、大数据分析设计方案
1.数据集描述:训练集样本个数:8523, 测试集样本个数:5681。

2.项目实现的主要思路
三、数据分析步骤
1.数据源
数据来源https://datahack.analyticsvidhya.com/contest/practice-problem-big-mart-sales-iii/
2.数据清洗

(2)统计 Outlet_Size 特征所有的变量,结果如下图所示,商店大小有三种类型,按如下规则:Small : 用数值 1 代替;Medium: 用数值 2 代替;High: 用数值 3 代替

(3)统计 Outlet_Location_Type 特征所有的变量,结果如下图 ,商店地域有三种类型,按如下规则:Tier1: 用数值 1 代替;Tier2: 用数值 2 代替;Tier3: 用数值3 代替

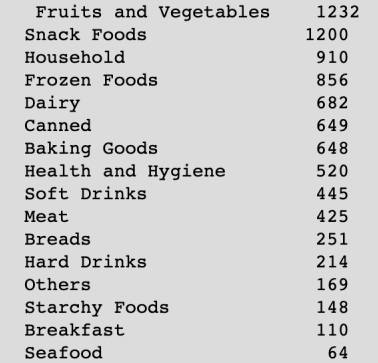
(4)统计 Item _Type 特征所有的变量,结果如下图,发现有 16 种类型的变量,我们第一次尝试将这 16 种类型映射到 1-16 共 16 个整数上,后来参考网上的其他人的做法,将这 16 种划分为 3 大类,食物(Fruits and Vegetables, Snack Foods,Meat, Baking Goods, Bread, Breakfast, Frozen Foods, Dairy, Starchy Foods),日用品(Household, Others, Health and Hygiene)酒水(Soft Drinks, HardDrinks)。处理完的特征较原来的特征模型分数有所提高
1 import pandas as pd 2 import numpy as np 3 import matplotlib.pyplot as plt 4 import seaborn as sns 5 6 from math import sqrt 7 from sklearn.metrics import mean_squared_error # 计算均方误差 8 from sklearn.metrics import make_scorer 9 from sklearn.model_selection import train_test_split 10 11 from sklearn.model_selection import GridSearchCV, RepeatedKFold, cross_val_score,cross_val_predict,KFold 12 from sklearn.ensemble import RandomForestRegressor, GradientBoostingRegressor,AdaBoostRegressor 13 from sklearn.linear_model import LinearRegression, Lasso, Ridge, ElasticNet 14 15 import warnings 16 warnings.filterwarnings("ignore") 17 %matplotlib inline 18 %config InlineBackend.figure_format = 'svg'
导入数据集
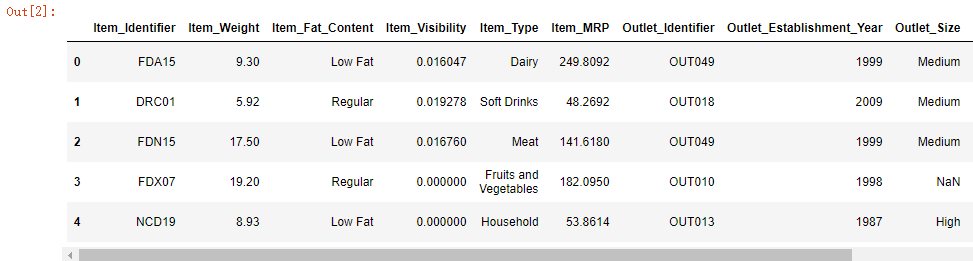
1 train_data = pd.read_csv("train_data.csv") 2 test_data = pd.read_csv("test_data.csv") 3 train_data.head() 4 # len(test_data)
数据数值化操作
1 def small_class_num(data): 2 try: 3 #Item_Fat_Content 4 Item_Fat_Content = {'Low Fat':0, 'Regular':1,"LF":0,"reg":1,"low fat":0,} 5 data["Item_Fat_Content"] = data["Item_Fat_Content"].apply(lambda x: Item_Fat_Content[x]) 6 #Outlet_Size 7 # Outlet_Size = {'Small':1, 'Medium':2, 'High':3,'NONE':4} 8 # data["Outlet_Size"].fillna("NONE",inplace=True) #填充缺失值 9 # data["Outlet_Size"] = data["Outlet_Size"].apply(lambda x: Outlet_Size[x]) 10 data["Outlet_Size"].replace({"Small":1,"Medium":2,"High":3},inplace = True) 11 #Outlet_Location_Type 12 Outlet_Location_Type = {'Tier 3':3, 'Tier 2':2, 'Tier 1':1} 13 data["Outlet_Location_Type"] = data["Outlet_Location_Type"].apply(lambda x: Outlet_Location_Type[x]) 14 #Outlet_Type 15 Outlet_Type = {'Supermarket Type1':1, 'Supermarket Type2':2, 'Supermarket Type3':3, 'Grocery Store':4,} 16 data["Outlet_Type"] = data["Outlet_Type"].apply(lambda x: Outlet_Type[x]) 17 except: 18 print("数值化已经完成过,切勿重复操作") 19 20 small_class_num(train_data) 21 small_class_num(test_data)
1 def item_type_num(data): 2 try: 3 data["Item_Type"].replace({"Fruits and Vegetables":"FD","Meat":"FD","Dairy":"FD","Breakfast":"FD"},inplace = True) 4 data["Item_Type"].replace({"Snack Foods":"FD","Frozen Foods":"FD","Canned":"FD"},inplace = True) 5 data["Item_Type"].replace({"Baking Goods":"FD","Breads":"FD","Canned":"FD","Seafood":"FD","Starchy Foods":"FD"},inplace = True) 6 data["Item_Type"].replace({"Household":"NC","Health and Hygiene":"NC","Others":"NC"},inplace = True) 7 data["Item_Type"].replace({"Soft Drinks":"DR","Hard Drinks":"DR",},inplace = True) 8 data["Item_Type"].value_counts() 9 data["Item_Type"].replace({"FD":1,"NC":2,"DR":3},inplace = True) 10 except: 11 print("数值化已经完成过,切勿重复操作") 12 item_type_num(train_data) 13 item_type_num(test_data)
1 train_data.isnull().sum()

缺失值处理
1 def Item_Weight_filna(data): 2 """ 3 根据商品ID填充,没有则填充平均值 4 """ 5 data[data.isnull().values==True] ##查看空行 6 Item_Weight_Missing = data[data["Item_Weight"].isnull()].index.tolist() 7 Item_Weight_Missing_ID = data["Item_Identifier"][Item_Weight_Missing].tolist() 8 data["Item_Weight"] = data["Item_Weight"].fillna(-1) 9 data_dict = data.groupby('Item_Identifier').Item_Weight.apply(list).to_dict() 10 for item in data_dict: 11 a = data_dict[item] 12 while -1.0 in a: 13 a.remove(-1.0) 14 b = [] 15 for item in Item_Weight_Missing_ID: 16 try: 17 b.append(data_dict[item][0]) 18 except: 19 b.append(data["Item_Weight"].mean()) 20 data["Item_Weight"][Item_Weight_Missing] = b 21 22 Item_Weight_filna(train_data) 23 Item_Weight_filna(test_data)
1 matrix = train_data.corr() #相关系数矩阵 2 f, ax = plt.subplots(figsize=(8, 8)) 3 sns.heatmap(matrix,vmax=.8, square=True,cmap="BuPu",annot=True)

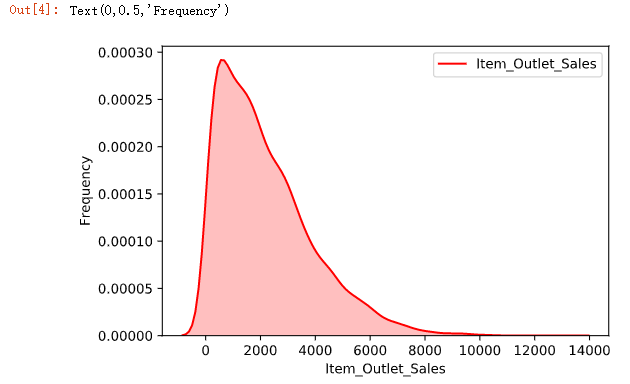
1 g = sns.kdeplot(train_data["Item_Outlet_Sales"], color="Red", shade = True) 2 g.set_xlabel("Item_Outlet_Sales") 3 g.set_ylabel("Frequency")
3.大数据分析过程及采用的算法
使用随机森林进行缺失值填充
1 from sklearn.ensemble import RandomForestClassifier 2 def Outlet_Size_filna(train_data): 3 """ 4 上述方法失效,使用随机森林进行填充 5 """ 6 try: 7 train_data["Outlet_Size"].fillna(-1,inplace=True) #填充缺失值 8 fc=RandomForestClassifier() 9 Outlet_Size_Miss = train_data.loc[train_data["Outlet_Size"] == -1] 10 Outlet_Size_Train = train_data.loc[train_data["Outlet_Size"] != -1] 11 Train_P = Outlet_Size_Train[["Outlet_Location_Type"]] 12 Train_L = Outlet_Size_Train["Outlet_Size"] 13 fc=RandomForestClassifier() 14 fc.fit(Train_P,Train_L) 15 c = Outlet_Size_Miss["Outlet_Location_Type"].values.reshape(-1,1) 16 d = fc.predict(c) 17 train_data.loc[train_data["Outlet_Size"]==-1,"Outlet_Size"] = d 18 except: 19 print("缺失值填充完毕,请勿重复操作!!!") 20 21 Outlet_Size_filna(train_data) 22 Outlet_Size_filna(test_data)
各个特征与结果的关系
1 def draw_feature_result(feature,x=10,y=4): 2 fig, (ax1, ax2) = plt.subplots(1,2, figsize=(x,y)) 3 sns.barplot(x = feature, y="Item_Outlet_Sales", data=train_data, ax=ax1) 4 5 feature_1 = train_data['Item_Outlet_Sales'].groupby(train_data[feature]).sum() 6 dict_feature_1 = {feature:feature_1.index,'Item_Outlet_Sales':feature_1.values} 7 dict_feature_1 = pd.DataFrame(dict_feature_1) 8 sns.barplot(x=feature, y="Item_Outlet_Sales", data=dict_feature_1, ax=ax2) 9 10 draw_feature_result("Item_Fat_Content")
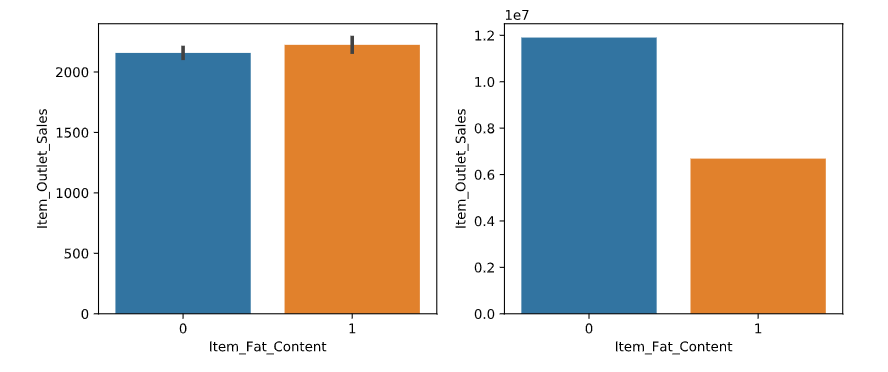
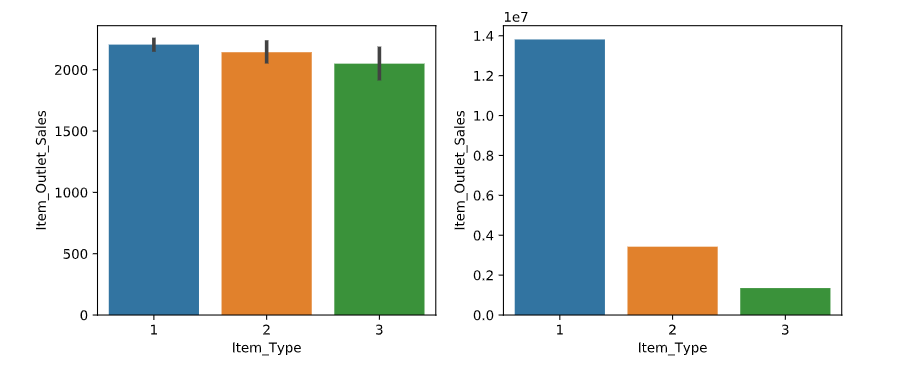
特征选择之商品种类和结果的关系:通过图表(如下图左)我们可以得出各个类型平均每一样物品的销售额差不多,但是不同类别的销售总额差别比较大(如下图右)。可以看出,食物类的商品销售总额最多,说明商品种类和销售金额是存在一定的关系的,故该特征保留。
1 draw_feature_result("Item_Type")
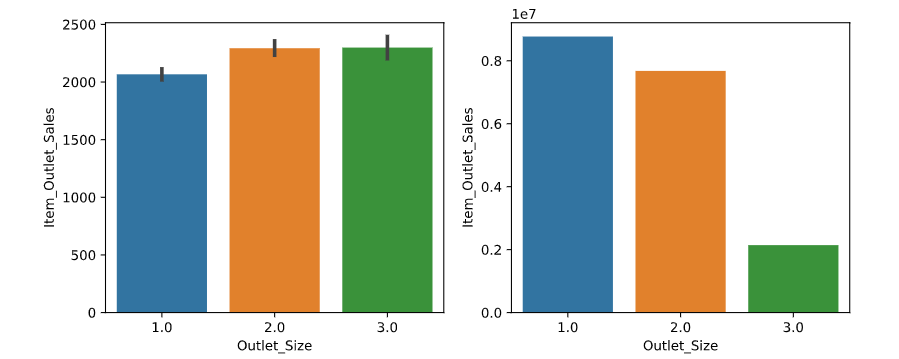
特征选择之商店大小和结果的关系:通过图表(如下图左)我们可以得出各个商店平均每一样物品的销售额差不多,但是不同大小的商店的销售总额差别比较大(如下图右)。可以看出,大超市销售总额最多,说明商店大小和销售金额是存在一定的关系的,故该特征保留。
1 draw_feature_result("Outlet_Size")
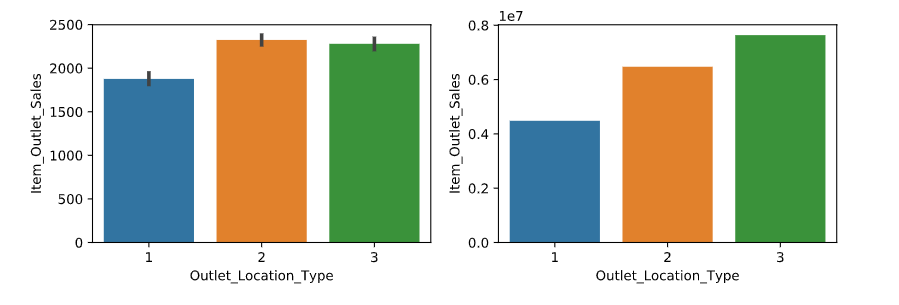
特征选择之商店所在地和结果的关系:通过图表(如下图左)我们可以得出各个地区商店平均每一样物品的销售额差不多,但是不同地区的商店的销售总额差别比较大(如下图右)。说明商店所在地和销售金额是存在一定的关系的,故该特征保留
1 draw_feature_result("Outlet_Location_Type",x=10,y=3)
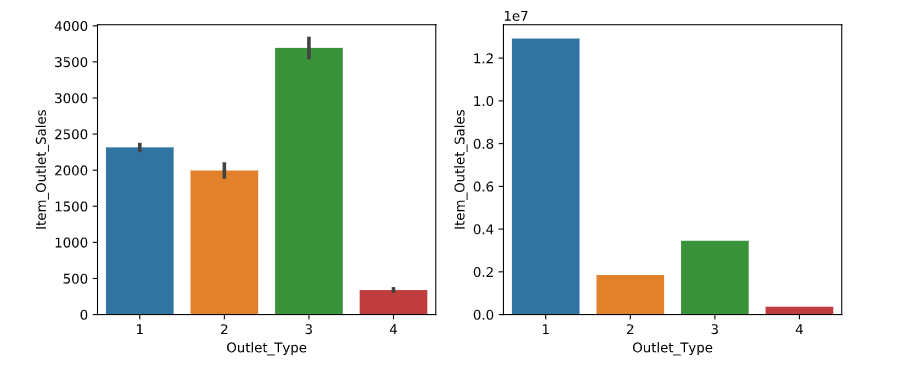
特征选择之商店类型和结果的关系:通过图表(如下图左)我们可以得出各个地区商店平均每一样物品的销售额相差比较大,不同地区的商店的销售总额差别也比较大(如下图右)。说明商店类型和销售金额是存在一定的关系的,故该特征保留
1 draw_feature_result("Outlet_Type")
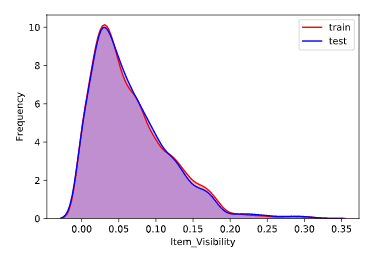
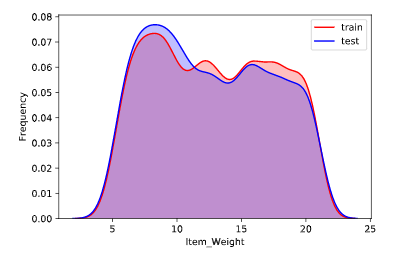
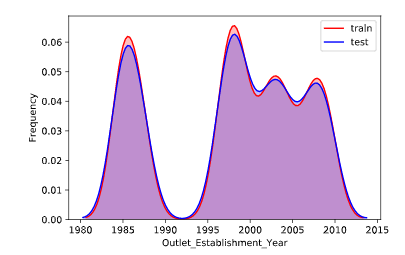
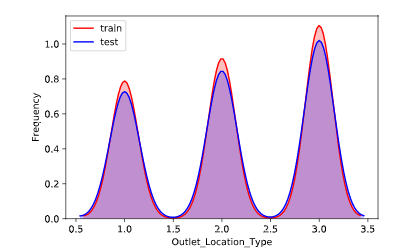
训练集特征分布规律和测试集特征分布规律对比
通过对比训练集和测试集的特征分布规律,我们可以看删除一些分布规律明显不同的特征,这里我们做了对比后发现,训练集和测试集特征的分布的规律几乎一致,所以不做特征的删除或选择工作。(分布规律如下图所示,横轴表示特征,纵轴表示频率)
1 train_data["oringin"]="train" 2 test_data["oringin"]="test" 3 all_data = pd.concat([train_data,test_data],axis=0,ignore_index=True) 4 target = all_data['Item_Outlet_Sales'] 5 del all_data["Item_Identifier"] 6 del all_data["Outlet_Identifier"] 7 del all_data["Item_Outlet_Sales"] 8 all_data["Item_Outlet_Sales"] = target
1 for column in all_data.columns[0:-2]: 2 g = sns.kdeplot(all_data[column][(all_data["oringin"] == "train")], color="Red", shade = True) 3 g = sns.kdeplot(all_data[column][(all_data["oringin"] == "test")], ax =g, color="Blue", shade= True) 4 g.set_xlabel(column) 5 g.set_ylabel("Frequency") 6 g = g.legend(["train","test"]) 7 # plt.savefig(column + "distri.svg") 8 plt.show()
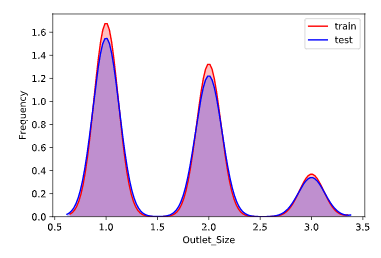
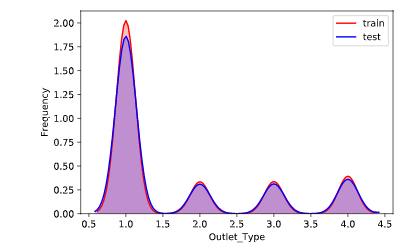
年份处理和浮点数标准化
1 all_data["Outlet_Establishment_Year"] = 2013 - all_data["Outlet_Establishment_Year"] 2 continus_value = ["Item_Weight", "Item_Visibility", "Item_MRP",] 3 def nornomalize(train_data,continus_value): 4 for vlaue in continus_value: 5 train_data[vlaue] = (train_data[vlaue] - train_data[vlaue].min()) / (train_data[vlaue].max() - train_data[vlaue].min()) 6 nornomalize(all_data,continus_value)
区分测试集和训练集
1 def get_training_data(): 2 """ 3 获取训练数据 4 """ 5 df_train = all_data[all_data["oringin"]=="train"] 6 y = df_train.Item_Outlet_Sales 7 X = df_train.drop(["oringin","Item_Outlet_Sales"],axis=1) 8 X_train,X_valid,y_train,y_valid=train_test_split(X,y,test_size=0.3,random_state=100) 9 return X_train,X_valid,y_train,y_valid 10 11 def get_test_data(): 12 """ 13 获取测试数据 14 """ 15 df_test = all_data[all_data["oringin"]=="test"].reset_index(drop=True) 16 return df_test.drop(["oringin","Item_Outlet_Sales"],axis=1)
评价标准rmse和mse,用make_scorer方便带入cv验证
1 def rmse(y_true, y_pred): 2 """ 3 评价标准1 4 """ 5 return sqrt(mean_squared_error(y_true, y_pred)) 6 7 8 def mse(y_ture,y_pred): 9 """ 10 评价标准2 11 """ 12 return mean_squared_error(y_ture,y_pred) 13 14 rmse_scorer = make_scorer(rmse, greater_is_better=False) 15 mse_scorer = make_scorer(mse, greater_is_better=False)
离群的检查
1 def find_outliers(model, X, y, sigma=3): 2 """ 3 根据模型找出异常点 4 model: 预测模型 5 X: 数据特征 6 y: 数据标签 7 sigma: 离群点阀值 8 """ 9 try: 10 y_pred = pd.Series(model.predict(X), index=y.index) 11 except: 12 model.fit(X,y) 13 y_pred = pd.Series(model.predict(X), index=y.index) 14 15 resid = y - y_pred # 计算结果差值 16 mean_resid = resid.mean() #结果差的均值 17 std_resid = resid.std() #结果的标准方差 18 19 z = (resid - mean_resid)/std_resid #标准化 20 outliers = z[abs(z)>sigma].index 21 22 print('rmse=',rmse(y, y_pred)) 23 print("mse=",mean_squared_error(y,y_pred)) 24 print('---------------------------------------') 25 26 print('mean of residuals:',mean_resid) 27 print('std of residuals:',std_resid) 28 print('---------------------------------------') 29 30 print(len(outliers),'outliers:') 31 print(outliers.tolist()) 32 33 plt.figure(figsize=(20,4)) 34 ax_131 = plt.subplot(1,3,1) 35 plt.plot(y,y_pred,'.') 36 plt.plot(y.loc[outliers],y_pred.loc[outliers],'ro') 37 plt.legend(['Accepted','Outlier']) 38 plt.xlabel('y') 39 plt.ylabel('y_pred'); 40 41 ax_132=plt.subplot(1,3,2) 42 plt.plot(y,y-y_pred,'.') 43 plt.plot(y.loc[outliers],y.loc[outliers]-y_pred.loc[outliers],'ro') 44 plt.legend(['Accepted','Outlier']) 45 plt.xlabel('y') 46 plt.ylabel('y - y_pred'); 47 48 ax_133=plt.subplot(1,3,3) 49 z.plot.hist(bins=50,ax=ax_133) 50 z.loc[outliers].plot.hist(color='r',bins=50,ax=ax_133) 51 plt.legend(['Accepted','Outlier']) 52 plt.xlabel('z') 53 54 plt.savefig('outliers.png') 55 56 return outliers
1 from sklearn.model_selection import train_test_split 2 X_train, X_valid,y_train,y_valid = get_training_data() 3 test=get_test_data() 4 outliers = find_outliers(GradientBoostingRegressor(), X_train, y_train)

交叉验证
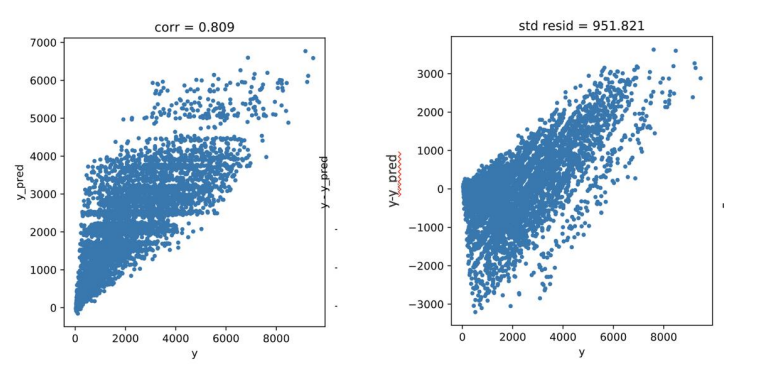
梯度提升算法建模预测结果梯度提升算法,采用网格搜索调参,10 次 10 折交叉验证得出最优的参数为n_estimators=70,max_depth =3, 训练集最好的 rmse = 951.7399 , 验证集测试的结果为 1078.8195 。(预测结果的相关系数如下图左所示,标准差如下图右所示)
1 from sklearn.preprocessing import StandardScaler 2 def train_model(model, param_grid=[], X=[], y=[], splits=5, repeats=5): 3 """ 4 使用K折交叉验证 5 6 """ 7 rkfold = RepeatedKFold(n_splits=splits, n_repeats=repeats) 8 9 gsearch = GridSearchCV(model, param_grid, cv=rkfold, scoring="neg_mean_squared_error", verbose=1, return_train_score=True) 10 gsearch.fit(X,y) 11 model = gsearch.best_estimator_ #选择最好的模型 12 best_idx = gsearch.best_index_ 13 14 grid_results = pd.DataFrame(gsearch.cv_results_) #CV模型 15 cv_mean = abs(grid_results.loc[best_idx,'mean_test_score']) 16 cv_std = grid_results.loc[best_idx,'std_test_score'] 17 cv_score = pd.Series({'mean':cv_mean,'std':cv_std}) 18 y_pred = model.predict(X) 19 print('----------------------') 20 print(model) 21 print('----------------------') 22 print('rmse=',rmse(y, y_pred)) 23 print('mse=',mse(y, y_pred)) 24 print('cross_val: mean=',cv_mean,', std=',cv_std) 25 26 y_pred = pd.Series(y_pred,index=y.index) 27 resid = y - y_pred 28 mean_resid = resid.mean() 29 std_resid = resid.std() 30 z = (resid - mean_resid)/std_resid 31 n_outliers = sum(abs(z)>3) 32 33 plt.figure(figsize=(20,4)) 34 ax_131 = plt.subplot(1,3,1) 35 plt.plot(y,y_pred,'.') 36 plt.xlabel('y') 37 plt.ylabel('y_pred'); 38 plt.title('corr = {:.3f}'.format(np.corrcoef(y,y_pred)[0][1])) #相关系数 39 ax_132=plt.subplot(1,3,2) 40 plt.plot(y,y-y_pred,'.') 41 plt.xlabel('y') 42 plt.ylabel('y - y_pred'); 43 plt.title('std resid = {:.3f}'.format(std_resid)) 44 45 ax_133=plt.subplot(1,3,3) 46 z.plot.hist(bins=50,ax=ax_133) 47 plt.xlabel('z') 48 plt.title('{:.0f} samples are outliers'.format(n_outliers)) 49 50 return model, cv_score, grid_results

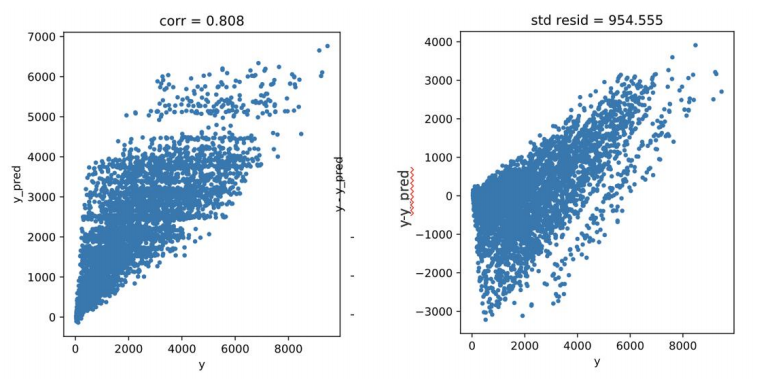
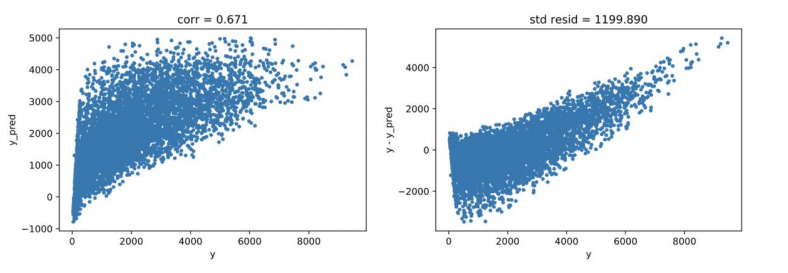
Xgboost 算法,采用网格搜索调参,10 次 10 折交叉验证得出最优的参数为n_estimators=70,max_depth =3, 训练集最好的 rmse = 954.4746 , 验证集测试的结果为 1077.1127 。(预测结果的相关系数如下图左所示,标准差如下图右所示)
1 from xgboost import XGBRegressor 2 param_grid_xg = {'n_estimators': [70, 75, 80],'max_depth': [1, 2, 3]} # xgboost 3 model_xg, cv_score_xg, grid_results_xg = train_model(XGBRegressor(), param_grid_xg, X1, y1, splits=10, repeats=10) 4 submit_xg = model_xg.predict(get_test_data())
岭回归 Ridge 算法建模预测结果
1 alph_range = np.arange(0.25,6,0.25) # 岭回归 2 param_grid_ridge = {'alpha': alph_range} 3 model_ridge, cv_score_ridge, grid_results_ridge = train_model( Ridge(), param_grid_ridge, X1, y1, splits=10, repeats=10) 4 submit_ridge = model_ridge.predict(get_test_data())
1 final_1 = 0.4*(submit_xg+submit_gbdt)+ 0.1*(submit_ridge+ submit_rf) # 1162.9265 2 final_2 = 0.5*submit_xg + 0.3 * submit_gbdt + 0.1 * submit_ridge + 0.1 * submit_rf # 1162.6200 3 final_3 = 0.8*submit_xg + 0.1 * submit_gbdt + 0.05 * submit_ridge + 0.05 * submit_rf # 1157.9485 4 final_4 = 0.2*submit_xg + 0.6 * submit_gbdt + 0.1 * submit_ridge + 0.1 * submit_rf # 1163.5908 5 final_5 = 0.8*submit_xg + 0.1 * submit_ridge + 0.1 * submit_rf # 1161.8037 6 final_6 = 0.8*submit_xg + 0.2 * submit_gbdt # 1155.1319 7 final_7 = 0.9*submit_xg + 0.1 * submit_gbdt # 1154.9201
1 def result_submit(filename, submit): 2 """ 3 func: 结果提交函数 4 """ 5 df = pd.read_csv(filename) 6 df["Item_Outlet_Sales"] = submit 7 df.to_csv("1.csv", index=False) 8 9 10 result_submit("SampleSubmission_TmnO39y.csv", final_7)
四、总结
1.有益的结论:
(1)商品销售额与各种因素有关,比如说商店位置等
(2)特征分析很重要,好的特征能提高准确率
(3)模型选择很重要,模型的集成往往能带来更好的结果
达到了预期的目标
2.通过完成此设计过程中,我收获了,数值的替换都可以用replace,数据分析常用模块有三个:numpy:矩阵计算等数学计算,pandas:基于numpy的数据分析工具,使用数据框对表结构的数据进行分析,matplotlib:数据可视化,本次课程主要学习前两者。numpy一维数组与列表的区别:一维数组提供了很多统计功能,一维数组可以向量化运算,一维数组全是相同的数据类型。pandas的Series有index,我们可以在使用的时候指定这些index。iloc根据位置获取元素的值,loc方法根据index索引值获取元素的值。querySer筛选这里要仔细理解,涉及到行和列的变化。要理解【行,列】这里的控制变量的问题,前面是对于行的筛选,后面是对于列的筛选。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号