数据库设计
1 mysql数据库建模过程
需求分析阶段:分析客户的业务和数据处理需求
概要设计阶段:设计数据库的E-R模型图,确认需求信息的正确和完整
详细设计阶段:应用三大范式审核数据库结构
代码编写阶段:物理实现数据库,编码实现应用
软件测试阶段:……
安装部署:……
2 设计数据库的步骤
1)了解需求
与该系统有关人员进行交流、座谈,充分了解用户需求,理解数据库需要完成的任务
2)标识实体 (entity)
标识数据库要管理的关键对象或实体(名词)
3)标识每个实体的属性(attribute)(名词)
4)标识实体之间的关系(relationship)(动词)
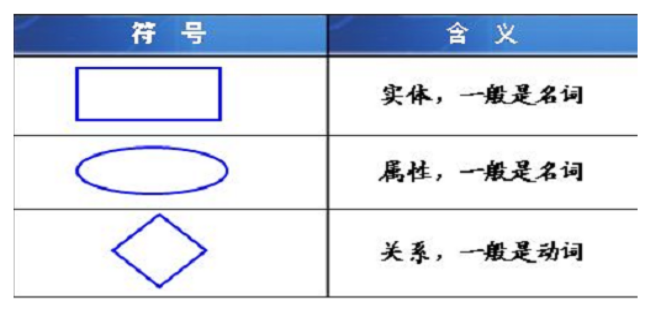
tips:在E-R图中,实体用矩形表示,属性用椭圆表示,关系用菱形表示
3 E-R图设计
3.1映射基数
1)一对一:X中的一个实体最对与Y中的一个实体关联,
并且Y中的一个实体最多与X中的一个实体关联.
例:一个人只有一张身份证.
2)一对多:X中的一个实体可以与Y中的任意数量的实体关联;
Y中的一个实体最多与X中的一个实体关联.
例:一个班级有多名学生.
3)多对多:X中的一个实体可以与Y中的任意数量的实体关联,反之亦然.
例:学生和课程之间的关系,一个学生可以有多门课程,一门课程可以对应多名学生.
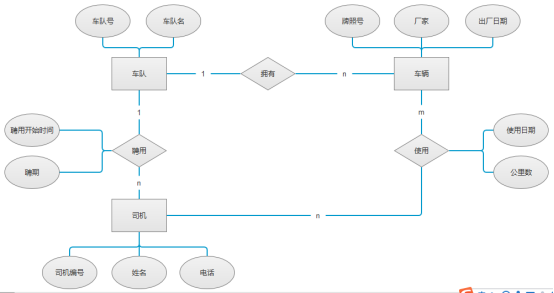
例1:
某大学实现学分制,学生可根据自己情况选课。每名学生可同时选修多门课程,每门课程可由多位教师主讲;每位教师可讲授多门课程。

例2:
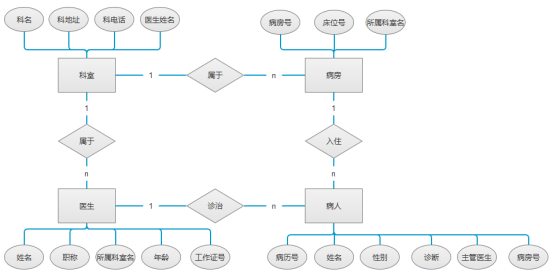
某医院病房计算机管理中心需要如下信息:
科室:科名、科地址、科电话、医生姓名
病房:病房号、床位号、所属科室名
医生:姓名、职称、所属科室名、年龄、工作证号
病人:病历号、姓名、性别、诊断、主管医生、病房号
其中,一个病房只能属于一个科室,一个科室可以有多个病房,一个医生只属于一个科室,一个科室可以有多名医生,一个医生可负责多个病人的诊治,一个病人的主管医生只有一个。一个病人只能住一间病房,一间病房可以入住多名病人。
3.2表设计(重要)
1)如果是1:1的关系:那么将实体转换成表,将任意1端实体的主键拿到另一端实体做外键。
2)如果是1:n的关系:那么将实体转换成表,关系不成表,将1端实体的主键拿到n端实体做外键。
3)如果是m:n的关系:将实体转换成表,关系形成表,同时将两端实体的主键拿过来作为该表的外键,形成复合主键。
例:
上面医院的图的建表:
create table h_office(
oid int primary key,
oname varchar(20),
ophone varchar(20),
oadds varchar(50)
);
create table h_room(
rid varchar(10) primary key,
bedid varchar(10),
oid int
);
alter table h_room add constraint room_office_fk foreign key(oid) references h_office(oid);
create table h_doctor(
did int primary key,
dname varchar(10),
prof varchar(20),
age int,
number varchar(20),
oid int
);
alter table h_doctor add constraint doctor_office_fk foreign key(oid) references h_office(oid);
create table h_patient(
pid varchar(10) primary key,
pname varchar(10),
psex varchar(10),
pinfo varchar(100),
did int,
rid varchar(10)
);
alter table h_patient add constraint patient_doctor_fk foreign key(did) references h_doctor(did);
alter table h_patient add constraint prtient_room_fk foreign key(rid) references h_room(rid);
4 数据库设计三大范式
为了建立冗余较小、结构合理的数据库,设计数据库时必须遵循一定的规则。在关系型数据库中这种规则就称为范式。范式是符合某一种设计要求的总结。要想设计一个结构合理的关系型数据库,必须满足一定的范式。
1)第一范式:确保每列保持原子性
要求表的每个字段必须是不可分割的独立单元
例:
student : name --违反第一范式
张小名 | 娃娃
sutdent : name old_name --符合第一范式
张小名 娃娃
第一范式是最基本的范式。如果数据库表中的所有字段值都是不可分解的原子值,就说明该数据库表满足了第一范式。
第一范式的合理遵循需要根据系统的实际需求来定。
比如某些数据库系统中需要用到“地址”这个属性,本来直接将“地址”属性设计成一个数据库表的字段就行。
但是如果系统经常会访问“地址”属性中的“城市”部分,那么就非要将“地址”这个属性重新拆分为省份、城市、详细地址等多个部分进行存储,这样在对地址中某一部分操作的时候将非常方便。
这样设计才算满足了数据库的第一范式。
2)第二范式:确保表中的每列都和主键相关
在第一范式的基础上,要求每张表只表达一个意思。表的每个字段都和表的主键有依赖。
例:
employee(员工):
员工编号 员工姓名 订单名称
--违反第二范式,订单名称和员工编号没关系
修改:
员工表:员工编号 员工姓名
订单表:订单编号 订单名称 -- 符合第二范式
第二范式在第一范式的基础之上更进一层。
第二范式需要确保数据库表中的每一列都和主键相关,而不能只与主键的某一部分相关(主要针对联合主键而言)。
也就是说在一个数据库表中,一个表中只能保存一种数据,不可以把多种数据保存在同一张数据库表中。
例:
设计一个订单信息表,因为订单中可能会有多种商品,所以要将订单编号和商品编号作为数据库表的联合主键,如下表所示。
订单信息表
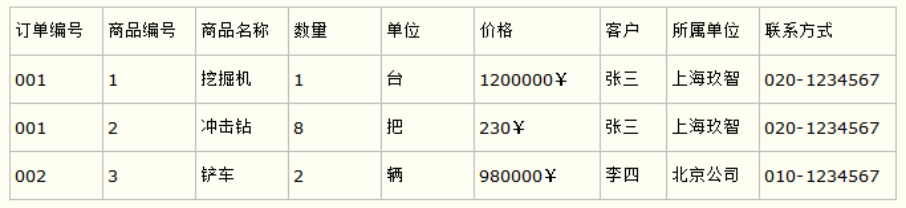
这个表中是以订单编号和商品编号作为联合主键。这样在该表中商品名称、单位、商品价格等信息不与该表的主键相关,而仅仅是与商品编号相关。所以在这里违反了第二范式的设计原则。
修改:
把这个订单信息表进行拆分,把商品信息分离到另一个表中,把订单项目表也分离到另一个表中,就非常完美了。如下所示。

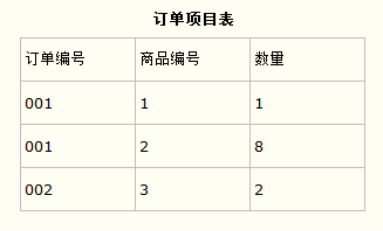
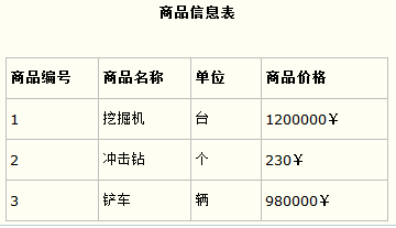
这样设计,在很大程度上减小了数据库的冗余。如果要获取订单的商品信息,使用商品编号到商品信息表中查询即可。
3)第三范式:确保每列都和主键列直接相关,而不是间接相关
例1:
员工表: 员工编号(主键) 员工姓名 部门编号 部门名
--符合第二范式,违反第三范式 (数据冗余高)
员工表:员工编号(主键) 员工姓名 部门编号
--符合第三范式(降低数据冗余)
部门表:部门编号 部门名
例2:
设计一个订单数据表,可以将客户编号作为一个外键和订单表建立相应的关系。而不可以在订单表中添加关于客户其它信息(比如姓名、所属公司等)的字段。如下面这两个表所示的设计就是一个满足第三范式的数据库表。
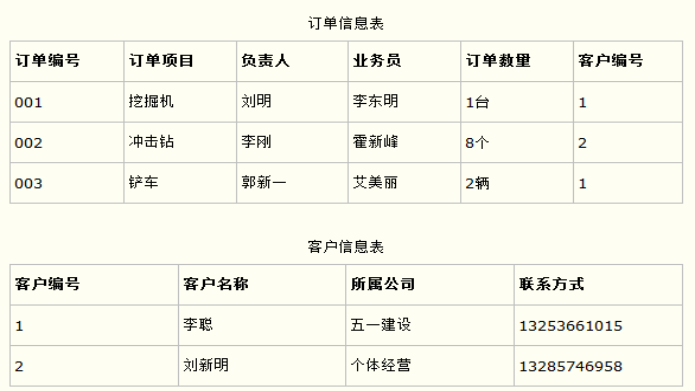
这样在查询订单信息的时候,就可以使用客户编号来引用客户信息表中的记录,也不必在订单信息表中多次输入客户信息的内容,减小了数据冗余。
三大范式总结:不可再分,每一列都和主键相关,可以出现外键
5 数据库设计总结:
1)为满足某种商业目标,数据库性能比规范化数据库更重要
通过在给定的表中添加额外的字段,以大量减少需要从中搜索信息所需的时间。
通过在给定的表中插入计算列(如成绩总分),以方便查询。
2)在数据规范化同时,要综合考虑数据库的性能
6 练习

解答:
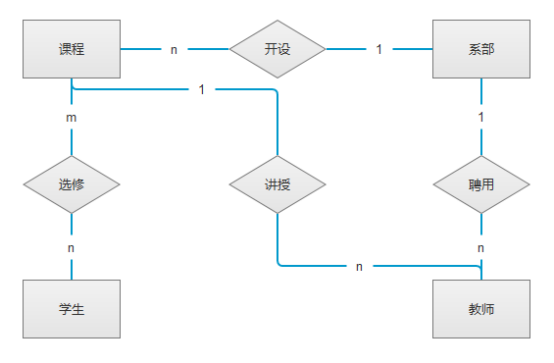


解答: