
字符串、文件操作,英文词率统计预处理
该作业要求来于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/2646
1.字符串操作:
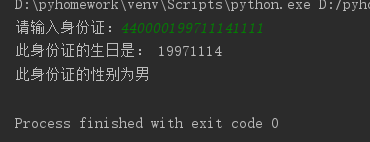
- 解析身份证号:生日、性别、出生地等。
 View Code
View Code1 idcard = input('请输入身份证:') 2 if len(idcard) == 18: 3 birth = idcard[6:14] 4 print('此身份证的生日是:',format(birth)) 5 sex = idcard[14:17] 6 if int(sex) % 2 ==0: 7 print('此身份证的性别为女') 8 else: 9 print('此身份证的性别为男') 10 else: 11 print('您输入的身份证有误')
- 凯撒密码编码与解码
View Codedef encryption(): str_raw = input("请输入明文:") k = int(input("请输入位移值:")) str_change = str_raw.lower() str_list = list(str_change) str_list_encry = str_list i = 0 while i < len(str_list): if ord(str_list[i]) < 123-k: str_list_encry[i] = chr(ord(str_list[i]) + k) else: str_list_encry[i] = chr(ord(str_list[i]) + k - 26) i = i+1 print ("加密结果为:"+"".join(str_list_encry)) def decryption(): str_raw = input("请输入密文:") k = int(input("请输入位移值:")) str_change = str_raw.lower() str_list = list(str_change) str_list_decry = str_list i = 0 while i < len(str_list): if ord(str_list[i]) >= 97+k: str_list_decry[i] = chr(ord(str_list[i]) - k) else: str_list_decry[i] = chr(ord(str_list[i]) + 26 - k) i = i+1 print ("解密结果为:"+"".join(str_list_decry)) while True: print (u"1. 加密") print (u"2. 解密") choice = input("请选择:") if choice == "1": encryption() elif choice == "2": decryption() else: print (u"您的输入有误!")

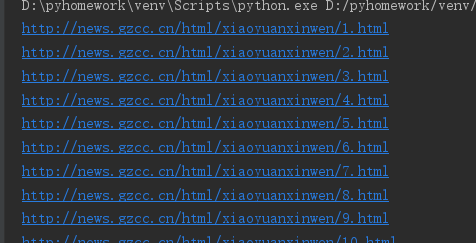
- 网址观察与批量生成
View Codefor i in range(1,20): url='http://news.gzcc.cn/html/xiaoyuanxinwen/{}.html'.format(i) print(url)

2.英文词频统计预处理
- 下载一首英文的歌词或文章或小说,保存为utf8文件。
- 从文件读出字符串。
- 将所有大写转换为小写
- 将所有其他做分隔符(,.?!)替换为空格
- 分隔出一个一个的单词
- 并统计单词出现的次数。
View Codef = open(r'D:\pyhomework\bigbigword.txt',encoding='utf8') sep = ',./<>?`-_=+' text = f.read() print(text) f.close() text = text.lower() for i in sep: text = text.replace(i,' ') print(text.split()) print(text.count('big'),text.count('world'))

